Monitor Production Data and Research Degradation
Once a version is deployed in production, ongoing monitoring of the application’s performance is crucial. This is typically the first time the LLM-based application encounters unsupervised questions.
In our use case, after determining that version v2_improved_IR was suitable for production, we need to properly monitor its performance, detect whether or not there is a degradation in performance, and if so - identify the causes.
Observations after Uploading the v2_production Dataset:
-
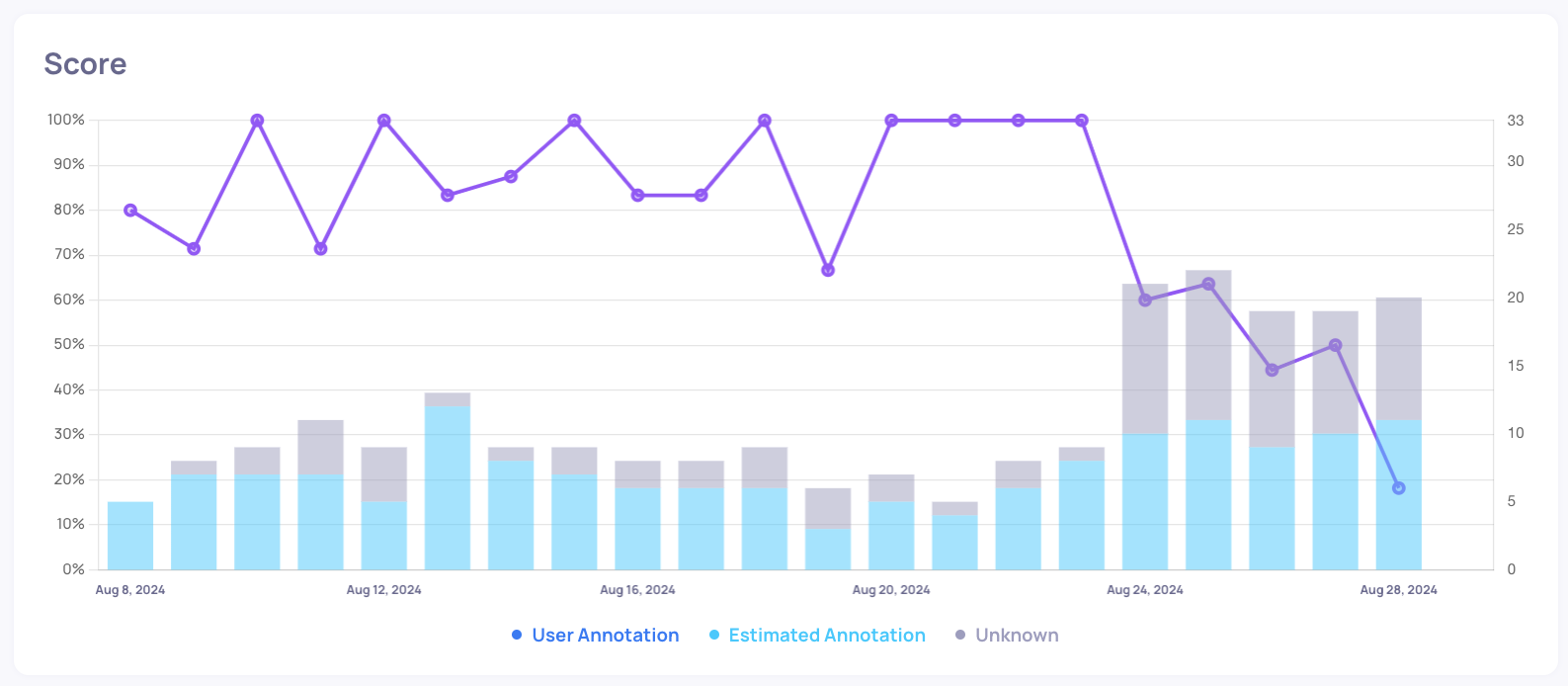
Initial Performance: The application performed well initially, with average auto-annotation scores ranging from 70 to 100.
-
Increase in Interactions: There was a sudden surge in interactions in the last 4 days.
-
Performance Decline: Alongside this surge, we observe a decline in annotation scores alongside a rise in unannotated interactions.
Detecting the problem
In order to fully understand the change in behavior, it is essential to examine the data itself.
Before doing so, The Deepchecks system provides useful insights - Clicking on any property in the Overview page displays a trend line graph reflecting the property’s score over the selected time range.
Adjusting the time range will update the graph accordingly.
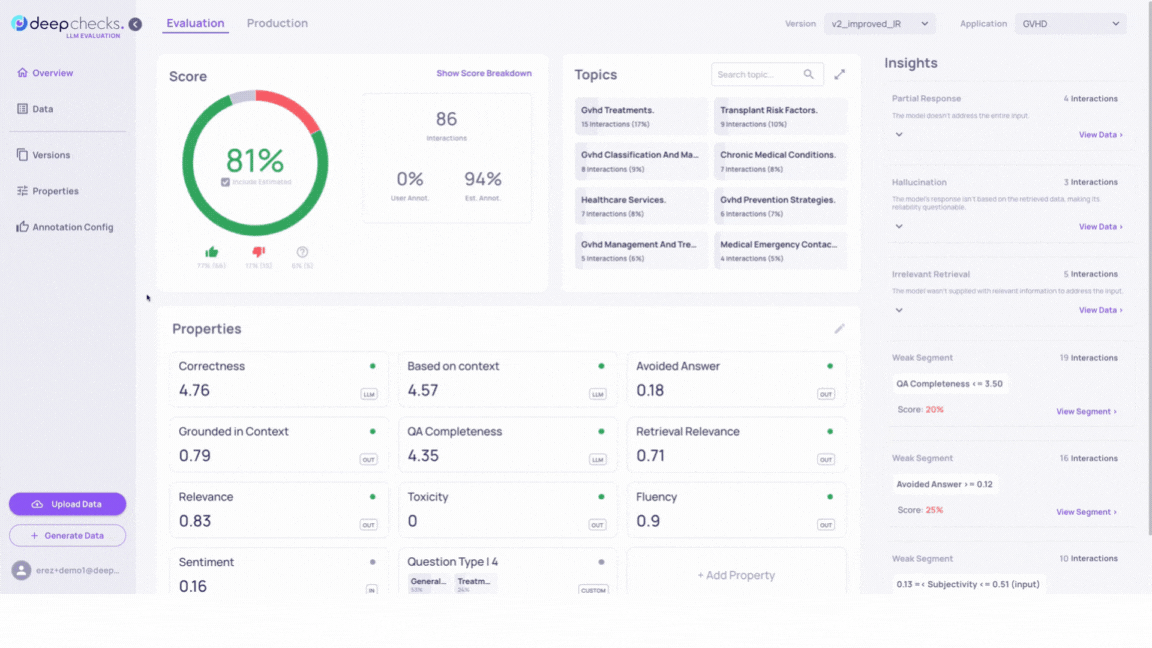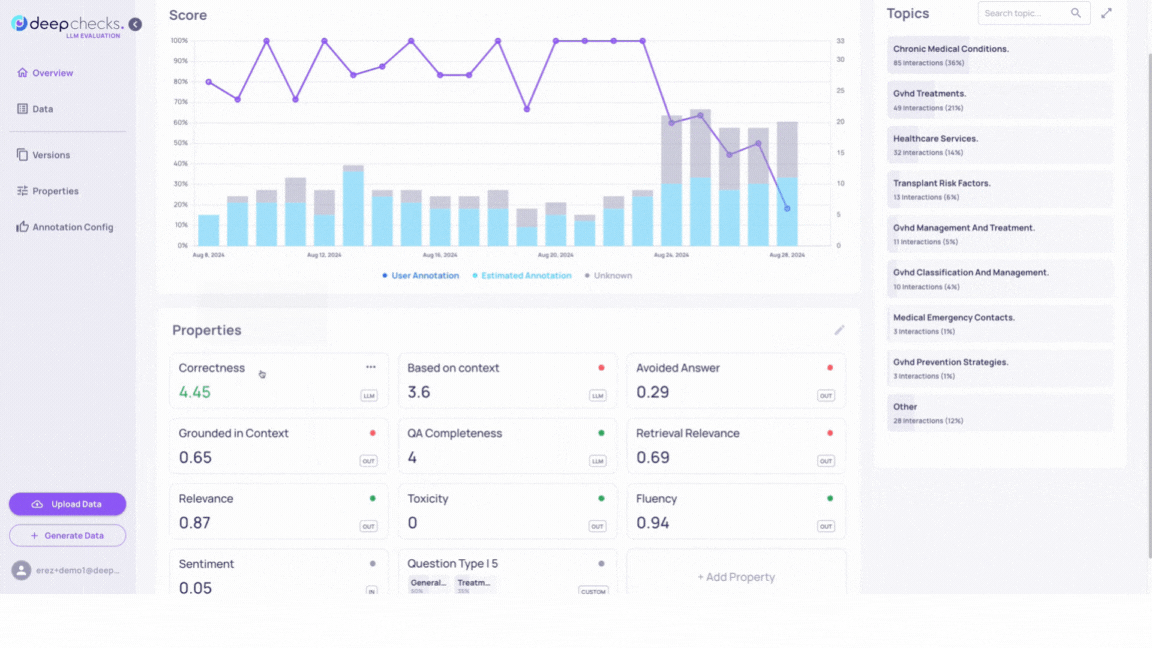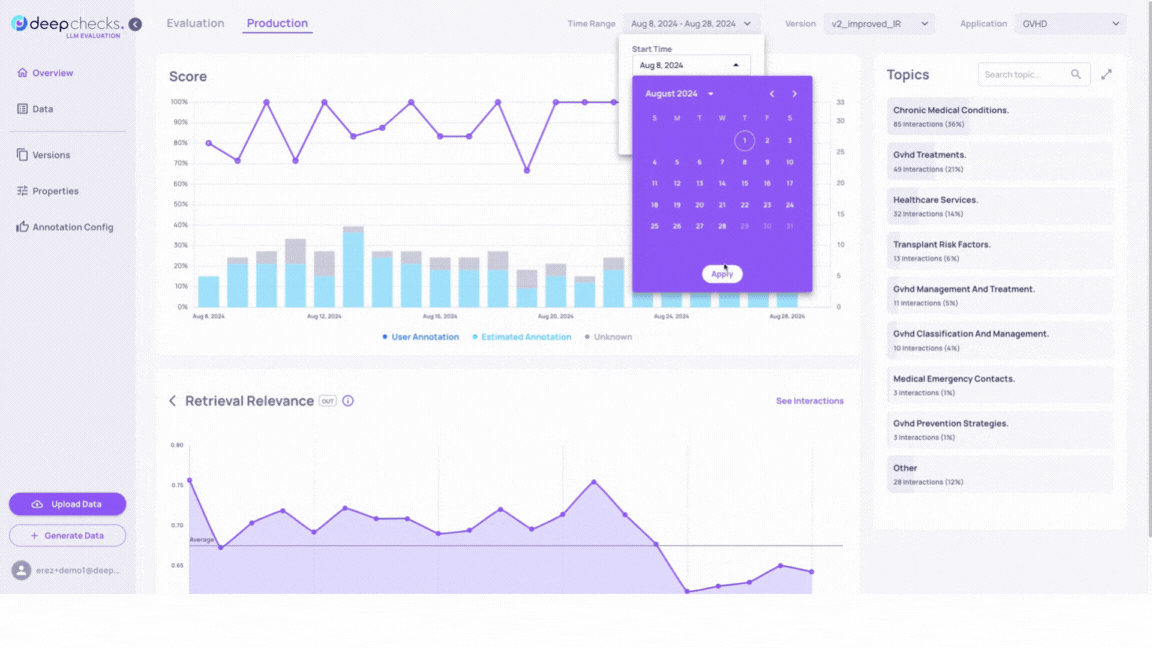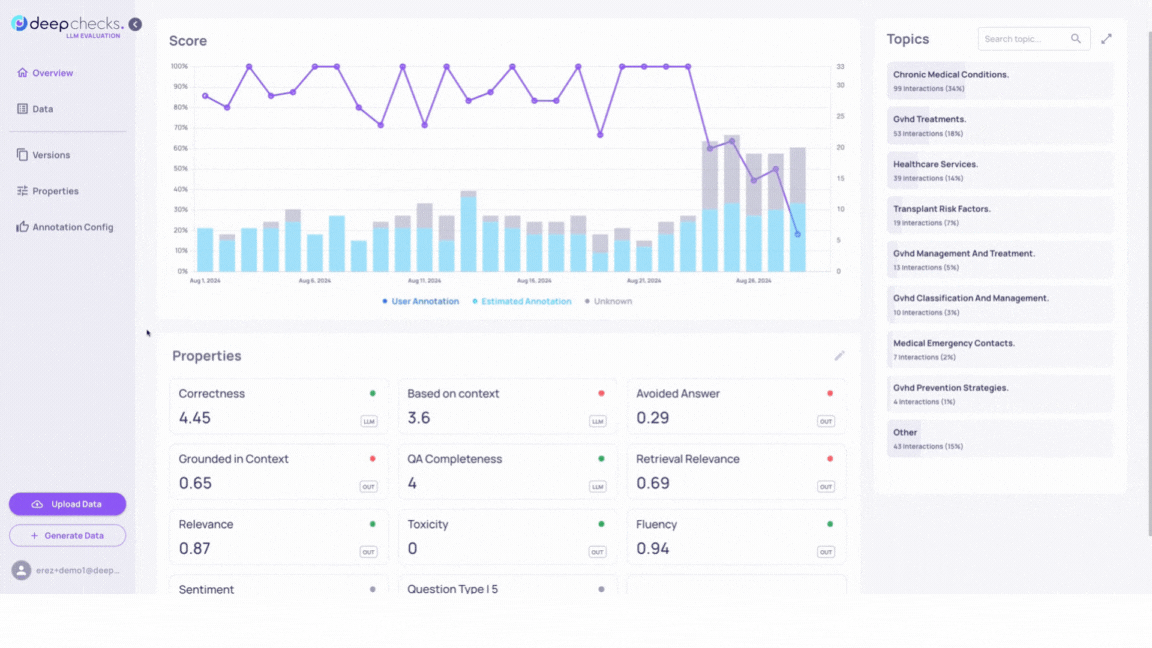
In the GIF above we can observe a significant shift in scores for properties such as Avoided Answer, Retrieval Coverage and more.
This indicates a change in the interactions our application is handling from this date onward.
In order to narrow down the number of interactions to be reviewed, we will filter our data on the last 4 days.
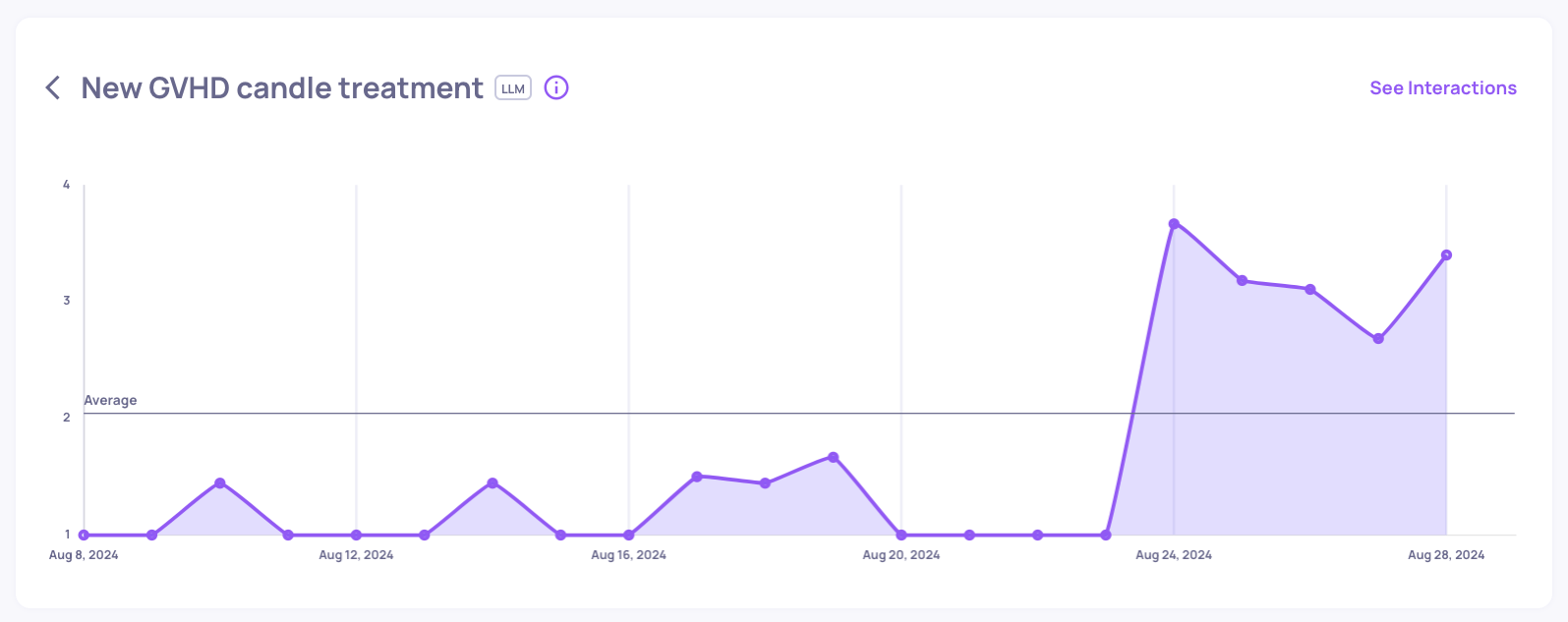
After examining the interactions, we notice there are multiple interactions asking about some sort of a new treatment (Can-GVHD, GVHD-Candle).
Knowing the data we provided to our LLM-based application, we know the model does not have information to answer these new treatment related questions.
Adding a New Prompt Property:
To further narrow down the relevant problematic samples, let’s add another prompt Property, using the following configuration:
New prompt Property Details
Property Name: new GVHD candle treatment
Description: Detects relevant samples that ask about the new GVHD candle based treatment.
System Message:
Read the input and check if the words 'Can-GVHD' or 'GVH-Candle' are in it. If so, give it a score of 5, otherwise give it a low score of 1.
Interaction Steps for Property: input
Recalculate Property on Existing data
After saving property definition, recalculate it to get its values on data previously uploaded to the system:
Versions: v2_improved_IR
Environment: Production
Next Steps:
Upon identifying significant gaps in the application’s knowledge, initiate a new development cycle.
This new version should address the missing information and improve any flaws or weaknesses identified in the current application.
Updated 8 months ago