Building Your Initial Evaluation Set
Creating an initial evaluation set for LLM-based applications requires careful attention to data diversity, relevance, and quality. Here’s how to gather the right inputs for your evaluation set.
TL;DR: A good evaluation set needs at least 50 samples of production representative user inputs along side expected outputs.
Define Scope and Requirements
Start by clearly defining the purpose and scope of the evaluation set:
- What tasks will the application perform (e.g., report generation, classification, question answering)?
- Identify typical and edge cases the your app will encounter in production, such as specialized topics, languages, or formats.
- Based on your current understanding of your application common error modes, make sure to include inputs that are likely to trigger them.
Collect Representative Data
The data you collect should closely reflect the real-world environment where the LLM will operate. Consider these sources:
- Real production data from users - the gold standard, but usually requires a working beta to gather.
- Expert-written or synthetic data, created by domain experts or product owners who understand common user flows.
- Public datasets that resemble your use case. These often need filtering to retain only the most relevant inputs.
No matter the source, your dataset will need postprocessing and thoughtful sampling to ensure it mirrors the production environment across key dimensions, while still including rare but important edge cases. These dimensions typically include topic diversity, variations in input style and format, and a range of task difficulty, but additional dimensions may apply depending on your specific use case.
Deepchecks Properties and Topics mechanisms can help measure the diversity of the evaluation set inputs across different dimensions. More on that in Measuring Evaluation Set Quality.
Automatic Evaluation Set Generation
Given RAG use cases where an initial evaluation set doesn't exist, Deepchecks offers an option of utilizing the underlying documents to be used for retrieval to assist with generating evaluation set inputs. For this workflow, follow the following steps:
-
Click on the "Generate Data" button at the bottom of the left bar:

-
Follow the instructions in the pop-up window, including writing general guidelines for the input generation, a description of the LLM-based app being evaluated and either links or files with the underlying documents to be used by the RAG system:
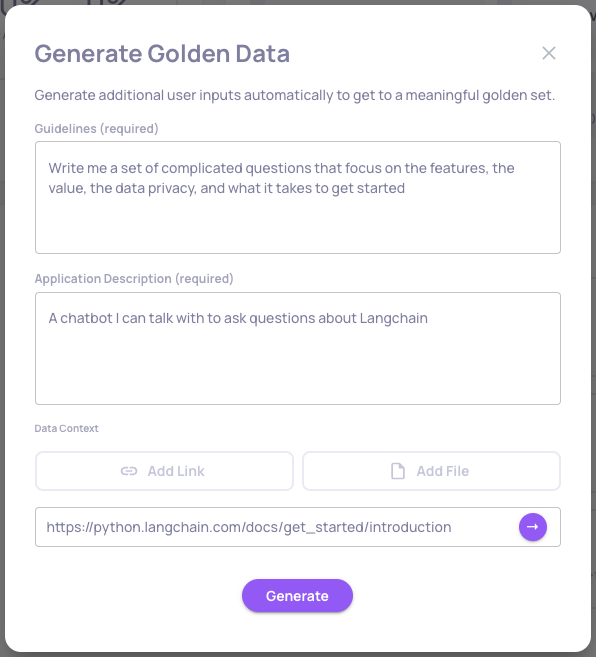
A pop-up window for generating an evaluation (=golden) set. In this example, we're simulating a "talk with my docs" example for Langchain's documentation.
Collect High Quality Outputs (Optional)
While not required, collecting high-quality outputs (ideal or reference responses to the representative inputs) is a smart investment for evaluating future model versions.
These outputs provide a consistent baseline for comparing models over time. They enable automatic evaluation using metrics like Expected Output Similarity, support manual review by giving human evaluators a clear reference, and set a reference for what can be achieved in different key properties.
Good sources include expert-written responses, high-quality model completions that have been manually reviewed and optimized, or trusted answers from existing systems. To be effective, outputs should meet your defined evaluation criteria, achieve high scores on the relevant Properties and aligned with your application’s tone and standards.
Uploading Into Deepchecks
For uploading your evaluation set into the deepchecks platform see here.
Updated 3 months ago