Usage Management and Optimization
Understand how DPUs work on Deepchecks SaaS, monitor your usage, and optimize spend across sampling, model selection, properties, and data volume.
Applies to SaaS onlyThis page is specific to the Deepchecks SaaS deployment, where Deepchecks manages the LLMs used for evaluation and your usage is metered in DPUs.
- On AWS SageMaker, all LLM inference runs through your own Bedrock models and API keys - there are no DPUs. See Optimizing LLM Costs on SageMaker.
- On Self-Hosted Enterprise, you configure your own LLM connections and pay your providers directly - there are no DPUs. See Model Configuration for Self-Hosted Deployments.
The general optimization strategies (sampling, property selection, pausing heavy properties, etc.) still apply to all deployments, but the DPU rates and cost framing on this page are SaaS-specific.
DPUs (Deepchecks Processing Units) are the core usage units in the Deepchecks SaaS platform. Think of them as your monthly usage bank - refreshed every month - consumed by data uploads, LLM-based property calculations, document classification, and other platform features. On SaaS, Deepchecks manages all the underlying LLMs that power evaluation, and DPUs are how that usage is metered.
This page covers how DPUs work, how to monitor your spend, and every lever available for optimization.
Understanding DPU Usage
DPU consumption breaks down into three categories:
Base Usage
Base usage is the cost of uploading data to the platform. Uploading 1 million tokens for evaluation costs 250 DPUs, while sending 1 million tokens to storage only (unevaluated) costs 40 DPUs. This includes all data fields submitted per interaction.
LLM Usage
LLM usage covers all tokens processed by LLMs - both inputs and outputs - across Deepchecks features. This includes built-in LLM properties, user-created prompt properties, document classification, topic classification, and features like Analyze Failure Modes. The cost depends on which model runs the feature:
| Model | DPUs / 1M tokens |
|---|---|
| OpenAI GPT-4.1-nano | 10 |
| OpenAI GPT-4o-mini | 15 |
| OpenAI GPT-3.5-turbo | 40 |
| OpenAI GPT-4.1-mini | 40 |
| OpenAI o3-mini / o4-mini | 110 |
| OpenAI GPT-4.1 | 200 |
| OpenAI GPT-4o | 250 |
| Anthropic Claude Sonnet 3.5 / 3.7 | 400 |
| OpenAI GPT-4 | 1,000 |
The model Deepchecks uses for LLM features is configurable at the organization and application level. Switching to a lighter model for lower-stakes properties can significantly reduce costs.
Translation Usage
If translation is enabled for your application, tokens sent through the translation pipeline consume additional DPUs:
- Language detection (Claude-3-Haiku): ~40 DPUs / 1M tokens
- Translation (Claude Sonnet): ~400 DPUs / 1M tokens
Monitoring Your Usage
All of your usage - broken down by type and matched to your current plan - is visible in the Usage tab under Workspace Settings.
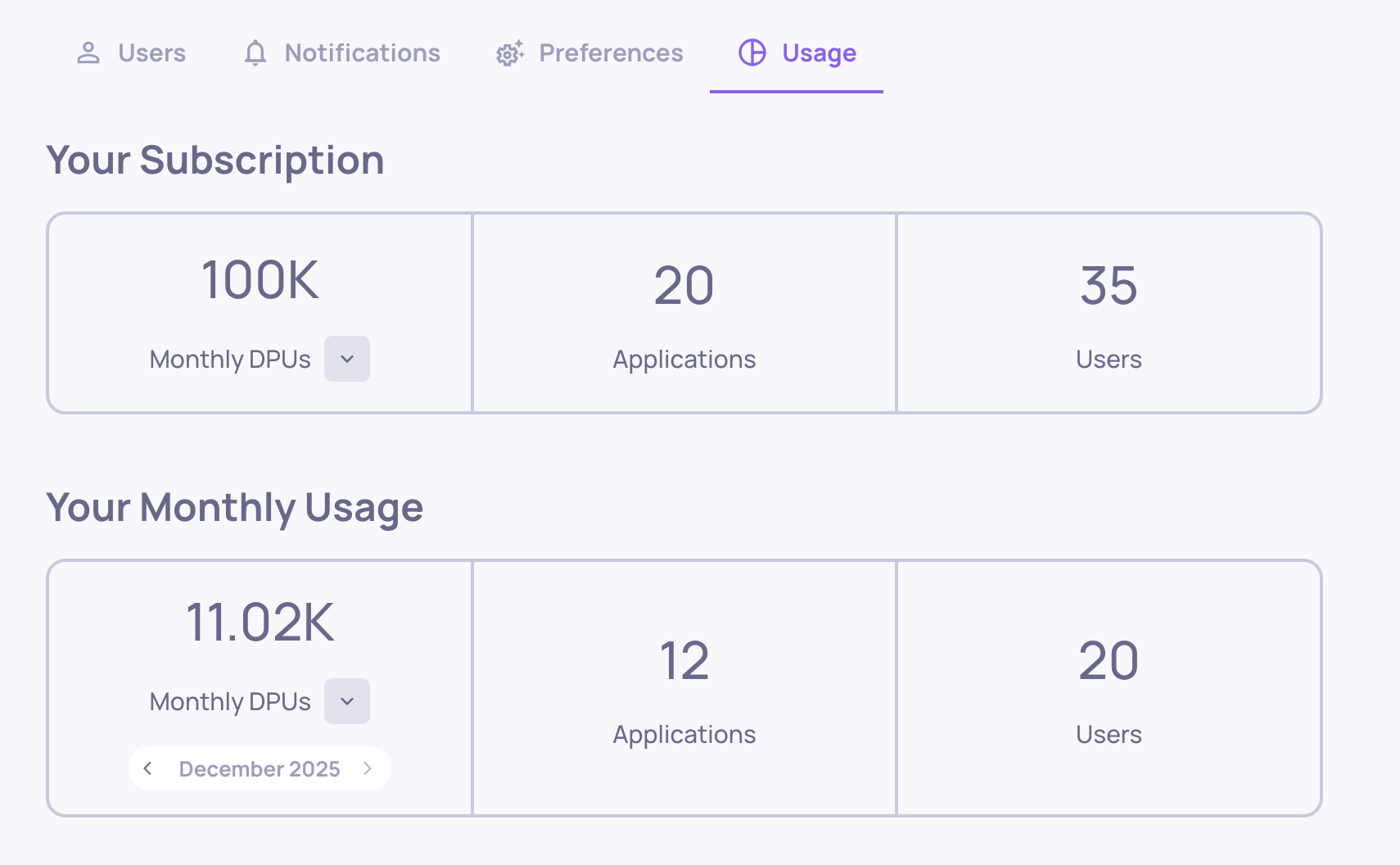
Download usage reportAdmins and Owners can go to Workspace Settings → Usage tab → click Download Usage. After selecting a time range, you'll get a CSV with all usage details across your organization's applications, versions, environments, and service types - making it easy to identify exactly where your DPUs are going.
Use this data to:
- Identify which applications and versions drive the most usage
- Find which properties or service types consume the most tokens
- Make targeted optimization decisions based on actual numbers
Platform Configuration
These are one-time (or infrequent) settings changes that reduce your baseline costs across the board. Consider these before uploading data at scale.
Choose the Right Model for Your Prompt Properties
On SaaS, Deepchecks manages the models powering built-in properties internally. The one model choice that's in your hands is the one used for your prompt properties - your custom LLM-as-a-judge evaluators.
When creating or editing a prompt property, you choose which model runs it. This is where cost and quality trade-offs are most direct: a lighter model costs fewer DPUs per evaluation run, while a stronger model may produce more reliable judgments for complex guidelines. Choose based on the stakes of that specific property:
- For high-volume, simpler evaluations (e.g., "Is the response polite?"), a lightweight model is usually sufficient.
- For nuanced, high-stakes properties (e.g., "Does the response follow all safety guidelines correctly?"), invest in a stronger model.
The DPU rate table above shows the cost per model - use it to make informed trade-offs.
Disable Language Detection (if your data is English)
Deepchecks automatically detects language and translates non-English content before evaluation. This detection step uses LLM calls on every interaction. If your data is in English, disable this to save tokens:
- Navigate to Workspace Settings → Preferences → Application Settings
- Set Translation_Detection to false
Disable Topic Classification (if not needed)
Deepchecks automatically classifies sessions into topics using LLMs. If you don't need topic grouping, disabling this saves significant LLM usage:
- Navigate to Workspace Settings → Preferences → Application Settings
- Set Topics to disabled for the relevant applications
Disable Document Classification (if not using RAG retrieval properties)
Document classification uses LLM calls to classify each retrieved document as Platinum, Gold, or Irrelevant. If you're not actively using the retrieval properties that depend on it (nDCG, Retrieval Coverage, etc.), disable it:
- Go to Manage Applications → Edit Application
- Turn off Document Classification
Controlling Data Volume
DPU costs scale directly with the amount of data that gets evaluated. These strategies help you control volume without losing signal.
Sample Your Production Data
This is the single most effective lever for production environments. Configure a sampling ratio so Deepchecks evaluates only a representative subset:
- Go to Manage Applications → Edit Application
- Set the Sampling Ratio (0 to 1)
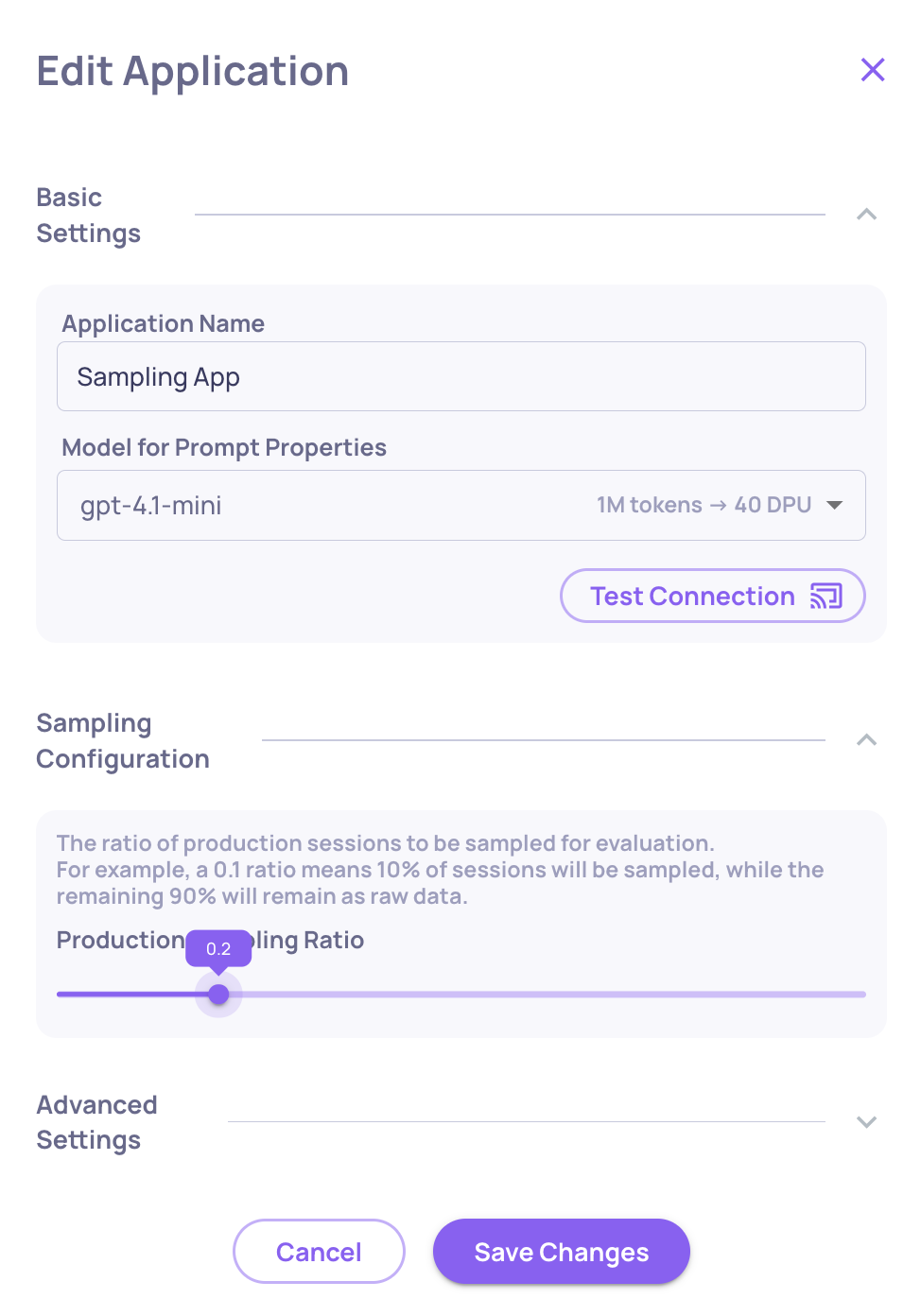
Setting the Sampling Ratio
Recommended starting point for high-volume apps: 0.2 (20%). At this rate, you spend roughly 35% of what full evaluation would cost while keeping statistically representative results. Deepchecks uses random selection, so the evaluated sample mirrors your overall traffic distribution.
Interactions not selected for evaluation land in the Storage screen - stored as raw data, where you can selectively send specific sessions for evaluation when needed.
Right-Size Your Evaluation Dataset
More data doesn't always yield better insight, but it always costs more. Build an evaluation set that is representative and statistically meaningful, not exhaustive. Remember that in agentic workflows, each session can contain many spans - a dataset of 150 traces with deep span trees is very different from 150 single-turn interactions.
Upload Minimal Data During Setup
When first configuring Deepchecks - setting up properties, interaction types, and thresholds - every uploaded session gets processed through all active properties. Upload only 3-5 sessions during configuration to validate your setup. Scale up only after you've finalized your configuration.
Pre-Process and Trim Your Data
Large blobs of raw or verbose text may include content irrelevant to evaluation. Where possible, trim data fields to include only what's needed for quality and performance insights before uploading.
Property Optimization
Properties are where most of your LLM tokens are spent. These strategies help you run only what you need, on only the data that matters.
Keep Only Relevant LLM Properties Active
Each LLM property runs inference on every interaction it's applied to. In agentic use cases with many spans per session, a single unnecessary property can increase costs significantly.
- Review the full list of enabled properties for each application and interaction type on the Properties page
- Disable any LLM properties that don't contribute to your evaluation goals
- Consider whether a property needs to run on every interaction type, or just specific ones
Note: Pinning properties to the Overview screen is for quick access - it doesn't affect which properties are calculated. All active properties (pinned or not) run on every uploaded interaction.
Choose the Right Data Fields for Prompt Properties
When creating a prompt property, you select which data fields are included in the prompt sent to the LLM. Including unnecessary fields drives up token usage without improving accuracy.
Include only the fields truly relevant to the property's logic. For example, if you create a "Clarity of User Input" property, there's no need to include heavy fields like history or full_prompt. Excluding unrelated fields reduces costs and helps the LLM focus - leading to cleaner evaluations.
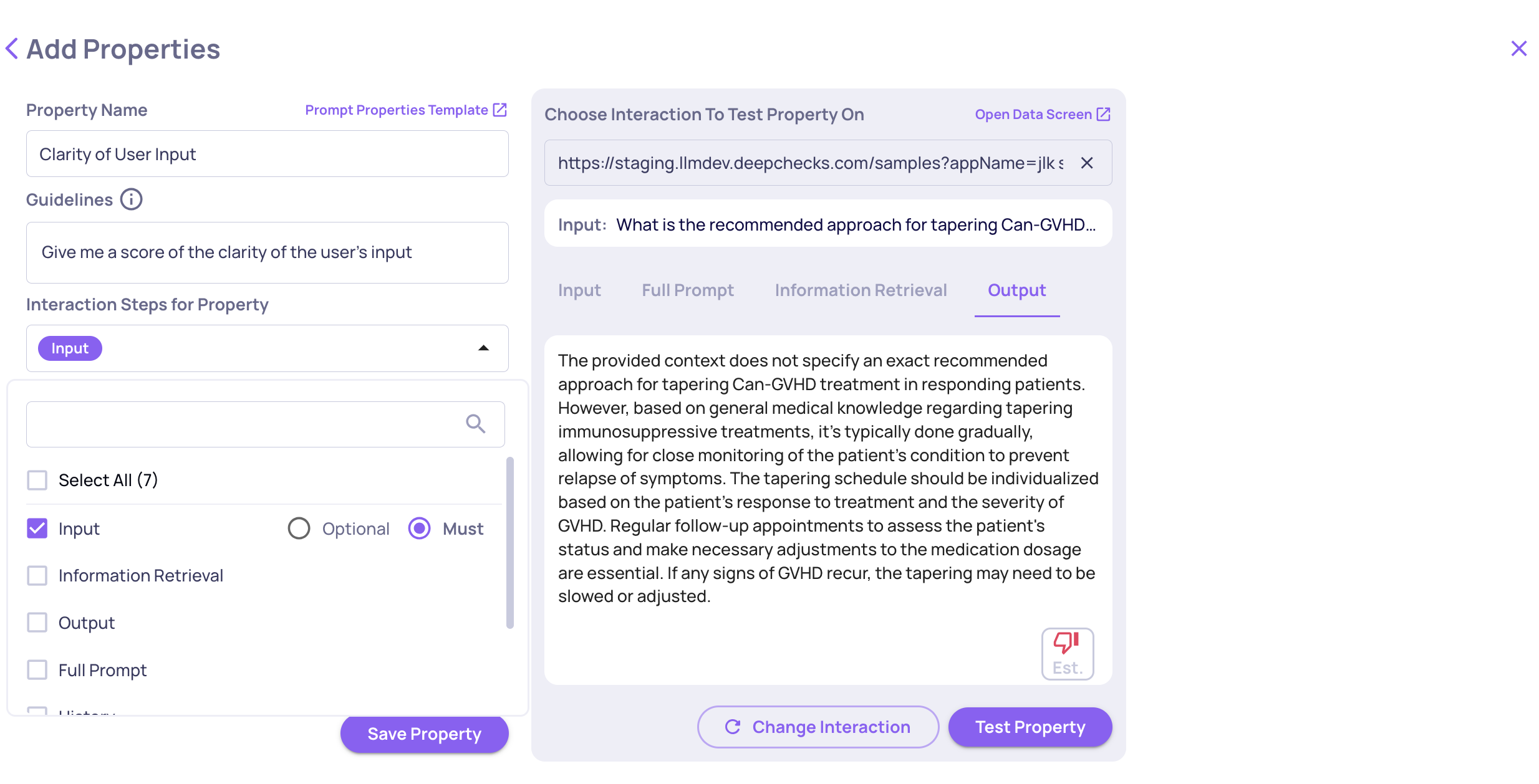
Choosing Data Fields While Creating a Prompt Property
Pause Heavy Properties and Run Them Selectively
Not every property needs to run on every interaction. You can pause properties so they don't calculate automatically - then run them on-demand against specific subsets.
To pause: Go to Properties in the sidebar, find the property, and click the toggle icon. Paused properties skip all new data (no DPU cost) but preserve existing scores and remain available for on-demand calculation.
To run selectively: On the Interactions page, select the relevant interactions, click the "calculate property" icon, and choose the property to run.
Example workflow:
- Upload data with only lightweight properties active
- Review results and initial annotations
- Identify the interactions that need deeper analysis (e.g., flagged as "bad")
- Run expensive properties only on that subset
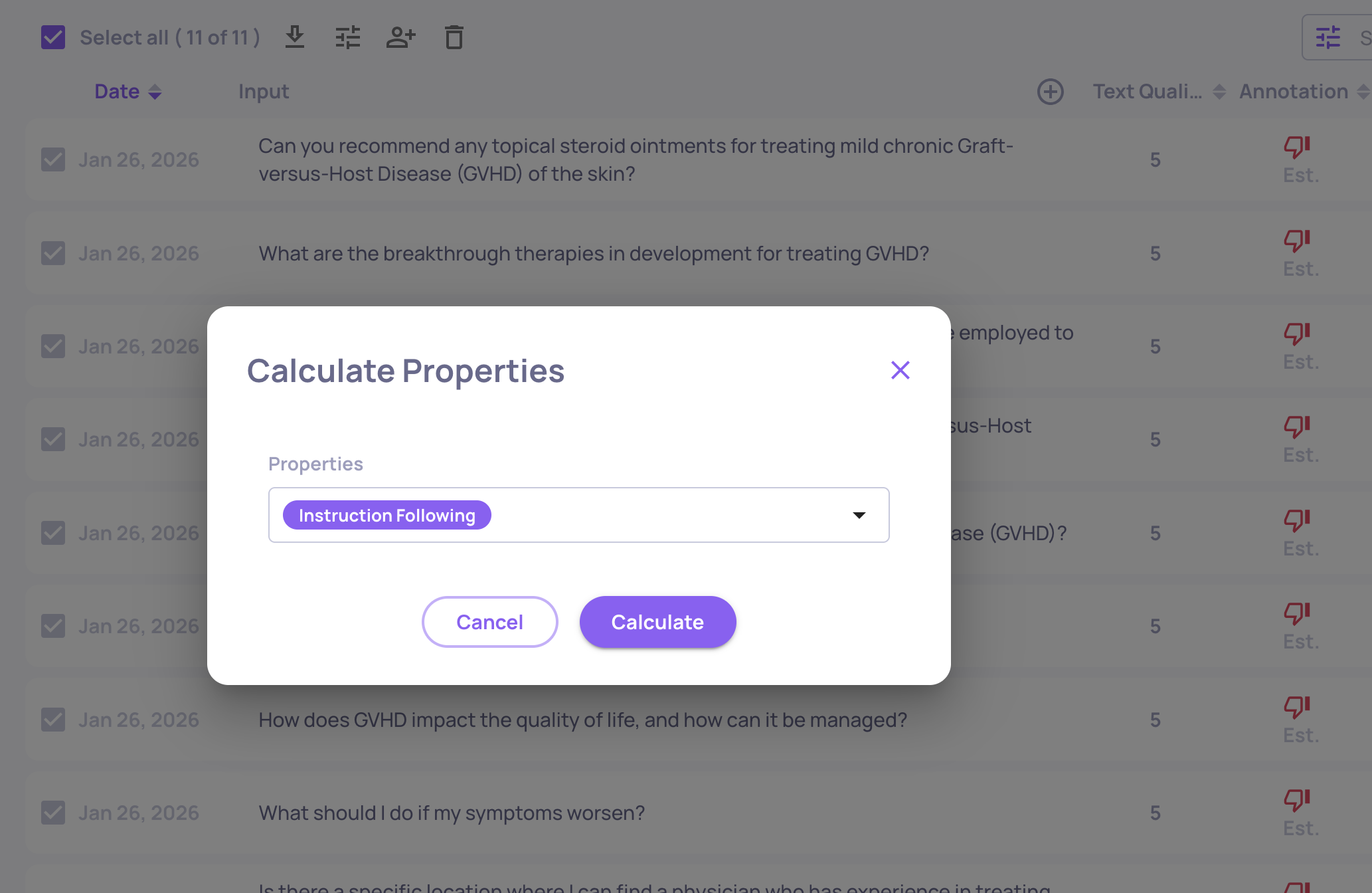
Reduce the Number of Judges (if you are using more than one judge per property)
Prompt properties can run with 3 or 5 judges for more reliable scoring, but this costs proportionally more. Use 1 judge (default) unless the property is critical and you need high confidence in every score.
→ See Number of Judges for when to use multiple judges.
Optimization Checklist
Platform Configuration
| Action | Impact | Where |
|---|---|---|
| Choose model wisely for prompt properties | Medium-High | Prompt property editor |
| Disable language detection (if English) | High | Workspace Settings → Preferences → Application Settings |
| Disable topic classification (if not needed) | Medium | Workspace Settings → Preferences → Application Settings |
| Disable document classification (if not using retrieval properties) | Medium | Manage Applications → Edit Application |
Controlling Data Volume
| Action | Impact | Where |
|---|---|---|
| Set production sampling ratio | High | Edit Application → Sampling Ratio |
| Right-size your evaluation dataset | Medium | Data upload pipeline |
| Upload minimal data during config | High | Manage Applications |
| Pre-process and trim data fields | Medium | Instrumentation code |
Property Optimization
| Action | Impact | Where |
|---|---|---|
| Remove unnecessary LLM properties | High | Properties page |
| Choose minimal data fields for prompt properties | Medium | Prompt property editor |
| Pause heavy properties, run selectively | Medium | Properties page → Toggle / Interactions → Recalculate |
| Reduce number of judges | Low-Medium | Prompt property settings |
Ongoing Monitoring
| Action | Impact | Where |
|---|---|---|
| Download and review usage reports regularly | Ongoing | Workspace Settings → Usage |