Identify Problems Using Properties, Estimated Annotations and Insights
Find Problematic Samples based on Built-in Properties
In this section we'll identify problematic behaviors in our evaluation sets using a few of Deepchecks’ Built-in calculated properties: "Grounded in Context" and "Retrieval Coverage".
In addition, we'll have a look at the "Avoided Answer" property as well, as it is sometimes related to problematic findings, and thus filtering and sorting using this property can help pinpoint undesired outputs in our application.
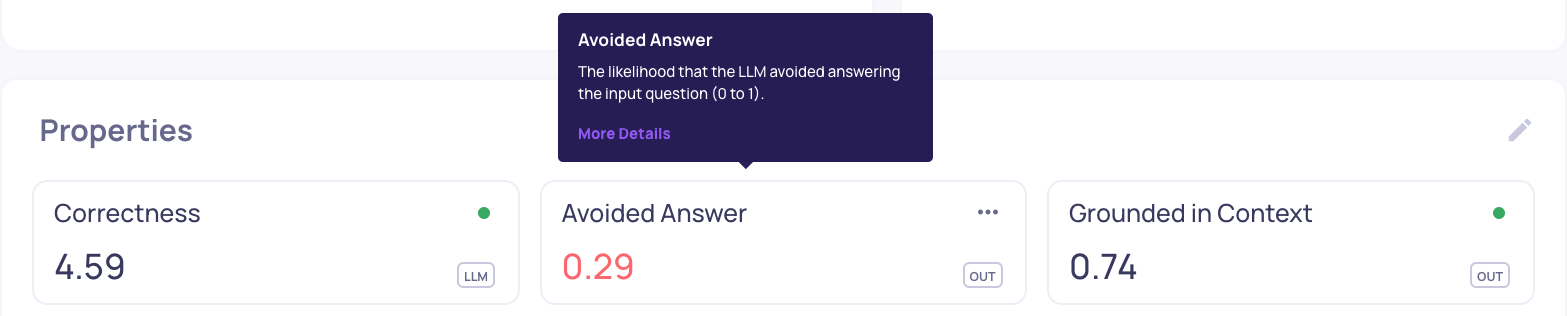
More info about each of these properties can be seen upon hovering on the property in the UI:
To explore bad behaviors in our Evaluation set, follow these steps:
-
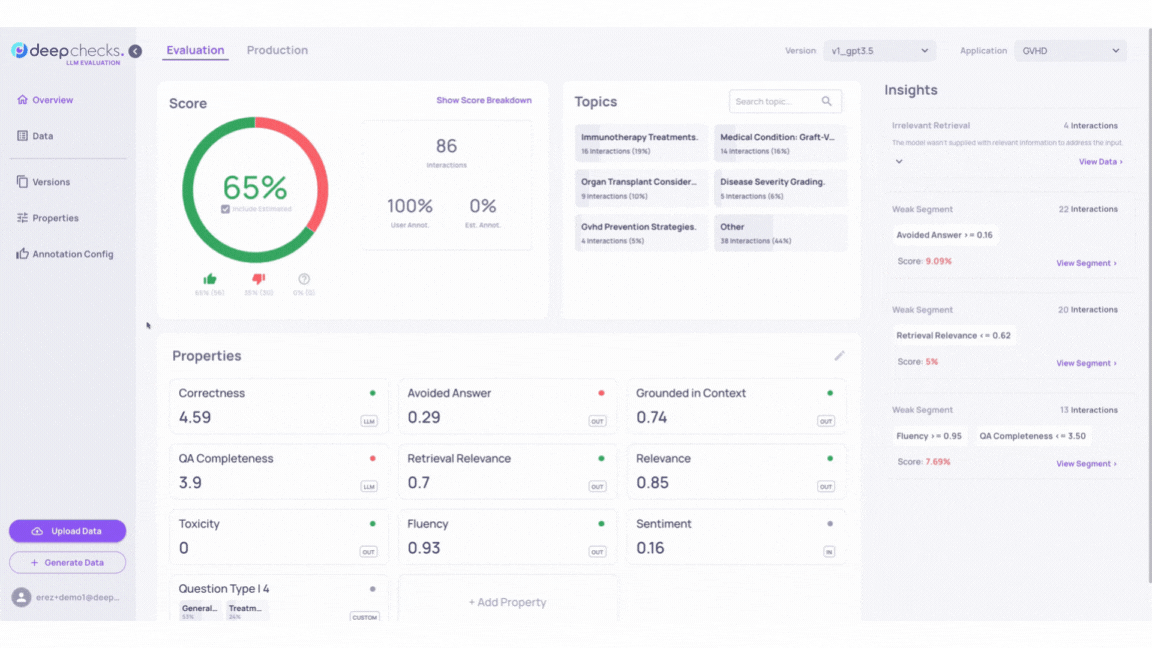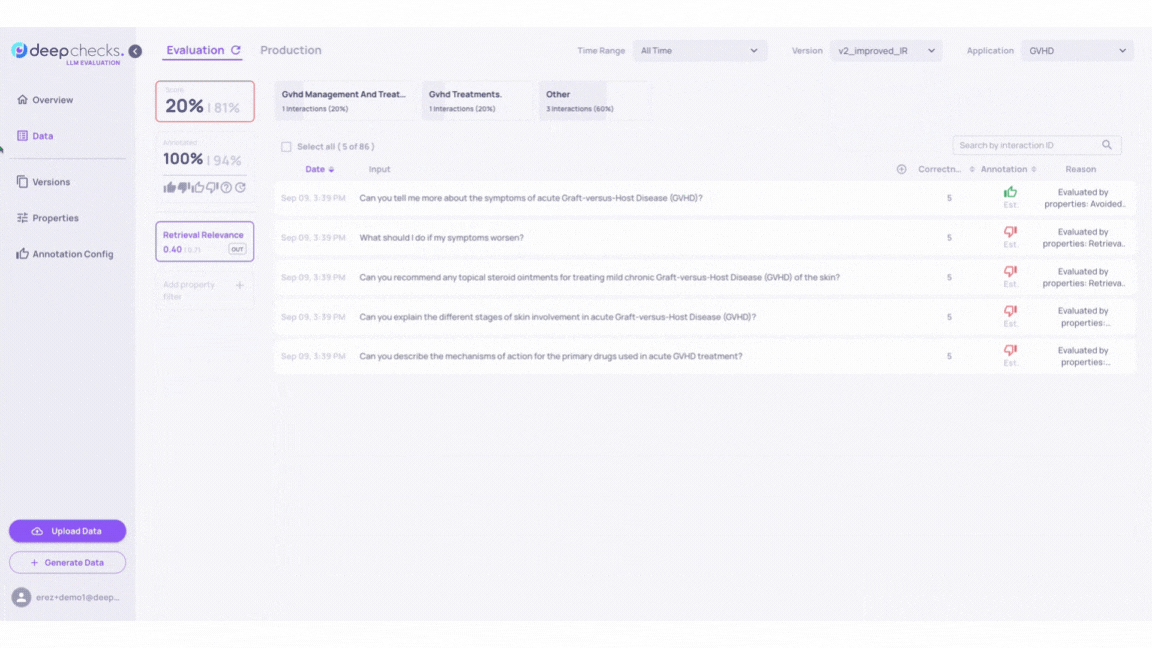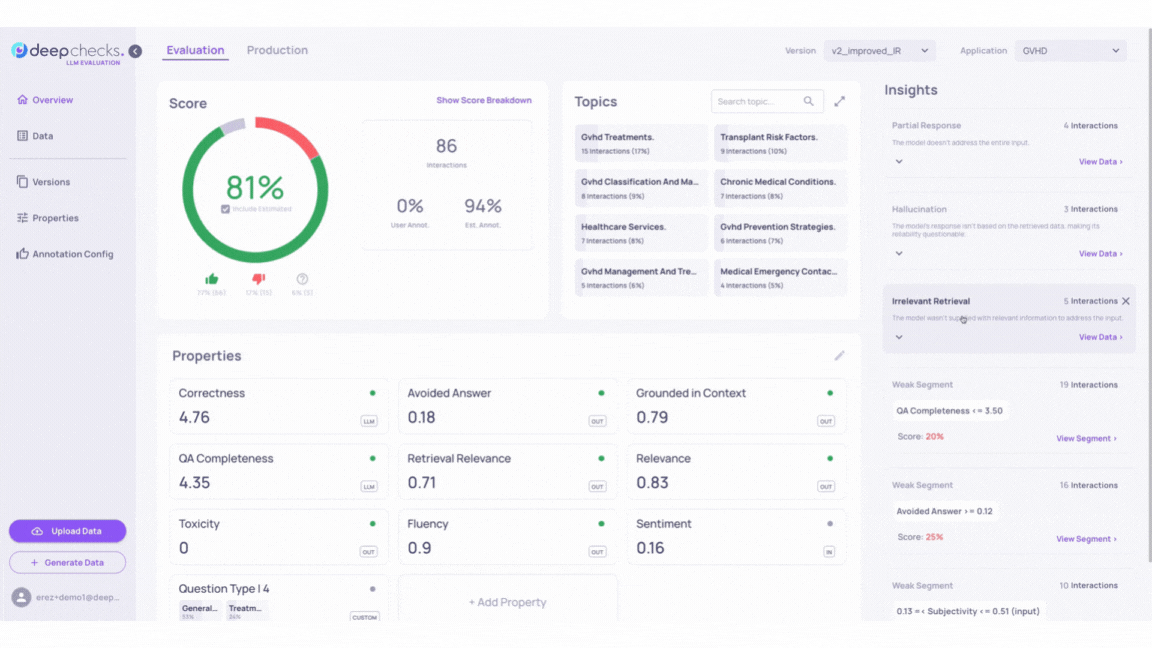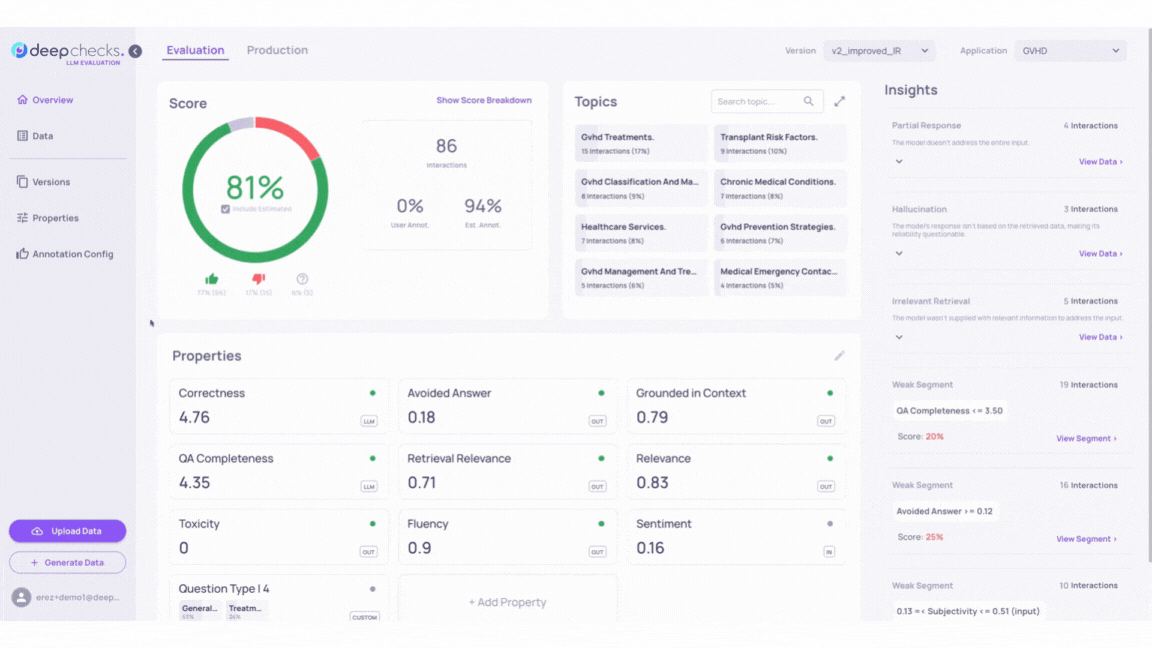
Go to the Interactions page in version v1, and sort according to "bad" and "estimated bad". This can be done by selecting the thumbs down filters on the left side of the page.
Notice we have a user supplied annotation reason for each sample that was annotated “bad”. The User Reason can help us highlight the major factors we gave a specific sample its annotation.
-
Click on the property column and choose the "Grounded in Context" property. Sort the interactions from low to high.
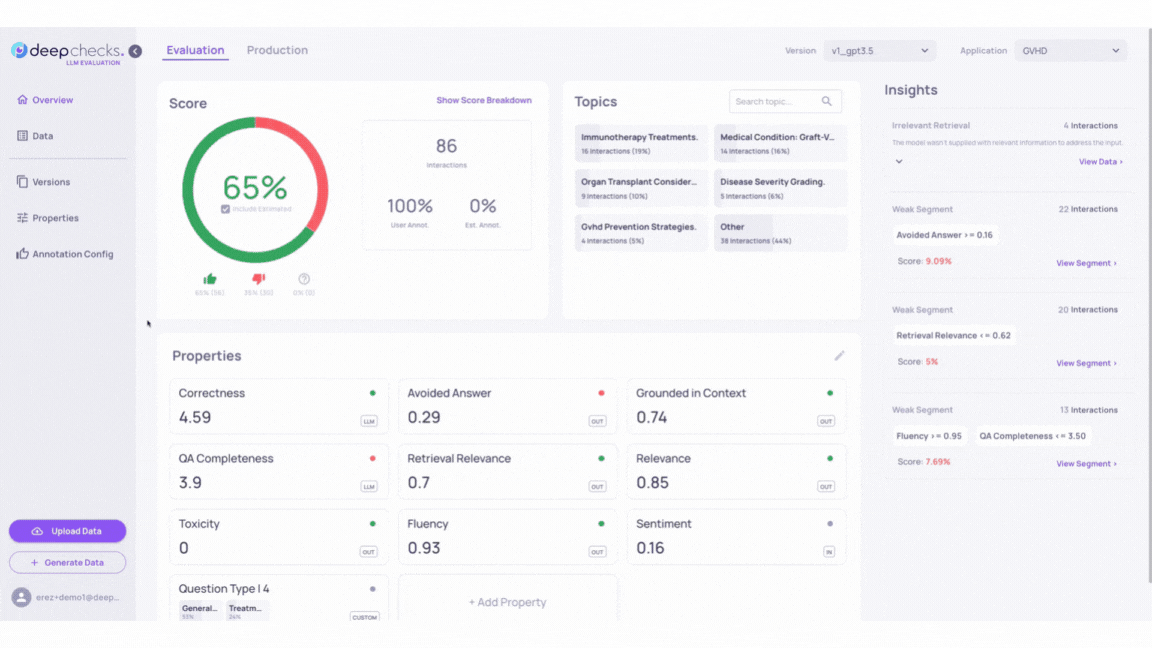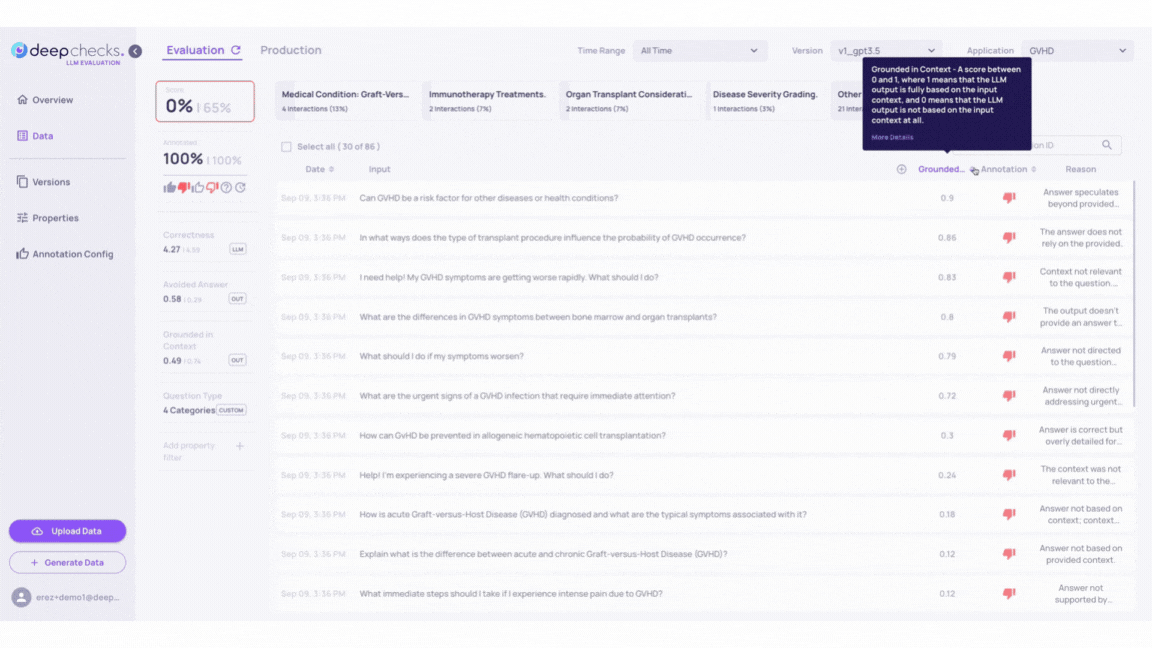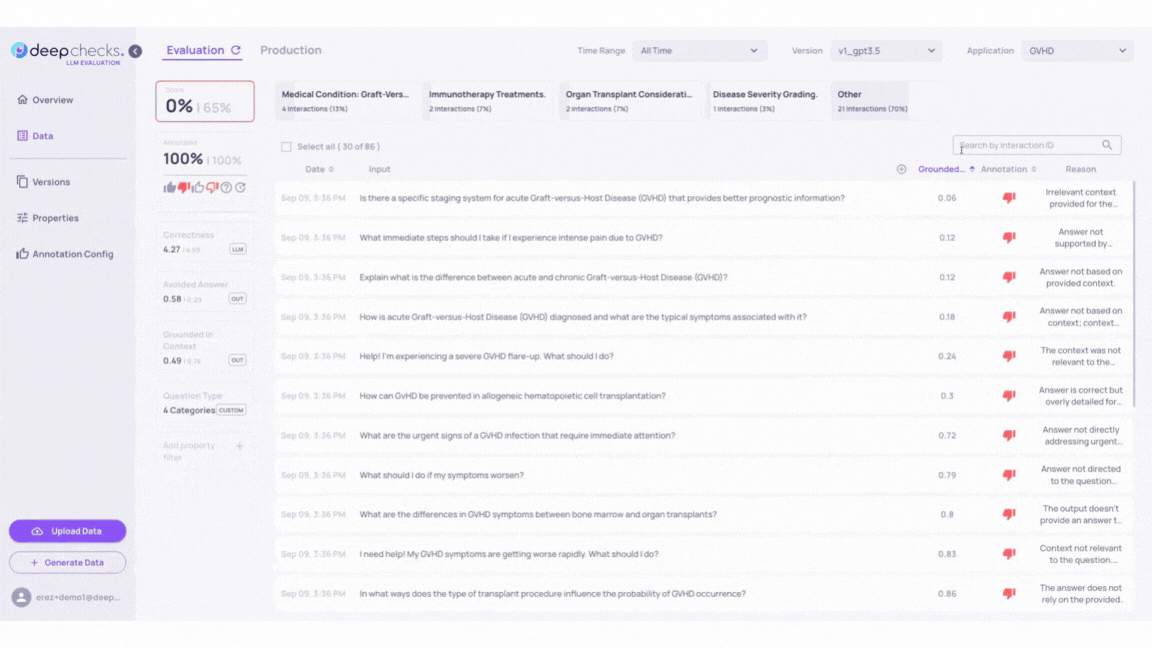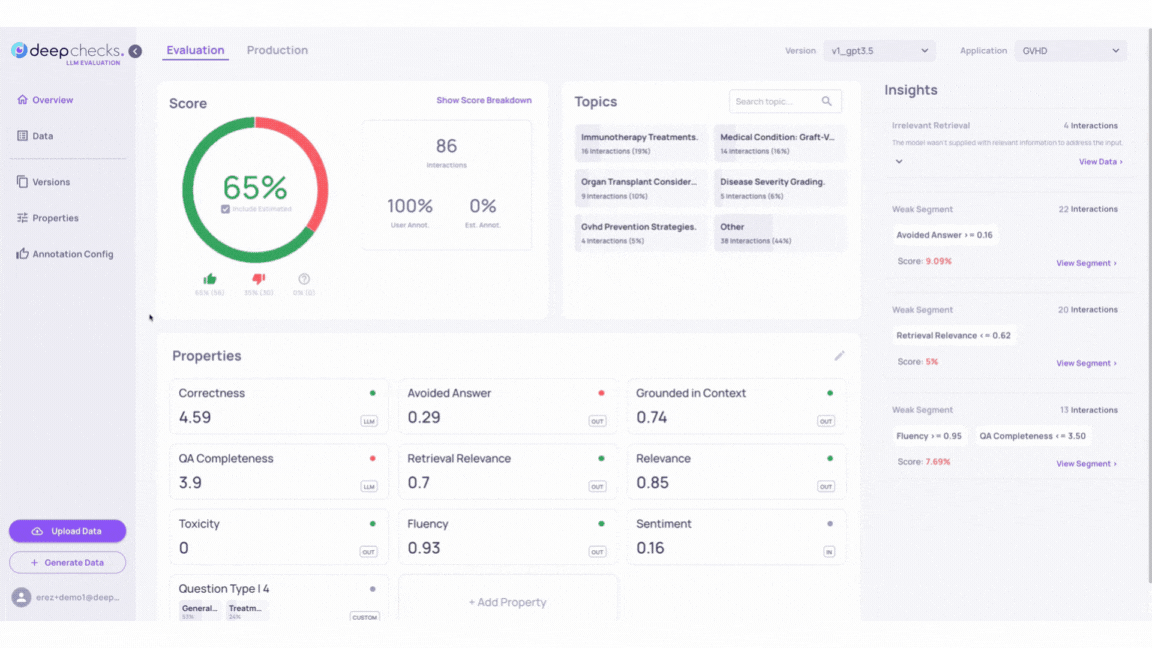
Click on the samples to inspect how the LLM's answers align with the context provided in the Information Retrieval. Higher scores in the "Grounded in Context" property should show better context alignment.
-
Repeat this process with the “Retrieval Coverage” and "Avoided Answer" properties. These properties help assess whether the information retrieved covers the input query and indicate whether the LLM may have avoided answering the input question.
If retrieval coverage and document classification are not being calculated, it means both the classification process and property calculations are disabled to prevent unintended use. To enable these features, navigate to the "Edit Application" flow in the "Manage Applications" screen.
-
You can add up to three property score columns in the data table for side-by-side comparison.
-
Use property filters on the left side of the samples table to view subgroup scores alongside the overall score.
Find Problematic Samples based on Estimated Annotations
To identify problematic samples, check the auto-annotations in version v2_improved_IR. These annotations are based on properties, similarity, and the Deepchecks evaluator. For detailed criteria, refer to the Automatic Annotations page.
Note: In the GIF above, you can see a sample with a low “Retrieval Coverage” score and a high “Avoided Answer” score is automatically annotated as “good.” This configuration is designed to identify cases where the LLM avoids answering due to insufficient relevant information. Such configurations can be adjusted in the “Annotation Config” page.
Find Problematic Samples based on Insights
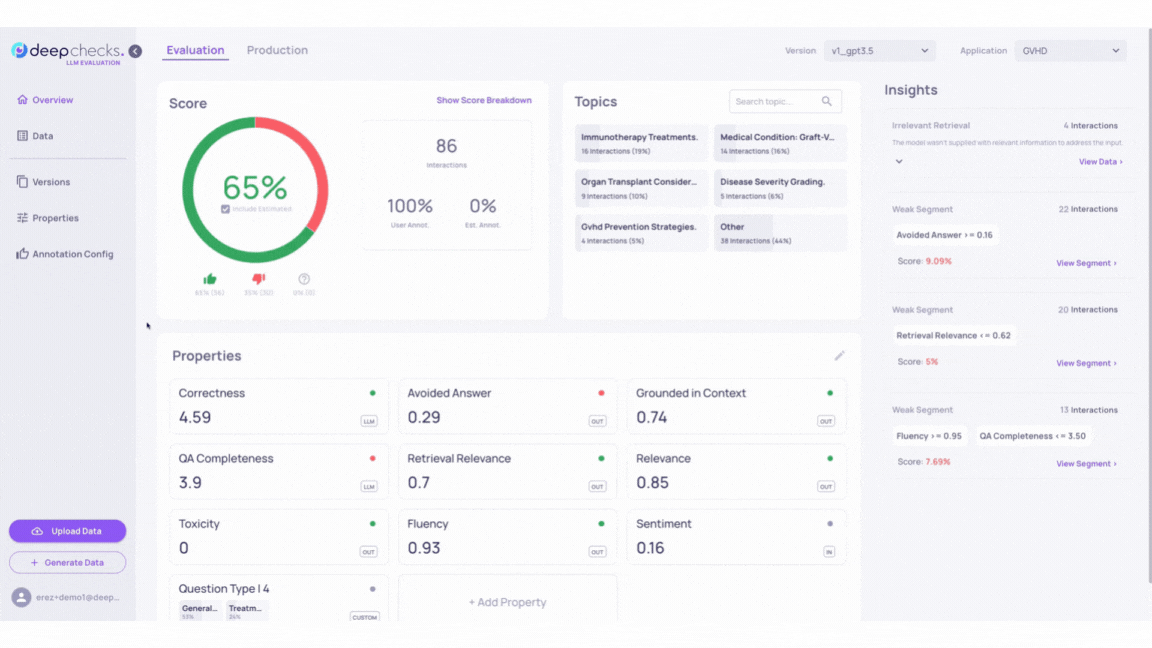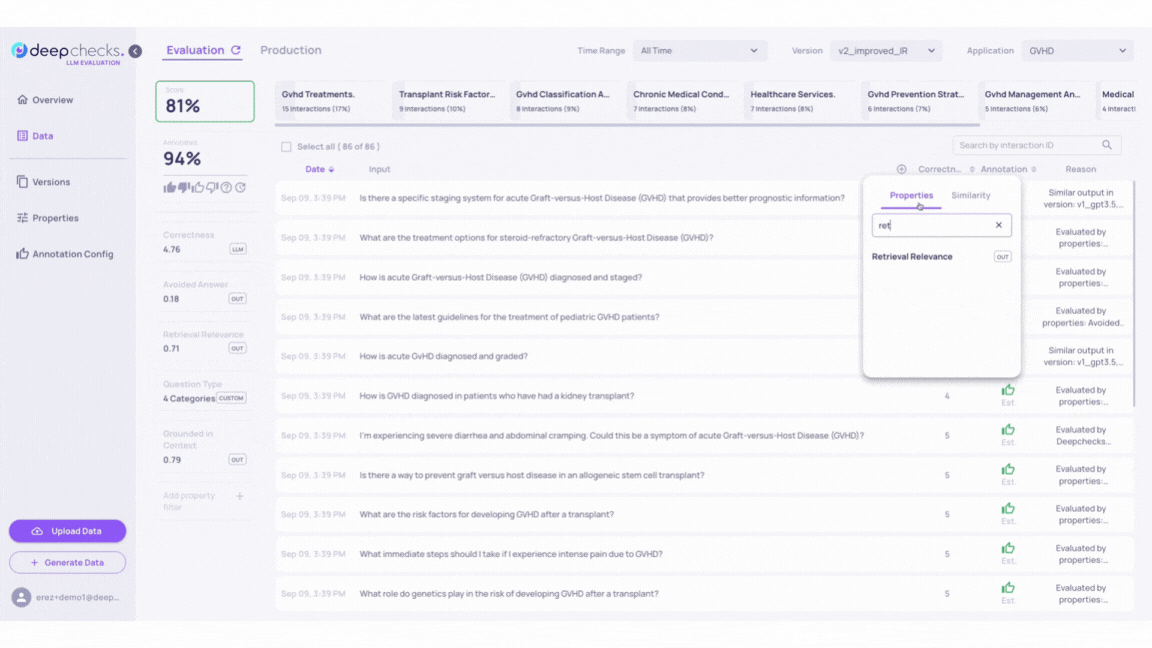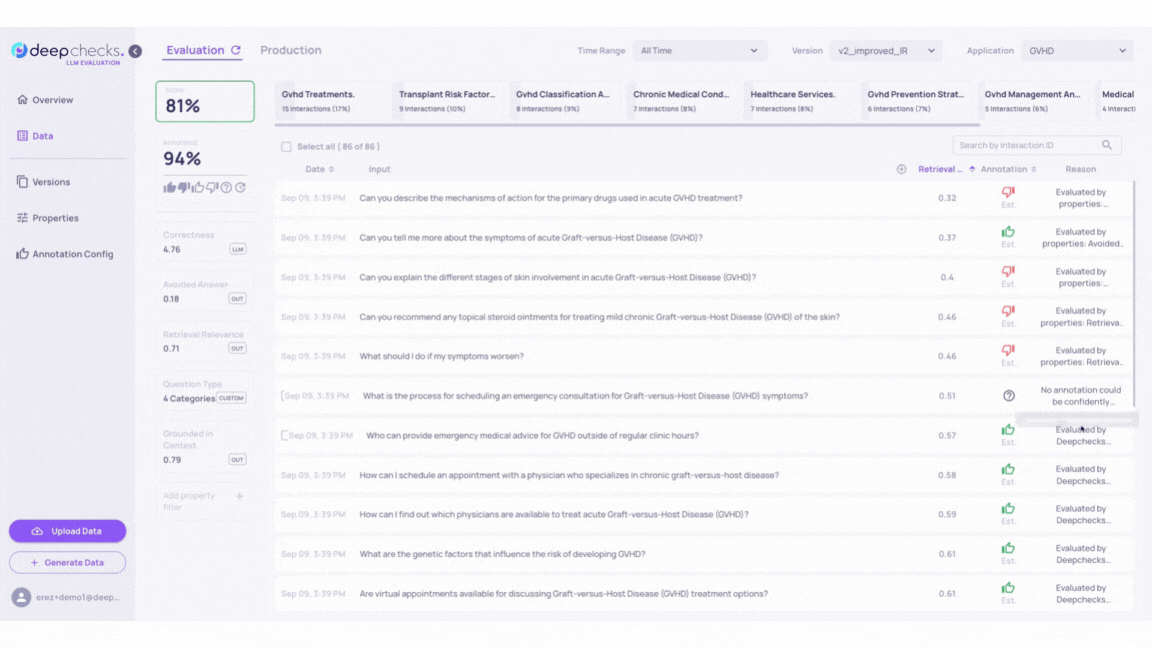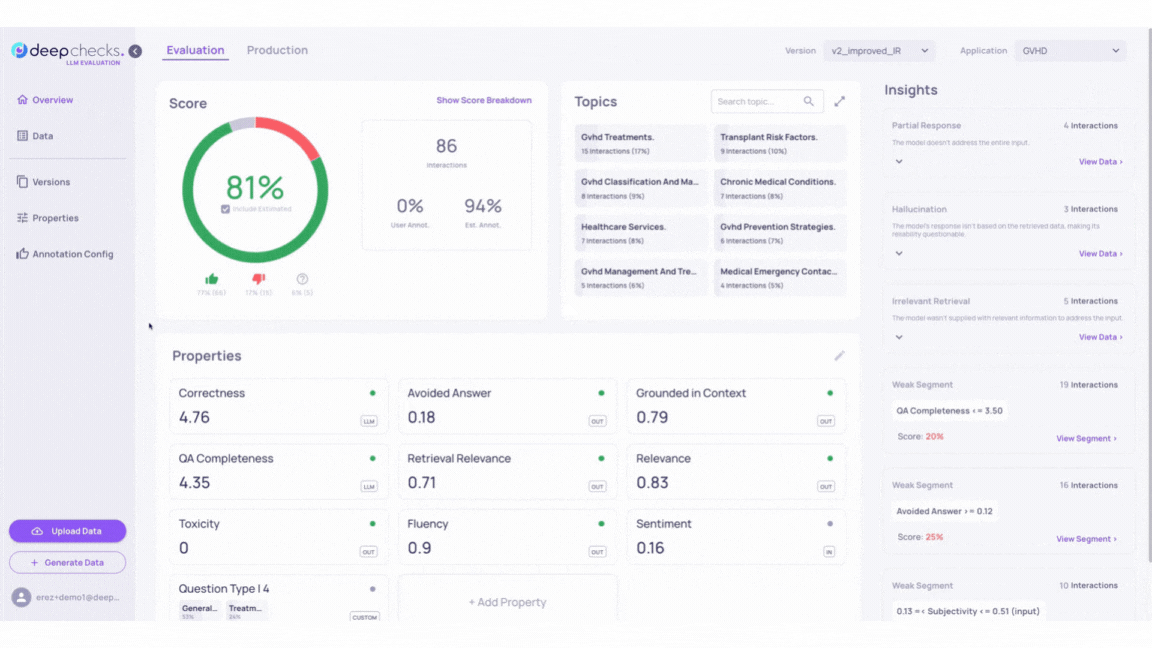
Insights in the Deepchecks system help identify groups of interactions with low scores and shared characteristics. They include Recommendations for improving LLM-based applications and Weak Segments showing subgroups with consistently poor annotations. For more details, see the Root Cause Analysis (RCA).
Go back to our GVHD demo and inspect the Insights calculated by the Deepchecks system for versions v1 and v2_improved_IR.
For example, we can see that while both v1 and v2_improved_IR versions contain samples that triggered the “Irrelevant Retrieval” Recommendations, version v2_improved_IR alone contains output answers that activated 2 more rule Recommendations - “Hallucination” and “Irrelevant Retrieval”.
Example
In this example, we showcase a case where the information retrieval was not sufficient to fully answer the input, and how the model hallucinated instead of stating that it lacked enough information.
For instance, in the interaction type qa-medical-gvhd-47:
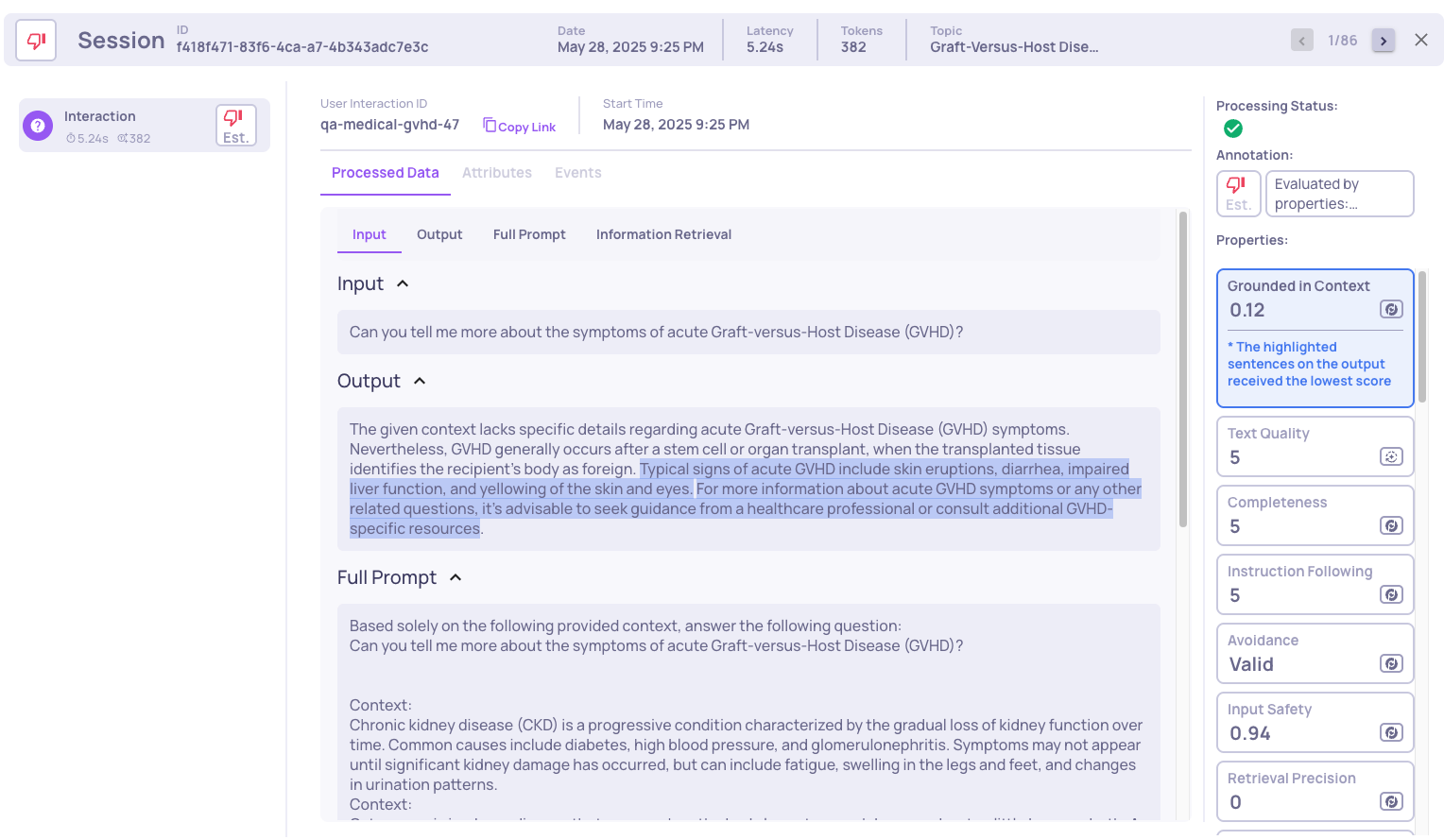
In the next example we see that the interaction was evaluated as "bad" due to low retrieval coverage. We can observe properties such as low retrieval coverage, low avoided answer score, and low grounded context. The hallucinated parts are highlighted. If we further investigate, by clicking on the "Retrieval Coverage" property, we see:
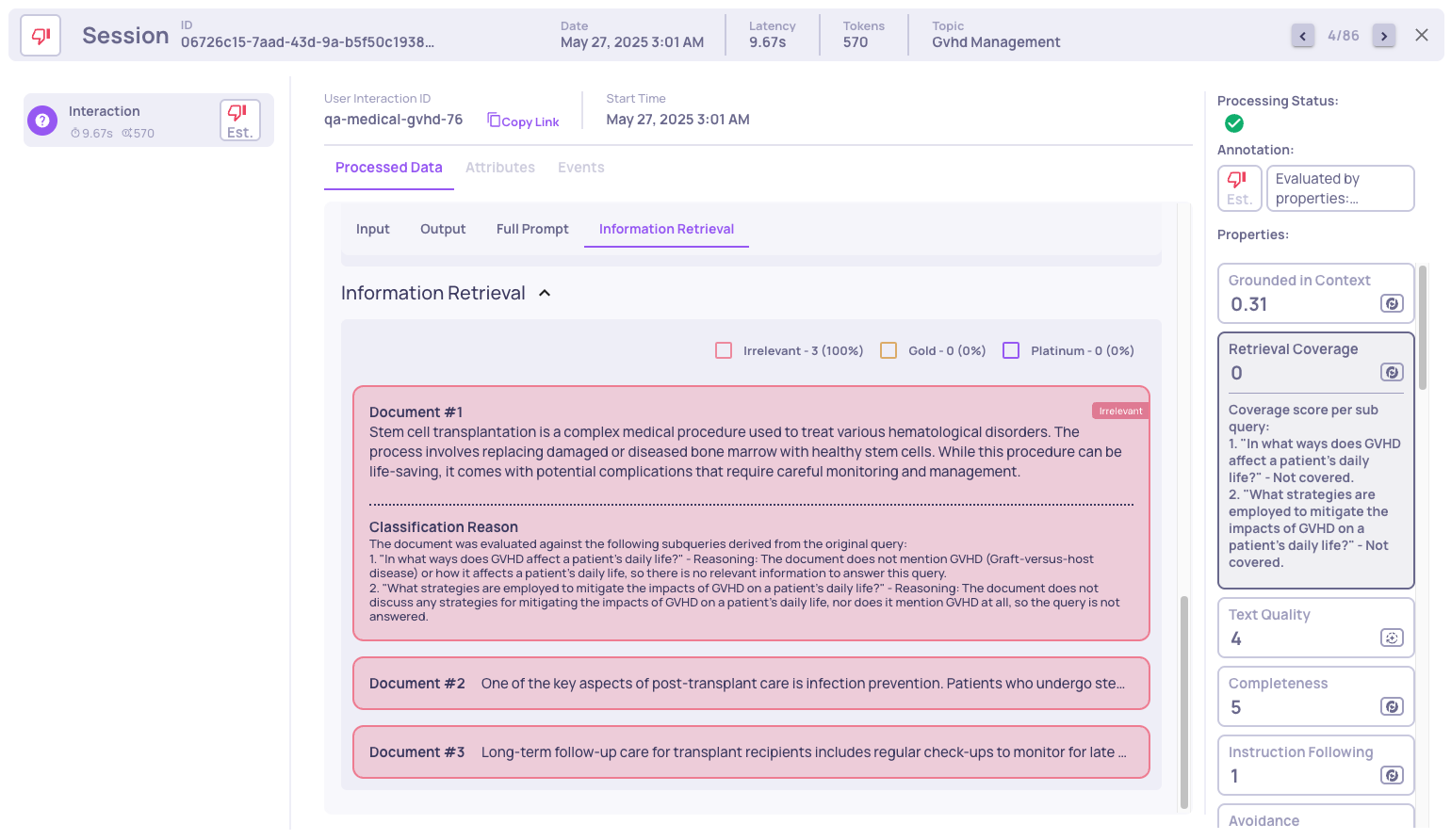
We can see three irrelevant documents were retrieved, meaning that no relevant information was retrieved.
In summary, although the retriever retrieved some relevant information, it was not sufficient to cover all necessary aspects, leading the LLM to hallucinate instead of acknowledging that it lacked enough information to answer the query.
Updated 6 months ago