Evaluate an Agentic pipeline
End-to-end guide to evaluating multi-step agentic workflows in Deepchecks - from configuring deployments and generating test data, through automated simulation, to component-level evaluation and root-cause analysis.
Modern AI applications increasingly rely on agentic and multi-agent workflows - systems that reason, plan, delegate, call tools, and interact across multiple steps before producing an output. These workflows are powerful, but they also introduce complexity: where did the reasoning go wrong? Why did the agent pick this tool? Was the plan efficient? Which branch of the workflow created the failure?
Deepchecks provides a full suite of capabilities designed specifically for this: Know Your Agent (KYA), an end-to-end testing and evaluation pipeline that takes you from a deployed agent to a full diagnostic report.
The KYA Flow
The flow consists of the following stages:
- Deployment Configuration - Connect your agent's endpoint and configure execution settings
- Dataset Generation - Generate diverse test scenarios with AI, or curate them manually
- Simulation Execution - Run the dataset against your agent via the UI or SDK
- Logging & Instrumentation - Automatically capture every span, tool call, and LLM invocation via OpenTelemetry
- Agentic Evaluation - Score each component with built-in and custom properties
- Root-Cause Analysis - Pinpoint failing components and get categorized failure modes with actionable fixes
The sections below start with evaluation and analysis - the core of what makes KYA powerful - then walk through the setup and execution steps that feed into them.
Agentic Evaluation
Once your agent's execution data is logged - either through Auto-Instrumentation for supported frameworks (LangGraph, CrewAI, Google ADK, LangChain) or manually via Upload Agentic Data with the SDK - Deepchecks automatically evaluates every layer of the agent architecture independently. This is what separates KYA from simple observability: not just seeing what happened, but scoring each component on quality and operational metrics.
The Overview Dashboard
The overview screen gives you a top-down view of your agent's performance across every component. It displays:
- Overall version score - a single aggregated quality score for the entire version
- Component-level breakdown - individual scores for each agent, tool, LLM, and session-level metrics
- System metrics - cost, latency, and token usage aggregated per component
You can view these metrics at different levels of granularity. At the full version level, you see averages across all interactions. You can also filter by specific span names - for example, comparing your "Planning Agent" against your "Execution Agent" - to immediately identify which component is underperforming.
This multi-level view makes it possible to go from a high-level version score to the exact component dragging performance down, in a single screen.
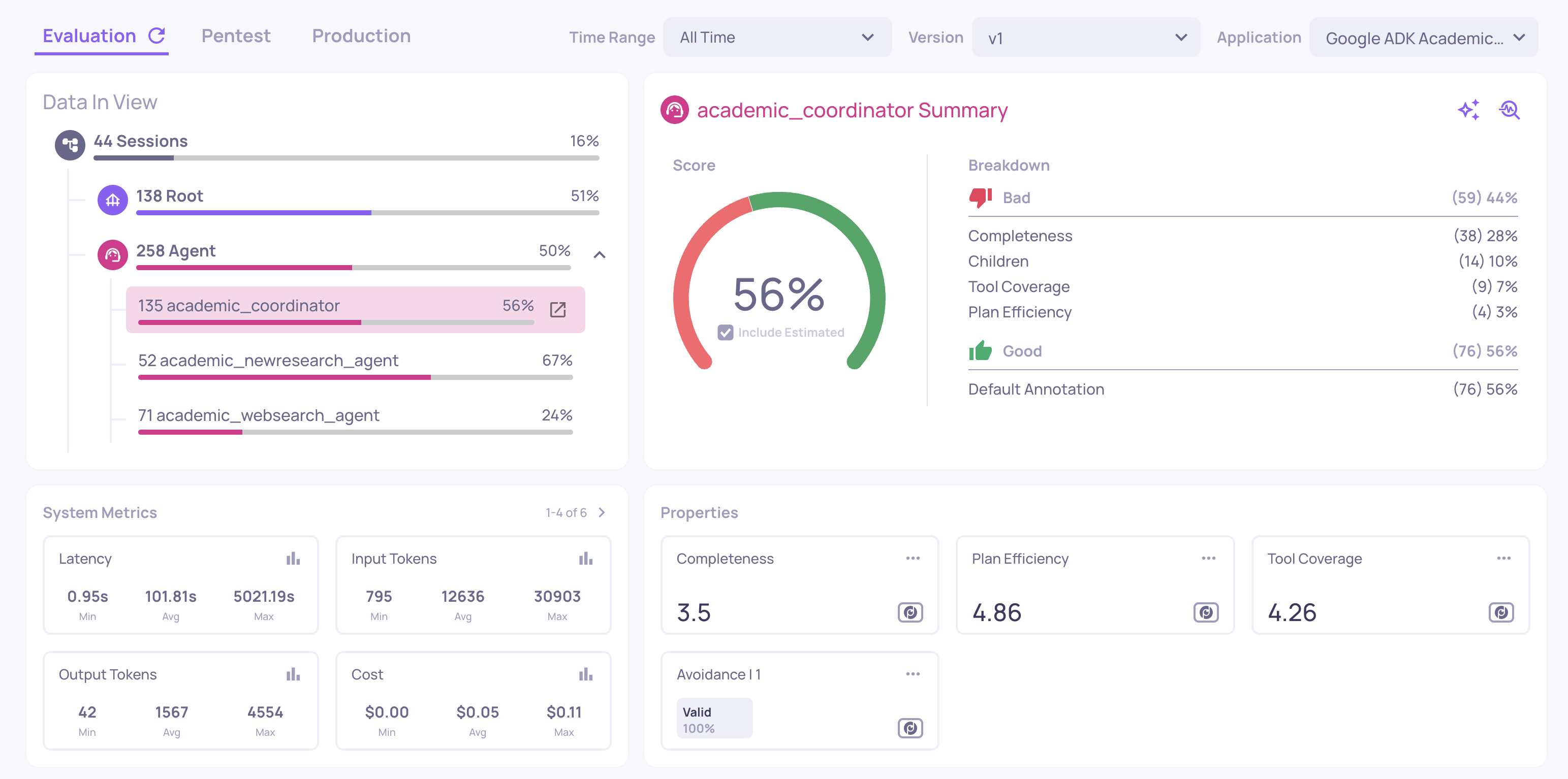
Sub-Component Analysis
From the overview, you can drill into any individual agent to see its sub-components in isolation. For example, clicking into a search agent would show its child tool executions and LLM calls - with scores and system metrics scoped only to that agent, not the entire version.
This scoping is what makes the analysis actionable. If your application has hundreds of LLM calls across multiple agents, you need to know which calls belong to which agent. Deepchecks tracks these relationships automatically, so when you analyze a specific agent's LLM performance, you're looking only at its calls - not noise from the rest of the system.
The system metrics view also catches operational anomalies that quality metrics alone would miss, such as a trace with abnormally high latency (suggesting a tool-calling loop) or zero input tokens (indicating the LLM was never invoked).
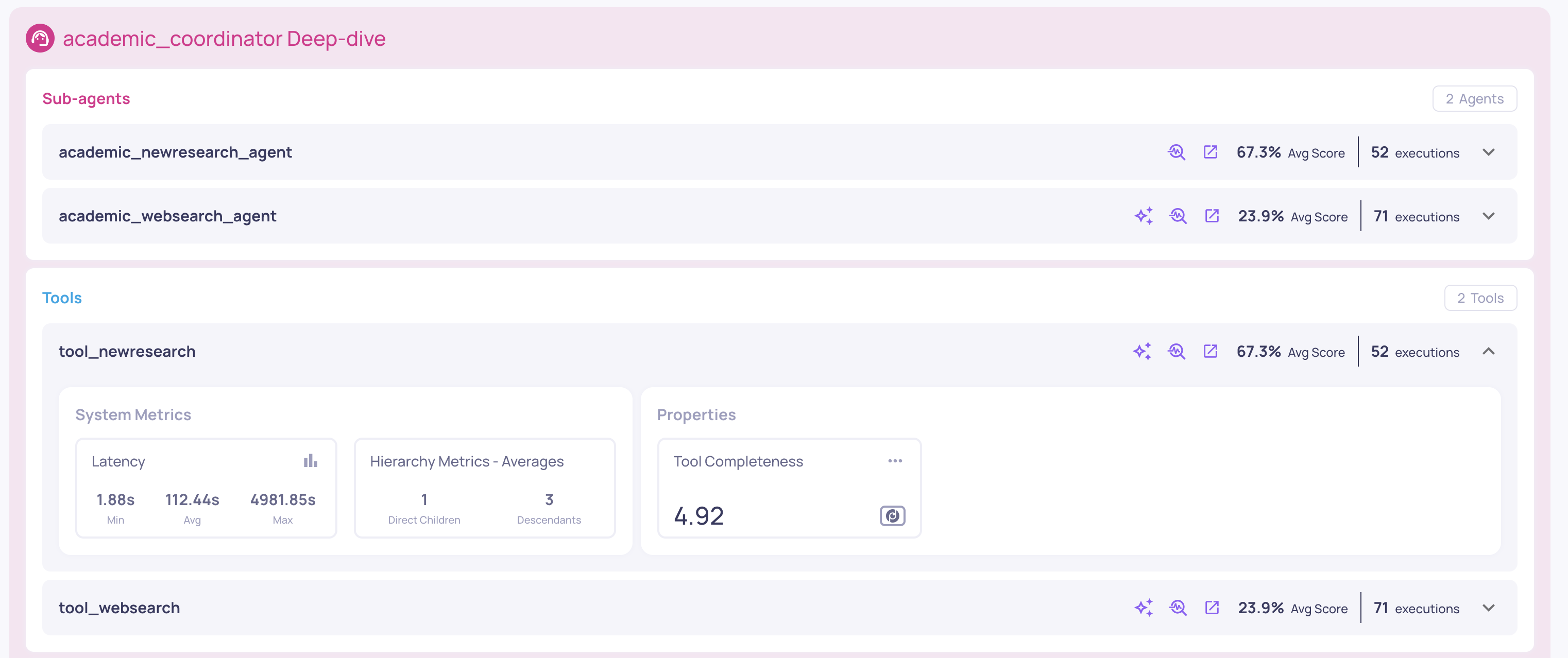
Inspection of the Coordinator's sub-agents, tools and LLM calls
Span-Level and Session-Level Evaluation
Drilling into any session reveals the full trace hierarchy - for example, a coordinator delegates to a sub-agent, which calls its LLM, invokes tools, processes results, and returns. Each span is independently evaluated on:
- Quality metrics (Properties) - Instruction Following, Reasoning Integrity, Tool Coverage, and more - each with natural-language reasoning, not just a number
- System metrics - latency, token count, and cost per span
If any score falls below a configurable threshold, the span is automatically flagged - no manual review needed.
Deepchecks also evaluates at the session level. A metric like Intent Fulfillment looks at the entire multi-turn conversation holistically. In many cases, individual spans score fine - but the session-level metric catches that the agent never actually delivered on the user's request. Span-level and session-level evaluation together surface problems that either one alone would miss.
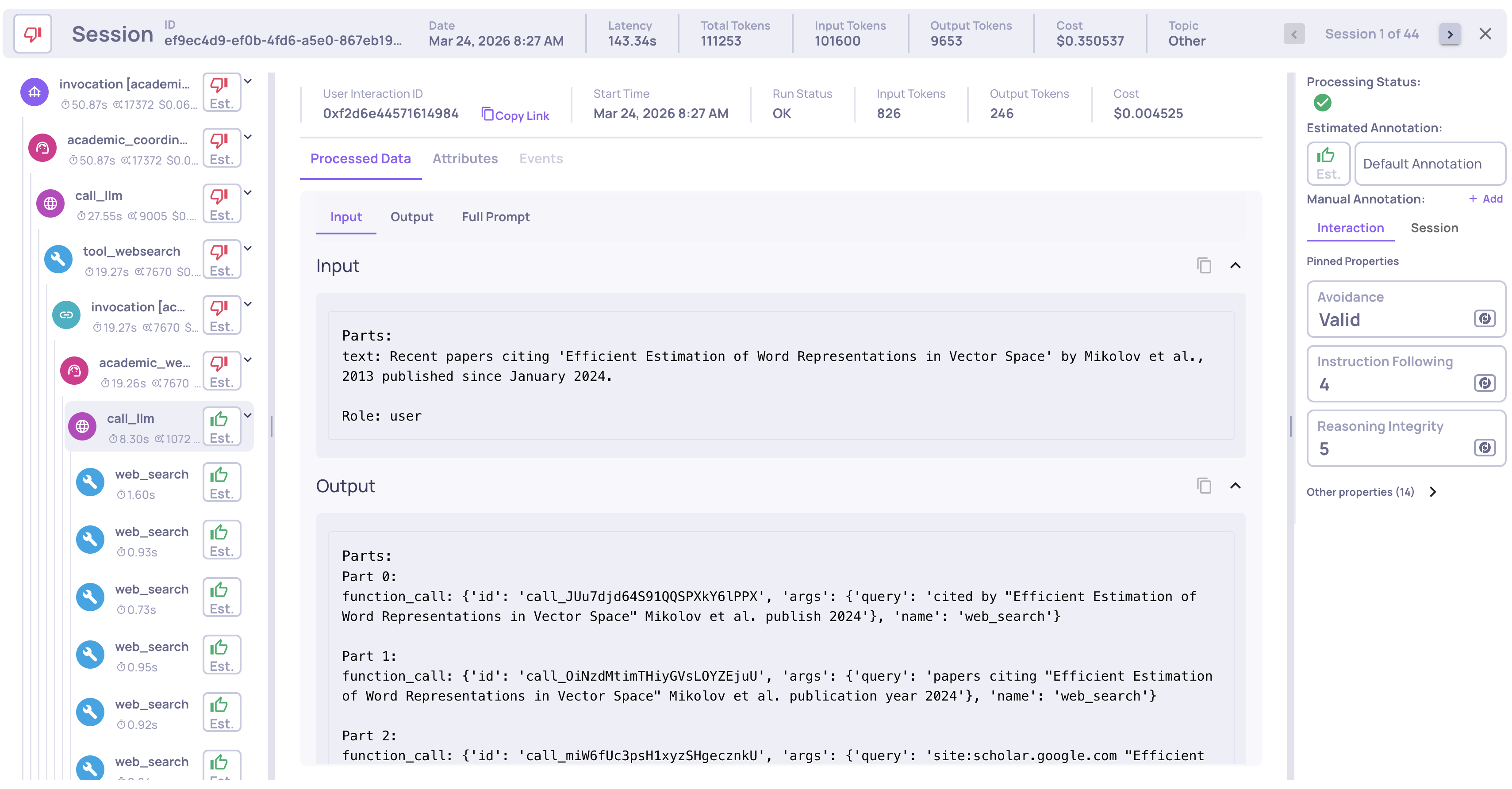
Single LLM call system metrics and properties
Built-In Agentic Properties
Deepchecks provides built-in properties designed specifically for evaluating Agent, Tool, and LLM interactions at the span (interaction) level:
| Interaction Type | Property | Description |
|---|---|---|
| Agent | Plan Efficiency | Scores 1-5 how well the agent's execution aligns with its stated plan. Evaluates whether the agent built a clear plan, carried it out correctly, and adapted when needed. |
| Agent | Tool Coverage | Scores 1-5 how well the set of tool responses covers the overall goal. Reflects whether the evidence gathered is sufficient to fulfill the agent's main query. |
| Agent | Tool Abuse | Scores 1-5 whether the agent used each tool and sub-agent efficiently. Evaluates redundancy, error adaptation, and progress between invocations. |
| Agent | Instruction Following | Scores 1-5 how well the agent adheres to all instructions, including system messages and user inputs. |
| Tool | Tool Completeness | Scores 1-5 how fully a single tool's output fulfills its intended purpose. |
| LLM | Instruction Following | Same as the Agent property, evaluated at the LLM call level. |
| LLM | Reasoning Integrity | Scores 1-5 how well the LLM reasons in a single step - context understanding, decision-making (tool choice), and logical consistency. |
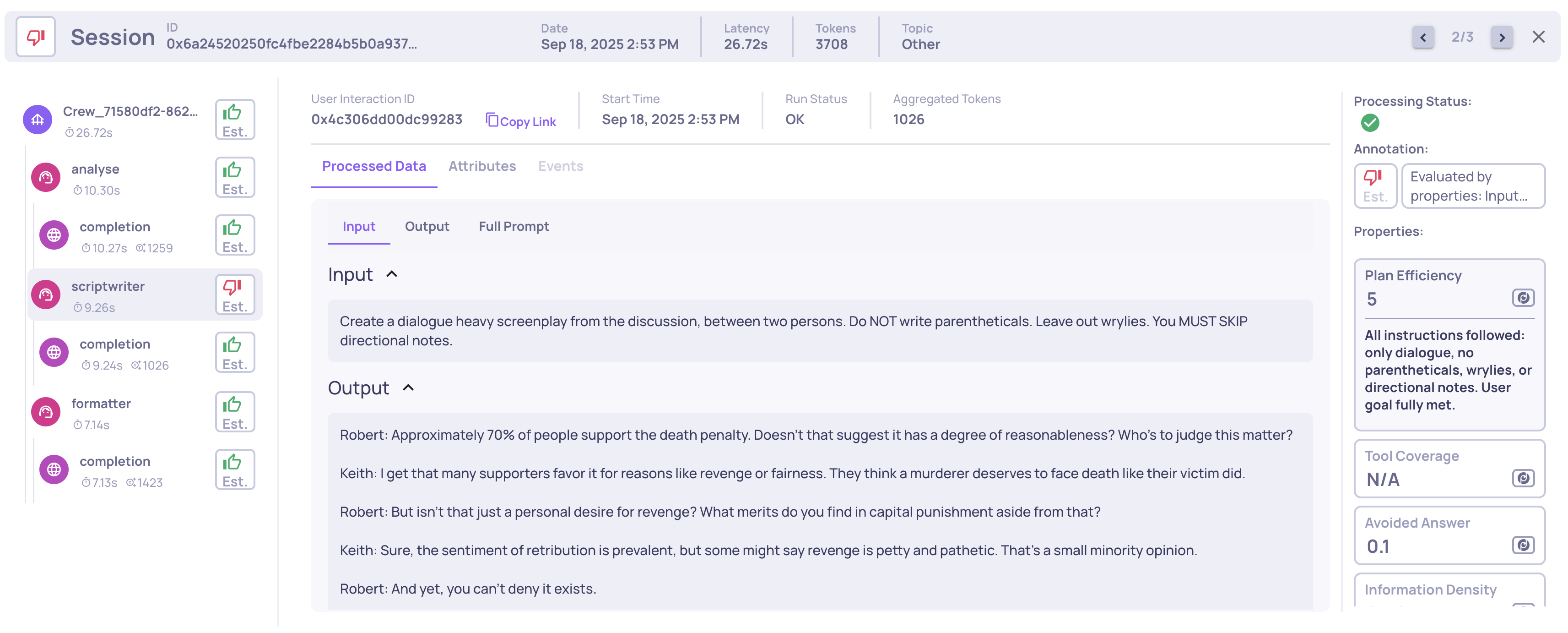
Example of a Planning Efficiency score and reasoning on an Agent span
These complement Deepchecks' general built-in properties, and you can also define custom prompt properties tailored to your specific agent.
Advanced Controls
Mapping Spans to Custom Interaction Types - If your system has custom steps that don't fit the default categories (e.g., a "Planning" agent and an "Executing" agent that should be evaluated differently), Deepchecks lets you map spans to custom interaction types. This updates the configuration immediately, enabling different properties, auto-annotation rules, and displays for each type. See the step-by-step guide.
Custom Prompt Properties Using Descendant Data - Agent and Root spans may need access to the data of their child spans - tool inputs, LLM outputs, retriever documents, etc. Deepchecks allows prompt properties to access all descendant spans, enabling root-level metrics and cross-span calculations.
Root-Cause Analysis
Knowing which component is failing is the first step. Root-cause analysis answers why, and gives you actionable next steps.
One-Click Failure Mode Analysis
With an underperforming component identified, click the "Analyze Failure Modes" button on the Overview screen.

Failure mode analysis can be performed on any level - from the entire version, through a specific agent, down to a specific tool used by an agent. Within seconds Deepchecks generates a structured report with:
- Categorized failure patterns - e.g., "Incomplete Retrieval", "Tool Misuse", "Inefficient Planning"
- Concrete failing examples from your data, with click-through to the exact span
- Actionable recommendations - specific suggestions derived from the actual failure patterns (e.g., tightening the agent's role description or adjusting search query formulation)
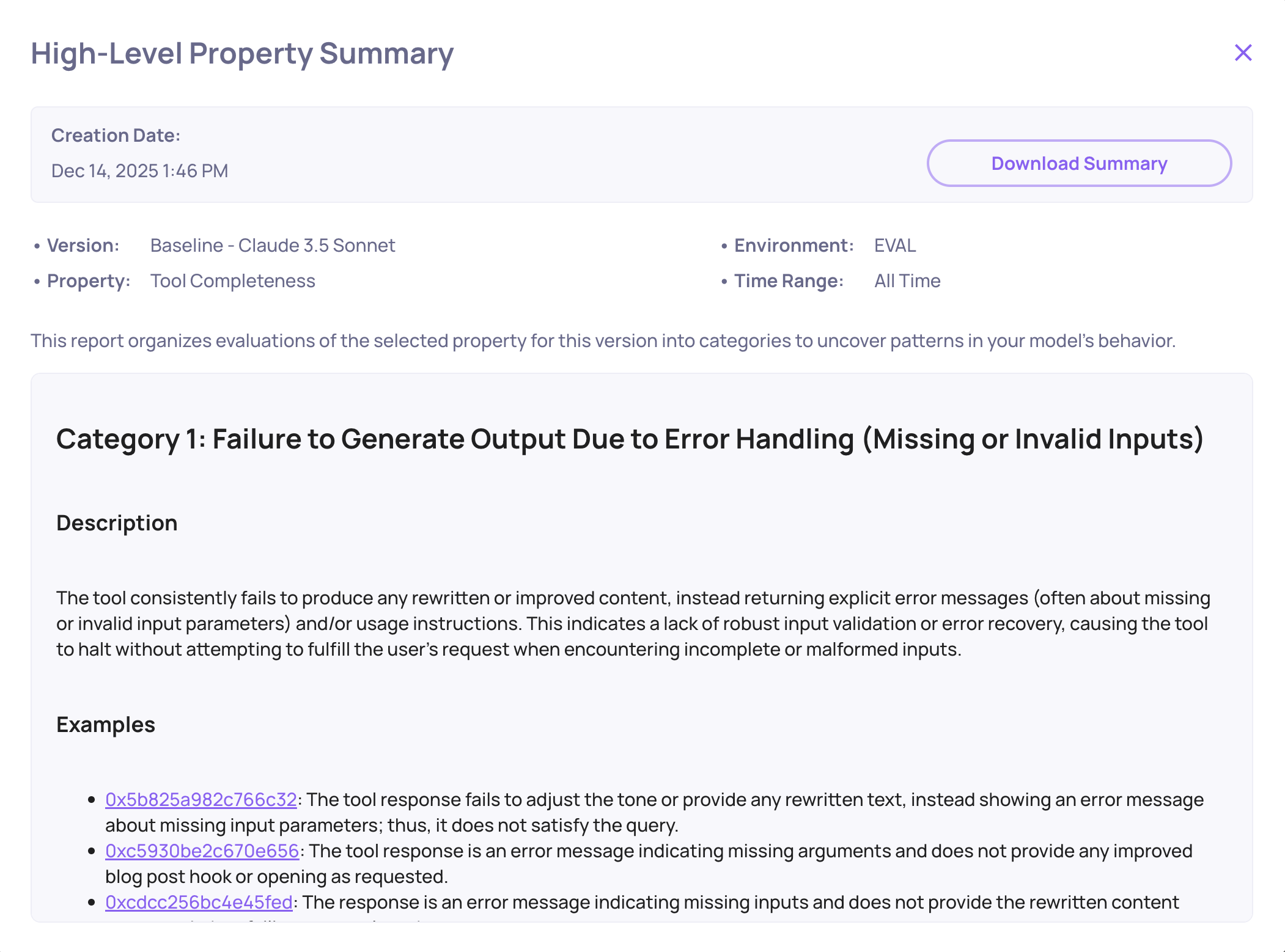
Tool Completeness failure mode analysis example
The Built-In Insights Feature
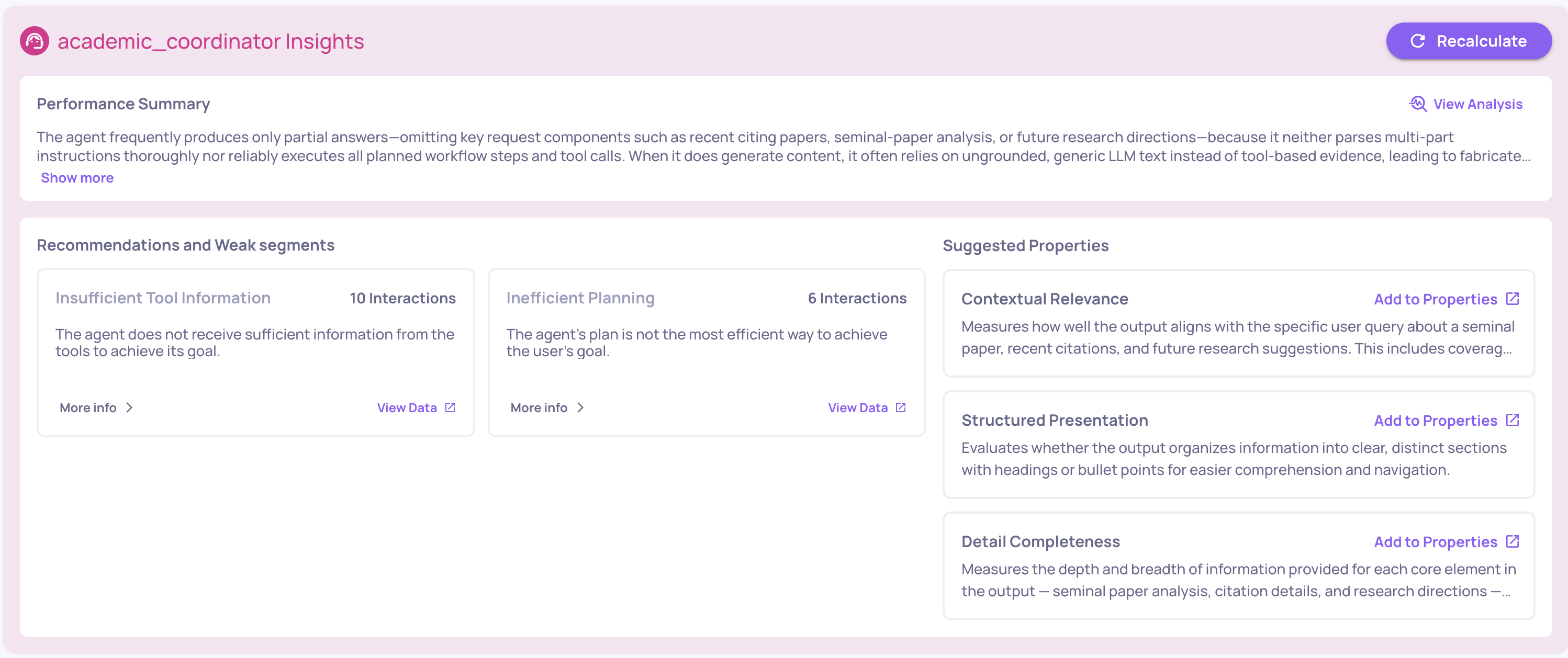
Once enough data has been collected, you can generate Insights on-demand from the Overview screen.

Insights provide a structured analysis of your agent's performance across several dimensions:
- Performance Summary - a concise overview of your version's quality and operational metrics, highlighting key trends and the most impactful areas for improvement
- Weak Segments - automatically identifies clusters of interactions where performance drops, surfacing patterns you might not notice manually
- Recommendation Insights - actionable, specific suggestions derived from your agent's actual failure patterns - not generic advice, but targeted fixes like adjusting a sub-agent's role description or refining tool invocation logic
- Suggested Properties - recommends additional evaluation properties you should enable based on the patterns observed in your data, with a one-click option to create the suggested property
Insights can be recalculated at any time as more data flows in, so the analysis stays current as your agent evolves.
→ See Root Cause Analysis for the full RCA documentation.
What's next
- Run Agent Simulations (KYA) - proactively test your agent by configuring a deployment, generating test scenarios with AI, and running them at scale
- Configure Auto Annotation - tune thresholds and build annotation rules specific to your agent
- Run a Version Comparison - compare two agent implementations side by side
Updated 3 months ago