Working with LLM Features - Deepchecks on SageMaker
Learn how to optimize Deepchecks’ LLM features on SageMaker, including model selection and processing speed, to balance cost, capacity, and reliability.
Key Things to Know About LLM Features in Deepchecks on SageMaker
Many of the most valuable features in Deepchecks are powered by LLMs. This includes our research-backed LLM-based properties, which serve as the foundation for other key capabilities such as auto-annotations.
In our SaaS offering, Deepchecks manages the models and connections behind the scenes. We take care of model maintenance, scaling, and capacity management - so users don’t encounter issues like rate limits or availability bottlenecks.
On SageMaker, things work differently. Here, you use your own Bedrock models and profiles instead of Deepchecks-managed ones. This means the features are built and provided by us, but the models themselves are yours. As a result, there is a greater theoretical chance of rate limits or model-related issues depending on your configuration.
To account for this, we’ve introduced a few changes in the SageMaker offer of Deepchecks. These adjustments ensure that all LLM-based features continue to work reliably, while reducing the likelihood of issues that might arise from using your own models.
Model Choice for LLM Features
In the Deepchecks app, LLM-powered functionality is split into two groups of features:
- Basic LLM features → These run frequently and can work well with a “weaker” lower-cost model. The key requirement is high capacity, since these features are triggered often.
- Advanced LLM features → These are more LLM-intensive and require stronger models to deliver high-quality results. For these features, you should assign a more capable model, while also making sure it has enough available capacity to avoid slowdowns or failures.
We divided the features into these two groups so that you can:
- Balance costs by using cost-effective models where possible.
- Avoid exhausting capacity on a single model, which could lead to performance issues.
How to Choose Models
You can configure which models are assigned to each group directly in the app:
- Go to Workspace Settings.
- Open the Preferences tab.
- Choose models from the two dropdowns provided.
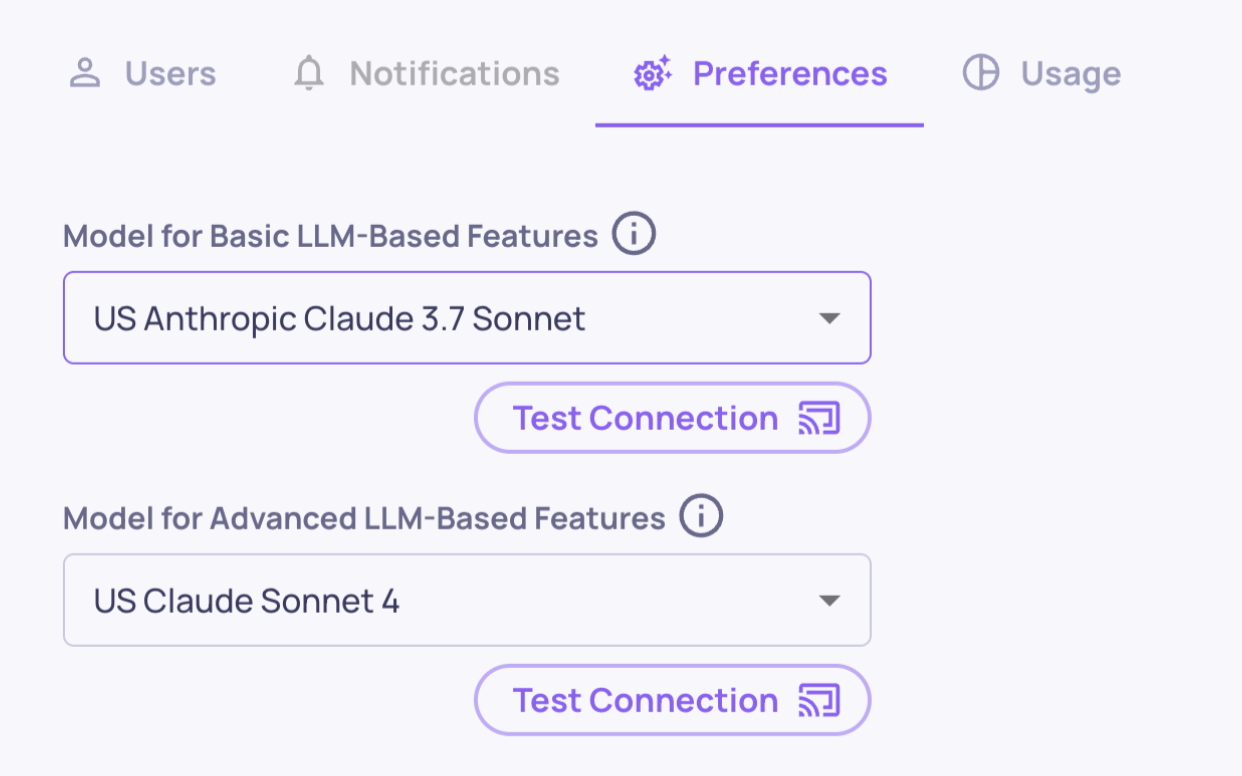
Model configuration on the Preferences tab
Using the same model for both groupsYou can technically assign the same model to both groups, but this is not recommended since it increases the chance of hitting rate limits.
Default Setup
When you first start using Deepchecks on SageMaker, the default selection for both dropdowns will be randomly chosen from your deployed models. For this reason, we strongly recommend configuring the model assignments before running evaluations.
Model ConfigurationIn Deepchecks on SageMaker, the models available to you will be those you configured during Deepchecks deployment on the SageMaker UI. You can always add more models via that same service, our via Deepchecks' "Manage Models" flow.
Configuring Processing Speed
In our SaaS offering, Deepchecks manages the LLM profiles and models. Because we ensure sufficient capacity, interactions are processed with minimal waiting time between them (for example, during LLM-based property calculations).
On SageMaker, things work differently: since you provide and manage the models, their capacity depends on your setup. To give you flexibility, Deepchecks on SageMaker includes a configurable Processing Mode setting, which lets admins balance speed against reliability in the face of potential rate limits.
Processing Mode Options
You can choose from three options in your Preferences tab (under Workspace Settings):
- High (Recommended)
- Processes data quickly with minimal waiting.
- Best for most use cases.
- If you encounter rate limits, we suggest requesting more capacity for your model rather than changing this setting.
- Balanced
- A middle ground between speed and safety.
- Adds moderate waiting and processes in smaller batches.
- Use only if you occasionally hit rate limits and cannot increase capacity.
- Low
- Processes in smaller batches with waiting between them to ease API pressure.
- Useful only if you hit rate limits often and cannot increase capacity.
- Not recommended as a default setting.

Processing speed configuration on the Preferences tab
When to Use This
This flexibility is especially useful if you want to use a high-quality but lower-capacity model. By lowering the processing speed, you can reduce the chance of rate limits interfering with evaluations.
However, we generally recommend choosing models with larger capacities and keeping Processing Mode set to Recommended (the default). This ensures you get the fastest and most valuable evaluation experience from Deepchecks.
Updated 3 months ago