Quality & Accuracy Properties
Built-in properties that measure whether your LLM output correctly and fully addresses the input - relevance, completeness, instruction fulfillment, and more.
These properties answer the core question: did the output correctly and fully address the input? They measure task-level quality - whether the model was relevant, complete, accurate relative to a reference, and whether it followed the instructions it was given.
Relevance
The Relevance property measures how relevant the LLM output is to the input, ranging from 0 (not relevant) to 1 (very relevant). It is useful mainly for evaluating use cases such as Question Answering, where the LLM is expected to answer given questions.
The property is calculated by passing the user input and the LLM output to a model trained on the GLUE QNLI dataset. Unlike the Grounded in Context property, which compares the LLM output to the provided context, the Relevance property compares the LLM output to the user input given to the LLM.
Examples
| LLM Input | LLM Output | Relevance |
|---|---|---|
| What is the color of the sky? | The sky is blue | 0.99 |
| What is the color of the sky? | The sky is red | 0.99 |
| What is the color of the sky? | The sky is pretty | 0 |
Expected Output Similarity
The Expected Output Similarity metric assesses the similarity of a generated output to a reference output, providing a direct evaluation of accuracy against a ground truth. This metric, scored from 1 to 5, determines whether the generated output includes the main arguments of the reference output.
Several LLM judges break both the generated and reference outputs into self-contained propositions, evaluating the precision and recall of the generated content. The judges' evaluations are then aggregated into a unified score.
This property is evaluated only if an expected_output is supplied - it provides an additional metric alongside Deepchecks' intrinsic evaluation.
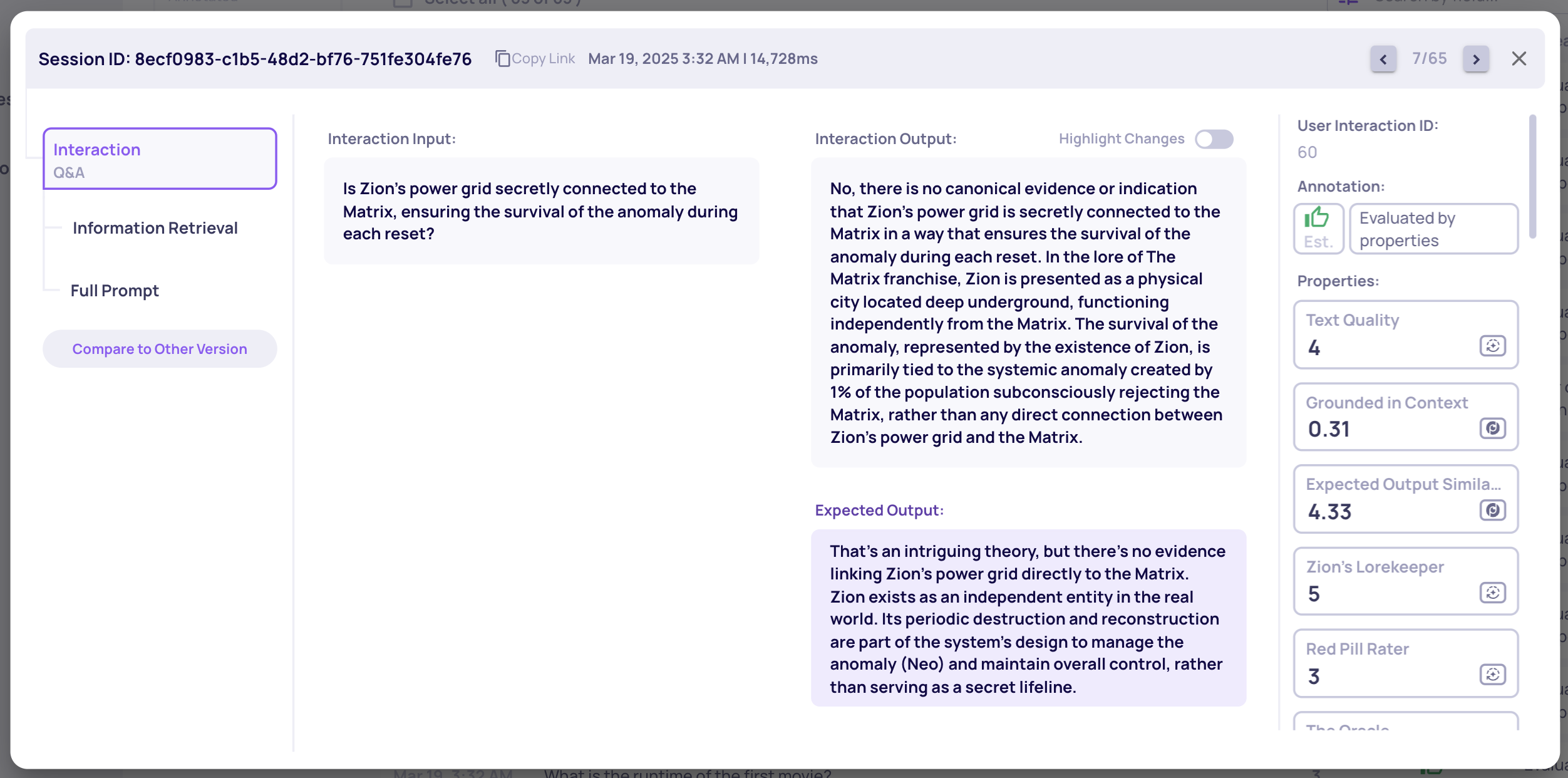
Expected Output in Deepchecks
This property uses LLM calls for calculation.
Examples
| Output | Expected Output | Score |
|---|---|---|
| Many fans regard Payton Pritchard as the GOAT because of his clutch plays and exceptional shooting skills. | Payton Pritchard is considered by some fans as the greatest of all time (GOAT) due to his clutch performances and incredible shooting ability. | 5.0 |
| Payton Pritchard is a solid role player for the Boston Celtics but is not in the conversation for being the GOAT. | Payton Pritchard is considered by some fans as the greatest of all time (GOAT) due to his clutch performances and incredible shooting ability. | 1.0 |
Handling low scores
Low Expected Output Similarity scores indicate minimal overlap between generated outputs and reference ground truth outputs. Common approaches:
- Multiple valid solutions - Especially for Generation tasks, various outputs may correctly fulfill the instructions. Evaluate whether strict adherence to reference outputs is necessary.
- Prompt adjustment - Identify pattern differences between generated and reference outputs, then modify prompts to guide the model toward reference-like responses. Use Version Comparison to iteratively refine.
- In-context learning - Provide the model with example input-output pairs to demonstrate expected behavior (few-shot prompting).
- Fine-tuning - Consider this more resource-intensive option only when other approaches prove insufficient.
Completeness
The Completeness property evaluates whether the output fully addresses all components of the original request, providing a comprehensive solution. An output is considered complete if it eliminates the need for follow-up questions. Scoring ranges from 1 to 5, with 1 indicating low completeness and 5 indicating a thorough and comprehensive response.
This property uses LLM calls for calculation.
Intent Fulfillment
The Intent Fulfillment property is closely related to Completeness, but is specifically designed for multi-turn settings like chat. It evaluates how accurately the output follows the instructions provided by the user, and also reviews the entire conversation history to identify any previous user instructions that remain relevant to the current turn.
Scoring ranges from 1 to 5, with 1 indicating low adherence to user instructions and 5 representing precise and thorough fulfillment.
This property is calculated using LLM calls.
Instruction Fulfillment
The Instruction Fulfillment property assesses how accurately the output adheres to the specified instructions or requirements in the input. It is especially valuable for evaluating how effectively an AI assistant follows system instructions in multi-turn scenarios, such as a tool-using chatbot.
Scoring ranges from 1 to 5, where 1 indicates low adherence and 5 signifies precise and thorough alignment with the provided guidelines.
This property uses LLM calls for calculation.
Handling low Completeness / Instruction Fulfillment scores
Low scores often result from application design and architectural choices. Common mitigation strategies:
- Simplicity - LLMs perform better when complex tasks are broken down into simpler steps. Defining a series of simpler tasks can significantly enhance performance.
- Explicitness - Ensure all instructions are explicitly stated. Avoid implicit requirements and clearly specify expectations.
- Model choice - Some models are better at instruction following than others. Experiment with different models to find a cost-effective solution for your use case.
Coverage
Coverage measures how effectively a language model preserves essential information when generating summaries or condensed outputs. The Coverage Score quantifies how comprehensively the output captures the key topics in the input text, scored from 0 (low coverage) to 1 (high coverage).
A low score means the summary covers a low ratio of the main topics in the input text.
This property uses LLM calls for calculation.
Examples
LLM Input | LLM Output | Coverage | Uncovered Information |
|---|---|---|---|
The Renaissance began in Italy during the 14th century and lasted until the 17th century. It was marked by renewed interest in classical art and learning, scientific discoveries, and technological innovations. | The Renaissance was a cultural movement in Italy from the 14th to 17th centuries, featuring revival of classical learning. | 0.7 |
|
Our story deals with a bright young man, living in a wooden cabin in the mountains. He wanted nothing but reading books and bathe in the wind. | The young man lives in the mountains and reads books. | 0.3 |
|
Handling low scores
- Prompting - Explicitly instruct the model to extract and summarize the most important details. Adjust the balance between Coverage and Conciseness.
- Model choice - Some models are better suited for accurately identifying and summarizing key arguments. Deepchecks also provides a Conciseness property to ensure improvements in Coverage don't come at the expense of brevity.