Compare Between Versions
One of the foundational steps in improving our LLM-based application is comparing its various outputs to identify the optimal configurations for enhanced performance.
This can be done in Deepchecks using three comparison options: high-level multi-version comparison, the granular interaction comparison flow, or by exporting a comparison CSV. We’ll walk through each method using the GVHD demo use case as an example.
High-Level Multi-Version Comparison
Use high-level metrics to quickly identify the best version, including the overall score, key property averages, and tracing metrics like latency and token usage. These insights are powered by Deepchecks’ built-in, user-defined, and prompt-based properties, together with the auto-annotation pipeline that generates the aggregated version score.
All of this is available on the Versions page. A good place to start is sorting by “Score w. Est” (the average auto-annotation score), then reviewing the top versions’ property averages, latency, and token consumption.
In the GVHD demo, this makes the differences clear: v2_improved_IR shows a higher estimated score and stronger performance in the top three selected properties compared to v1.
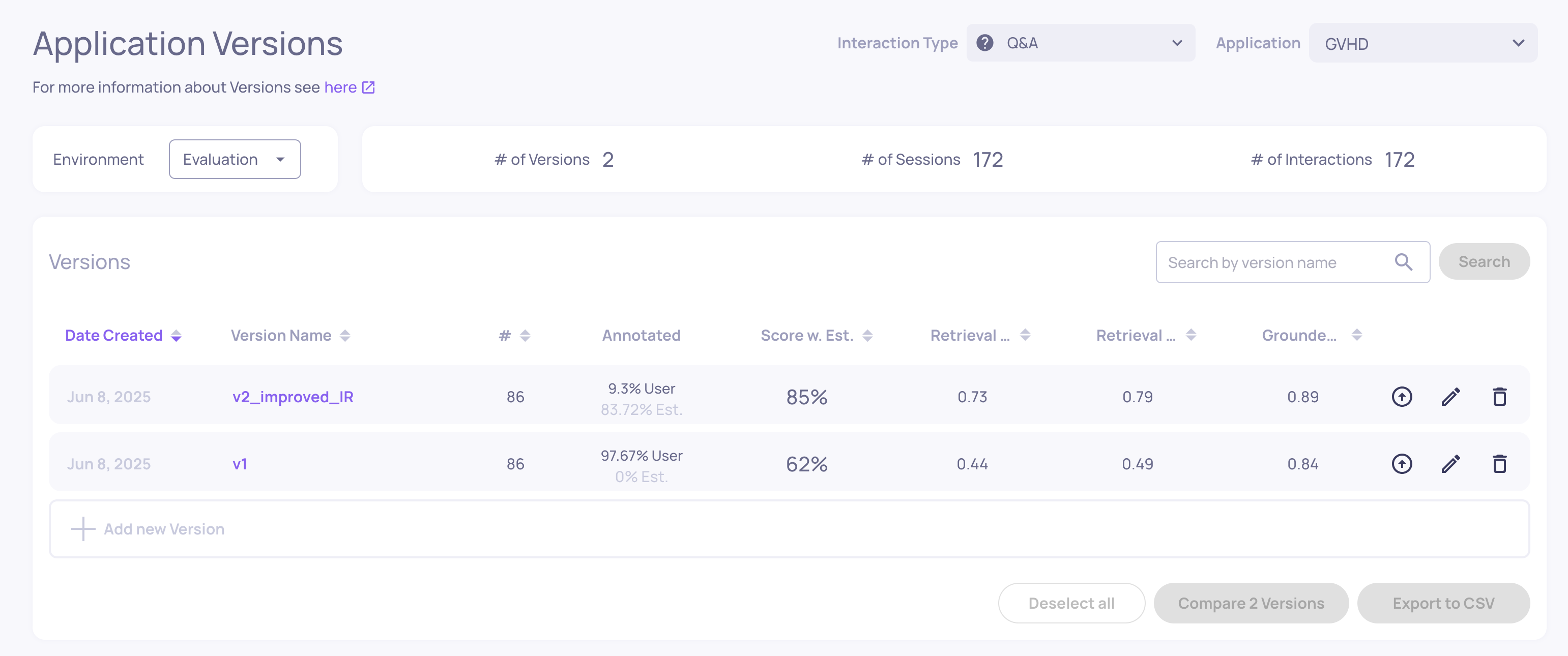
At the same time, v2_improved_IR uses more tokens, indicating a higher cost per run. This gives an immediate, high-level understanding of the quality-versus-cost tradeoff between versions.

Export Comparison CSV
This option lets you download a CSV that places the aggregated metrics of all selected versions side-by-side, enabling both quick, high-level visibility and deeper, offline analysis. The file includes key outputs such as dashboard properties, total scores, score breakdowns, and additional aggregated metrics.
The export becomes available in the UI once at least one version is selected. In this case, we select both versions and click “Export to CSV” to generate a clear, side-by-side comparison of their performance across a wide range of metrics.
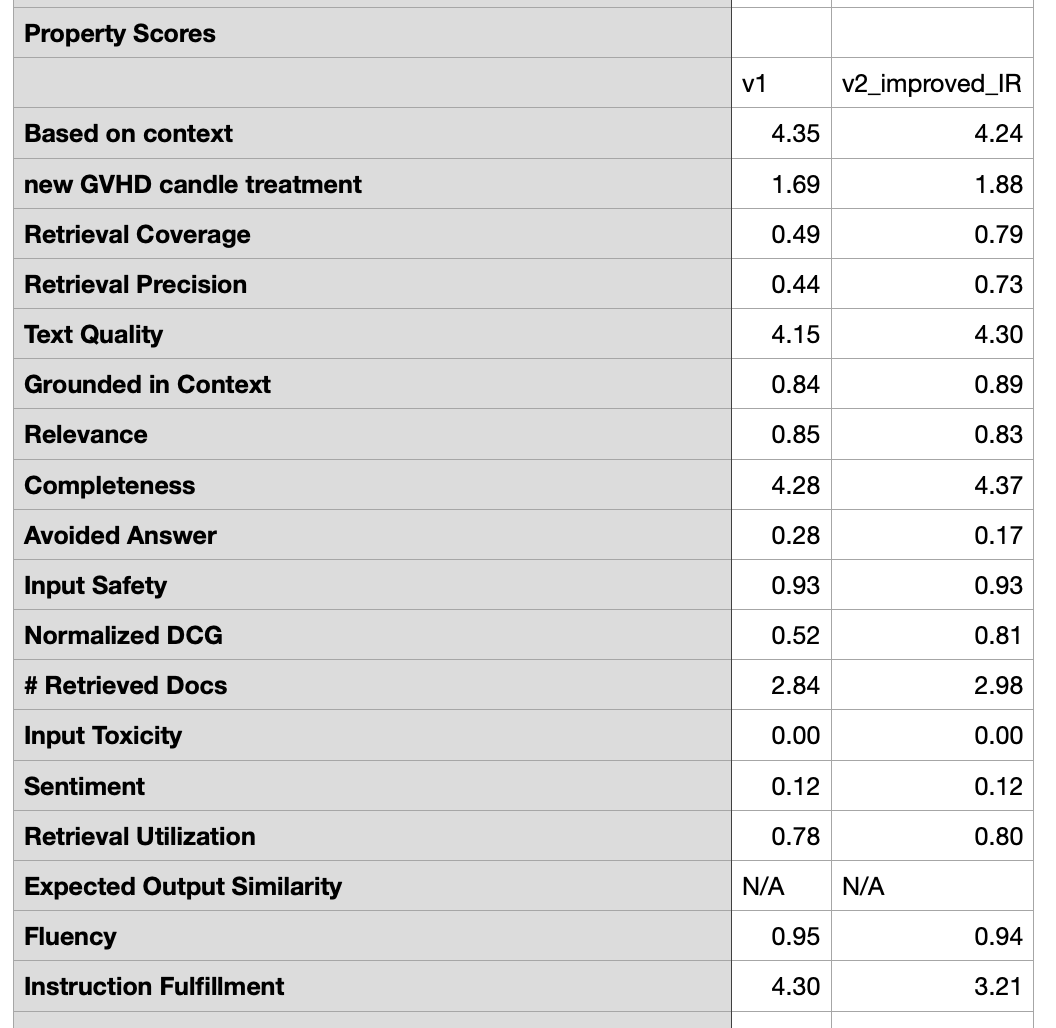
Side-by-side full CSV comparison of v1 and v2_improved_IR, showing that v2_improved_IR significantly outperforms v1 across most metrics, while also highlighting a few properties that declined after the change (Instruction Fulfillment)
Granular Interaction Comparison Flow
The Deepchecks’ Granular Version Comparison flow is essential for evaluating performance differences between versions. It enables users to identify overlapping interactions, by comparing samples with similar user_interaction_id, and determine where one version outperforms another.
For our GVHD demo use case, we will compare versions v1 and v2_improved_IR.
In the Versions screen, select exactly two versions and click “Compare 2 versions” to start the analysis.
For more information check out the Version Comparison page.
You can see the four types of comparisons available in Deepchecks' Version Comparison panel in the GIF below:
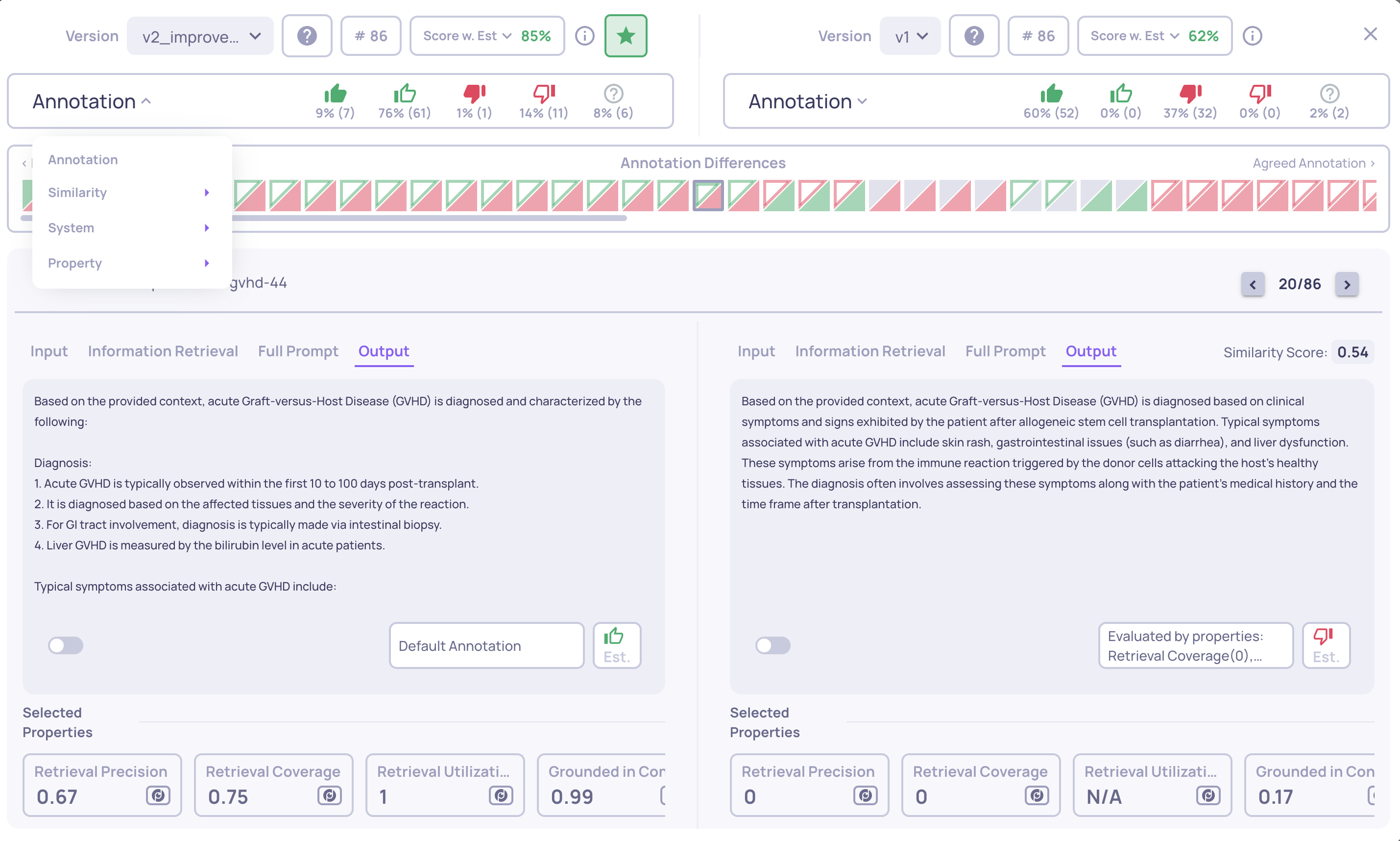
The four comparison types in the version comparison flow - Annotation focused, Similarity focused, System metrics focused and Property focused
Note: In all comparison panels, interactions with the most divergent scores or annotations are positioned on the left side of the interaction bar, while those with the most similar outputs are on the right.
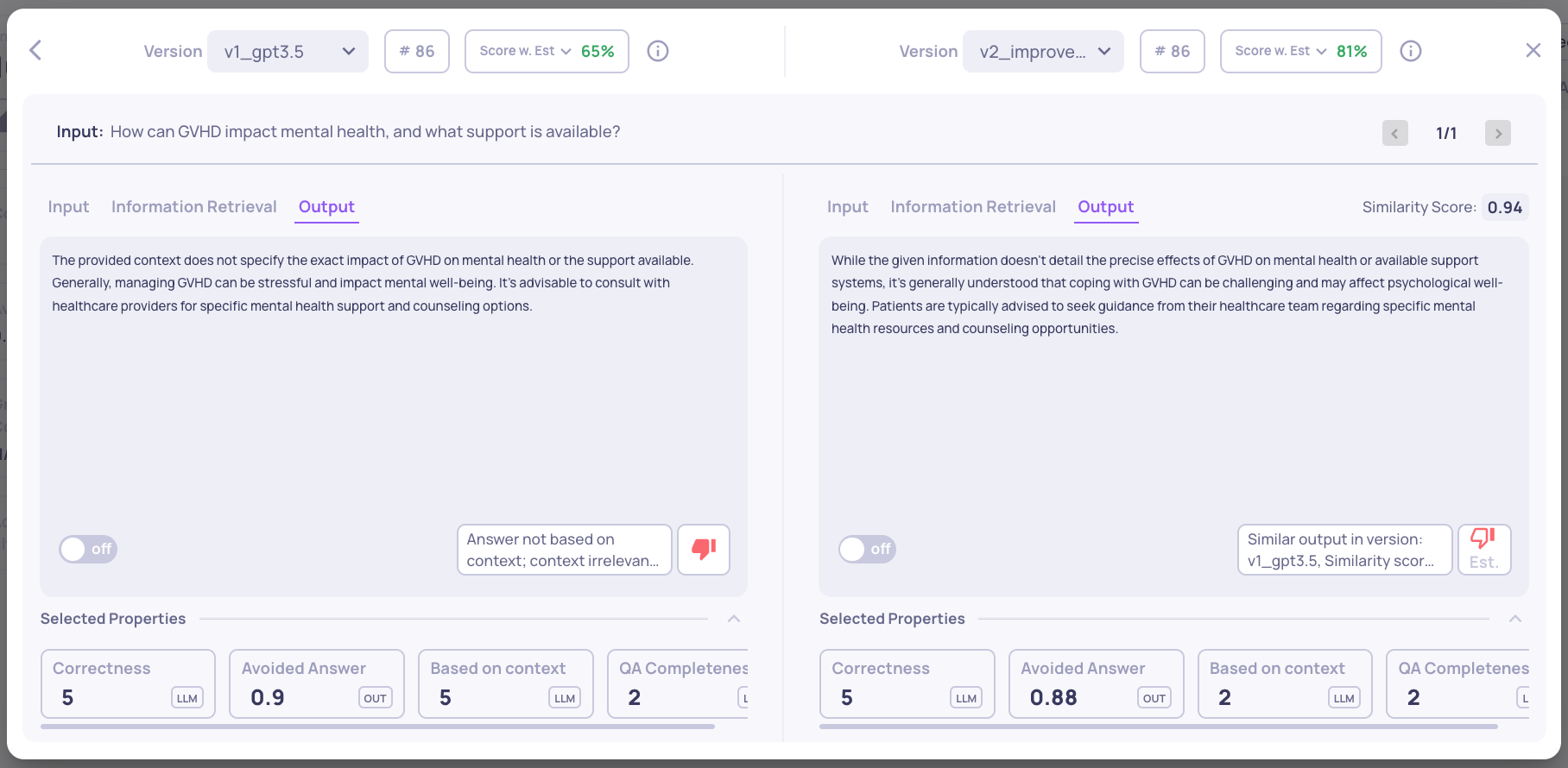
Lets compare a sample in our GVHD application:
-
qa-medical-gvhd-29: In this example, version v2_improved_IR received a “bad” auto-annotation due to high similarity with the output in version v1. Despite the different contexts provided to the LLM, as shown in the “Information Retrieval” tab, the outputs in the two versions were similar enough to receive the same annotation.