Analyzing Failures
After identifying which properties your application is failing on, the next step is to investigate why these failures are occurring.
Identifying Failure Causes and Correlated Topics
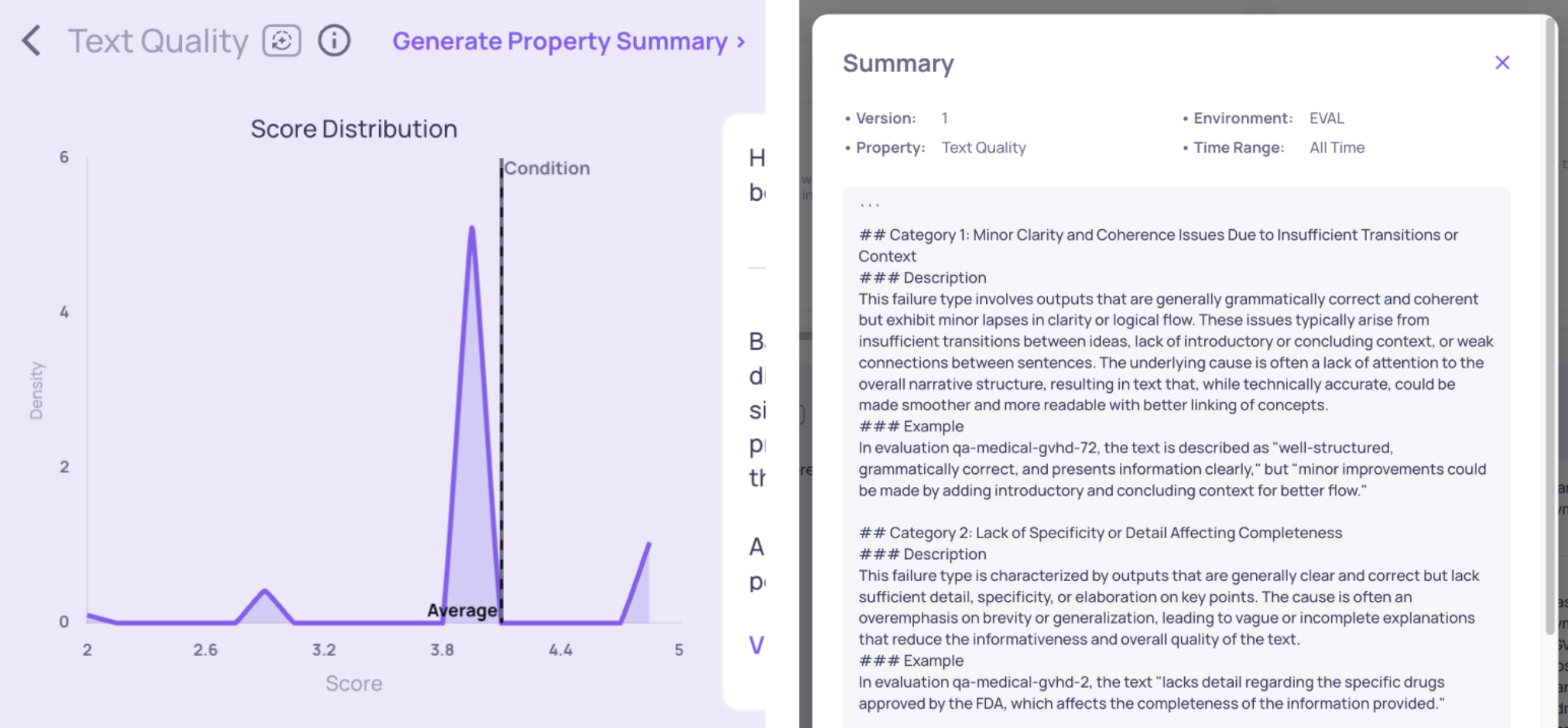
High-Level Property Summary generated for the Text Quality property, pinpointing recurring failure types
To help you avoid manual pattern matching, Deepchecks provides an intelligent Root Cause Analysis (RCA) tool that creates High-Level Summaries for most properties. Think of this tool as an AI Data Analyst that reviews interactions and extracts meaningful patterns for you. The summary format varies by property type:
- Reasoning: For properties with reasoning traces, the agent generates a report listing common failure types, with representative examples and references for each.
- Highlighting: For properties with highlighted segments, the agent groups these into categories to help you spot patterns in failed interactions, with representative examples and references for each.
Deep Diving into Interaction Evaluation
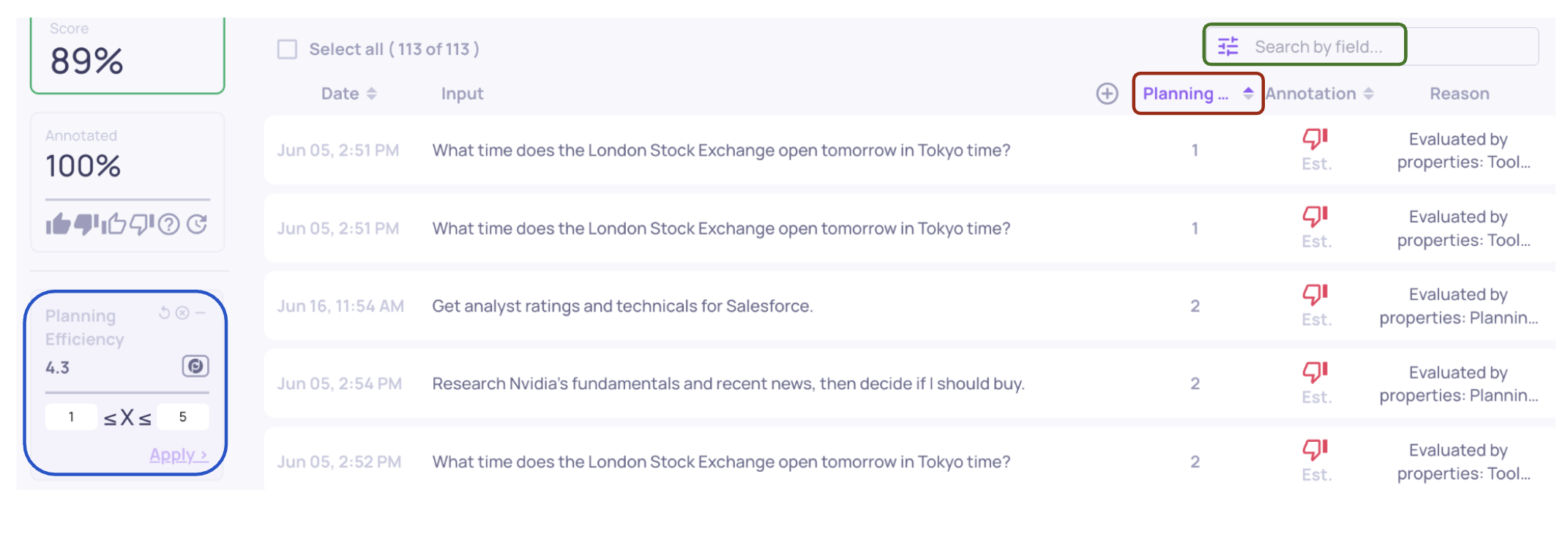
Sorting (red), filtering (blue), and searching (green) interactions in the Interactions page
Whether you reviewed the High-Level Property Summary or not, you may want to examine specific interactions to see how failures occur. To do this, go to the Interactions screen, where you can search for interactions referenced in the High-Level Property Summary using their User Interaction ID. Alternatively, you can also sort or filter interactions by property: use the table’s column header to sort, or the left panel to apply filters.
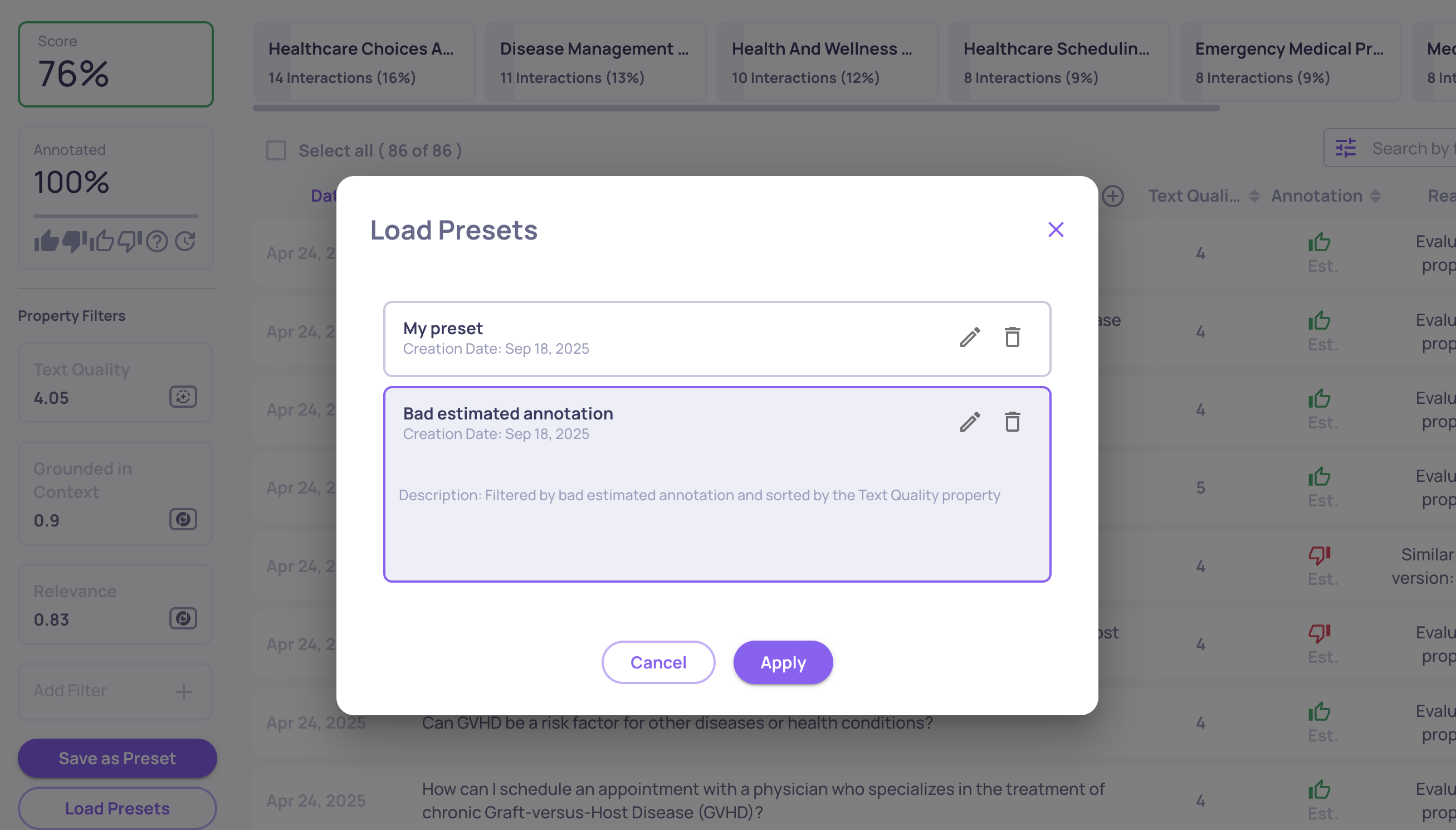
Loading a preset from the preset list in order to apply filters and sorts quickly
On the Interactions screen, filters and sorts can also be saved as presets. After configuring the table to your needs, click Save as preset to store the setup. Presets can then be loaded through Load presets, applied with a single click.

The reasoning trace for the Planning Efficiency property

Text segments in the generated output highlighted as hallucinations by the Grounded in Context property
You can then review interactions of interest individually. When you select an interaction, a list of property scores appears on the right. For more context on how each score was determined, click on a property to access Deepchecks’ Property Explainability tools, which include two main features:
- Reasoning: For Deepchecks properties evaluated using LLM-as-a-judge, you’ll see both the predicted label or score and the Judge’s explanation-a key resource for diagnosing failures.
- Highlighting: Some properties display highlighted text segments crucial to the evaluation. For example, Grounded in Context, Deepchecks’ hallucination detector, highlights specific claims in outputs flagged as hallucinated.
Mitigating Identified Problems
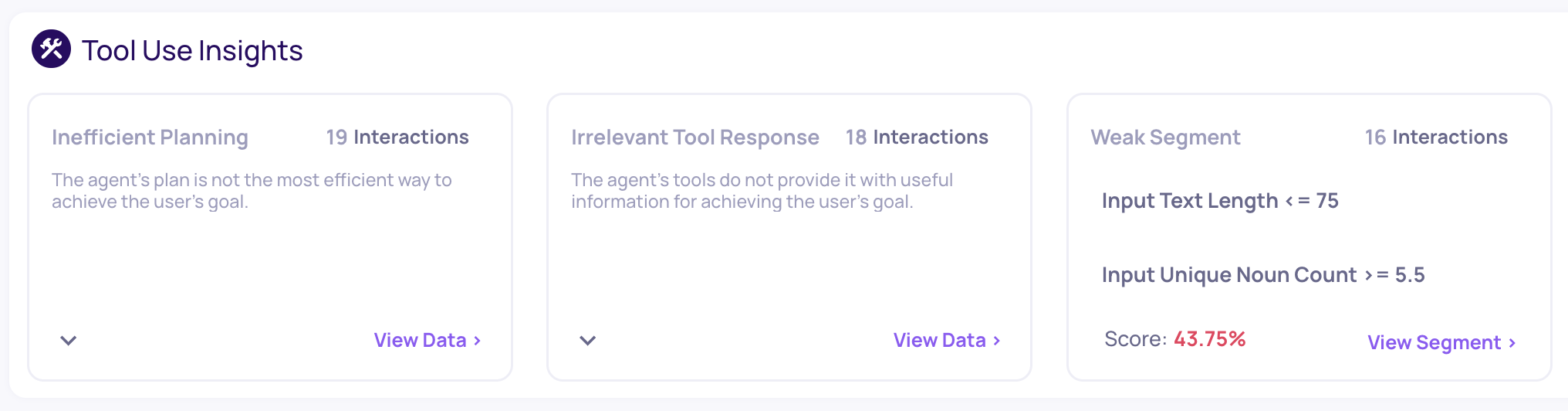
Suggested Property Recommendations and Weak Segments for Tool Use interactions
Once you have identified the root cause of failure, you need to address it. If you need inspirations for such ideas, you can consult one of Deepchecks' RCA tools: the Insights box, found on the Overview page, and specifically the Property Recommendations. As with the Score Breakdown, start by selecting a task. You’ll then see a list of suggested insights, which are split into two categories:
- Property Recommendations: When specific properties receive low scores, we provide estimated root causes and actionable mitigation suggestions-based on Deepchecks’ extensive LLM evaluation experience. Click the down arrow in the bottom-left of each box for more details.
- Weak Segment: This insight flags data segments where the average overall score is notably lower than the rest-indicating, for instance, that input texts may be too brief or ambiguous for the model. It can be a useful tool in classic-ML-like feature importance ranking.

Expanded Property Recommendation, providing an analysis for the failure and mitigation suggestions
Adjusting Thresholds
After analyzing the detected failures, you may determine that-for your use case-a score of 3 in Planning Efficiency or 0.4 in Grounded in Context is acceptable and should not be considered a failure. Deepchecks’ auto-annotation configuration is based on rules learned from a variety of use cases, but these defaults may not always fit your specific needs. Sometimes, a property may be irrelevant to your task, or the default threshold may require adjustment.
If you want to customize the auto-annotation configuration based on your root cause analysis, you can learn how to do so on this page.
Further Analysis
For further analysis-whether you want to use dedicated data analysis tools like Tableau or Power BI, or work with the evaluation data directly in code-you can always download your results using our SDK or from the Interactions page in the UI. The downloaded data will contain all fields uploaded by you along with the evaluation scores and metadata.
Updated 3 months ago