The Configuration YAML
Prefer using the UI?You can configure your entire auto-annotation pipeline through the visual editor - no YAML required. Navigate to the Interaction Types screen, select an interaction type, and click Edit YAML to open the visual editor. Any changes you make in the UI are reflected in the YAML and vice versa. See Configuring Auto Annotation in the UI.
The reference below is for users who prefer to work with YAML directly - useful for version control, automation, or advanced configurations.
Properties-Based Annotation
Properties' scores play a crucial role in evaluating interactions. The structure for property-based annotation includes the following key options:
- Annotation: The label assigned to samples that meet the specified conditions.
- Relation Between Conditions: Determines whether all conditions (AND) or any condition (OR) must be satisfied.
- Operator: Defines how conditions are evaluated. This includes greater than (GT), greater equal (GE), less than (LT), and less equal (LE) for numerical properties, as well as equality (EQ), inequality (NEQ), membership in a set (IN, NIN), and overlap between sets (OVERLAP) for categorical properties.
- Value: The specific value to which the operator is applied. For example, for the GE operator, the value can be seen as a threshold, while for the IN operator, you would provide a set or list of values.
Example 1: The block shown below labels any samples as 'bad' if they meet at least one property condition. For instance, if the 'Toxicity' score of the output is greater than or equal to 0.96, the interaction is annotated as bad.
- type: property
annotation: bad
relation_between_conditions: OR
conditions:
- property_name: Grounded in Context
operator: LE
value: 0.1
- property_name: Toxicity
operator: GE
value: 0.96
- property_name: PII Risk
operator: GT
value: 0.5Example 2: The block shown below labels any samples as 'bad' if they meet both property conditions. For instance, if the 'Text Quality' score of the output is lower than or equal to 2, and the property column_name is neither 'country' nor 'city', then the interaction is annotated as 'bad.'
- type: property
annotation: bad
relation_between_conditions: AND
conditions:
- property_name: Text Quality
operator: LE
value: 2
- property_name: column_name
operator: NIN
value: ['country', 'city']Similarity-Based Annotation
Using the similarity mechanism is useful for auto annotation of an evaluation set during regression testing. The similarity score ranges from 0 to 1 (1 being identical outputs) and is calculated between the output of a new sample and the output of previously annotated samples with the same user interaction id, if such samples exist.
Example: If an output closely resembles a previously annotated response (with a similarity score of 0.9 or higher) that shares the same user interaction id, it will copy its annotation.
- type: similarity
annotation: copy
condition:
operator: GE
value: 0.9Deepchecks Evaluator-Based Annotation
The last block is the Deepchecks Evaluator, a high-quality annotator that learns from your data.
- type: Deepchecks EvaluatorUpdating the Auto Annotation YAML
The auto-annotation YAML configuration is located on the Interaction Types page. To download the current configuration for a specific interaction type, click "Download as YAML."
Each interaction type has its own set of properties and a dedicated auto-annotation YAML that applies only to interactions of that type. Session annotations are an aggregation of the annotations from the interactions they contain.
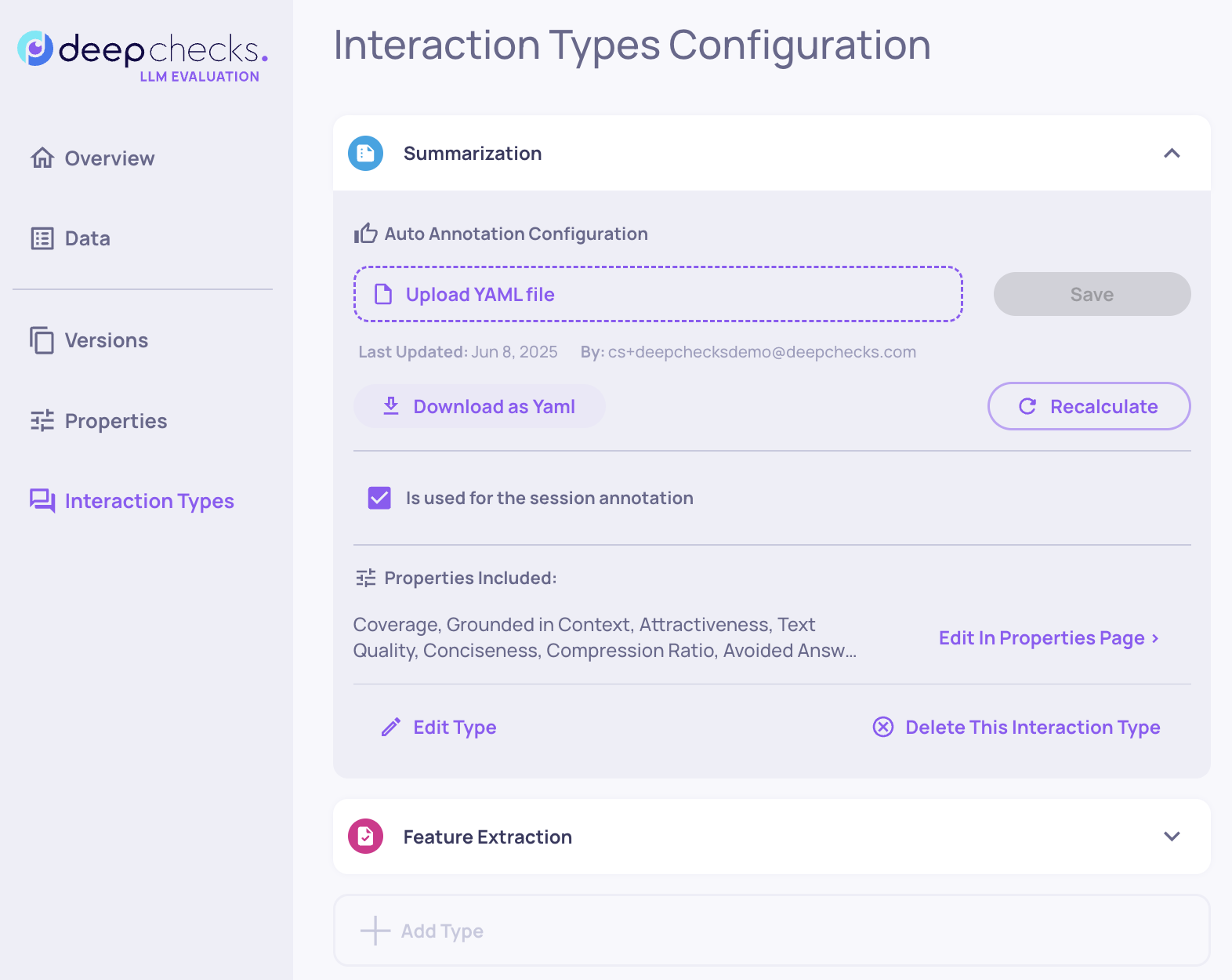
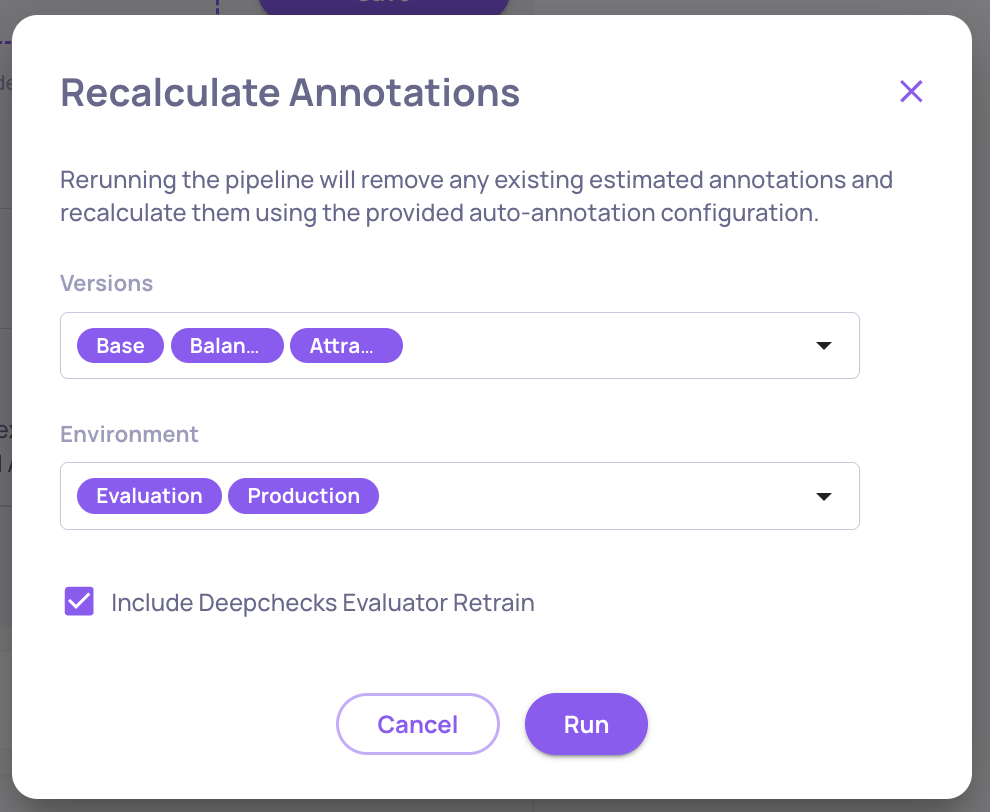
After downloading and editing the YAML-ideally following the suggested flow-upload it in the relevant section of the page and click "Save." Deepchecks will validate the YAML structure and prompt you to confirm whether you’d like to re-calculate auto annotations using the new configuration. We recommend re-calculating annotations for all relevant versions to ensure a fair comparison-so you're comparing apples to apples.
Note: Re-calculating auto annotations does not consume additional DPUs, since no new property values are computed-only the aggregation logic for scoring is updated.