LangGraph
Deepchecks integrates with LangGraph to provide tracing, evaluation, and observability for agents and their interactions across the LangGraph workflow.
Deepchecks integrates seamlessly with LangGraph, letting you capture and evaluate your LangGraph workflows. With our integration, you can collect traces from LangGraph interactions and automatically send them to Deepchecks for observability, evaluation, and monitoring.
How it works
Data upload and evaluation
Capture traces from your LangGraph interactions and send them to Deepchecks for evaluation.
Instrumentation
We use OTEL + OpenInference to automatically instrument LangGraph. This gives you rich traces, including LLM calls, tool invocations, and agent-level spans within the graph.
Registering with Deepchecks
Traces are uploaded through a simple register_dc_exporter call, where you provide your Deepchecks API key, application, version, and environment.
Viewing results
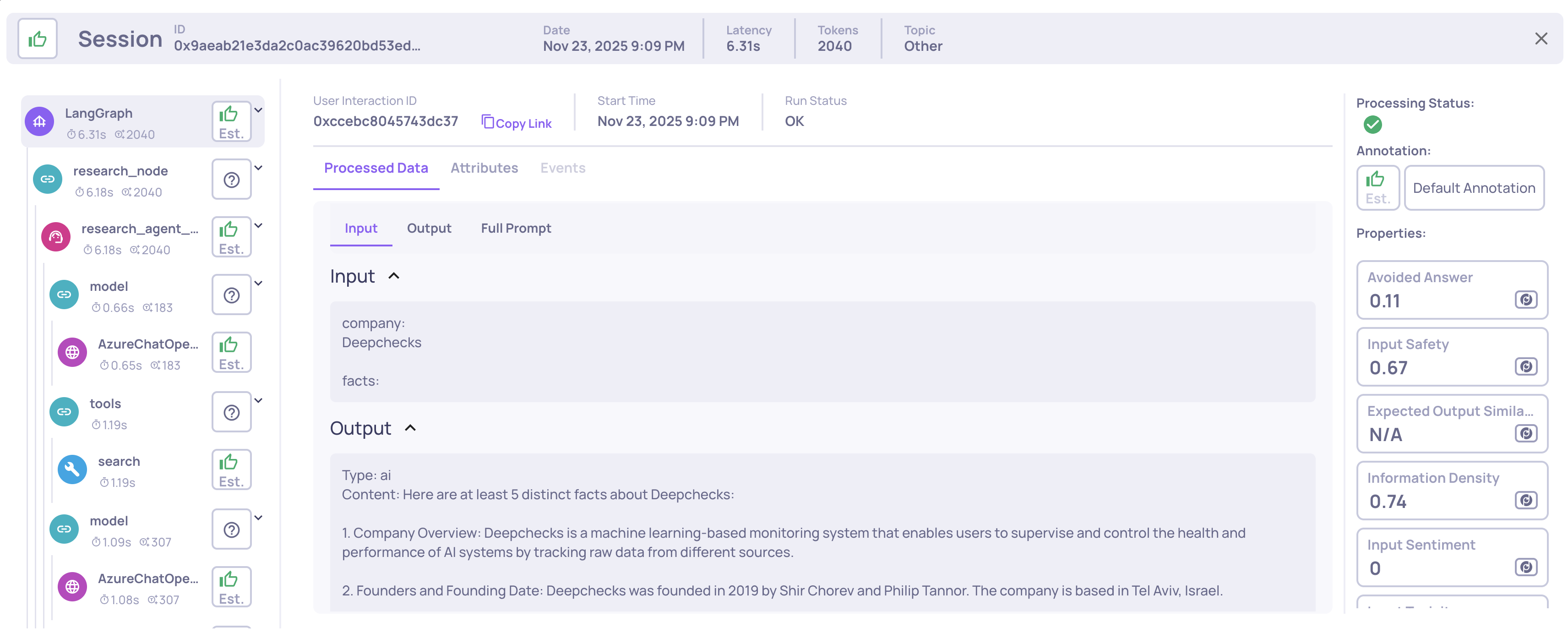
Once uploaded, you’ll see your traces in the Deepchecks UI, complete with spans, properties, and auto-annotations. See here for information about multi-agentic use-case properties.
Package installation
pip install "deepchecks-llm-client[otel]"Instrumenting LangGraph
from deepchecks_llm_client.data_types import EnvType
from deepchecks_llm_client.otel import LanggraphIntegration
# Register the Deepchecks exporter
LanggraphIntegration().register_dc_exporter(
host="https://app.llm.deepchecks.com/", # Deepchecks endpoint
api_key="Your Deepchecks API Key", # API key from your Deepchecks workspace
app_name="Your App Name", # Application name in Deepchecks
version_name="Your Version Name", # Version name for this run
env_type=EnvType.EVAL, # Environment: EVAL, PROD, etc.
log_to_console=True, # Optional: also log spans to console
)Best practices for LangGraph to get great Deepchecks evaluation
Deepchecks will display whatever span metadata you emit and will supply great agent evaluations on the Root level. However, if you'd like to get more granular evaluations for each agent within your pipeline, we suggest you follow these LangGraph structuring patterns:
Two ways to represent an “agent” in LangGraph and which to choose
LangGraph supports both of these patterns; both run fine, but they differ in observability and how easily Deepchecks can apply built-in analysis:
Agent implemented inline inside the parent graph (graph-without-subgraph) - not recommended
- Description: the LLM nodes, Tool nodes, and conditional edges that form the agent’s internal loop are added directly to the main graph as regular nodes and edges. This is the simple, explicit approach: you see every internal step of the agent as a first-class node in the parent graph.
- Pros: full visibility of every internal step in the parent graph; simple to prototype.
- Cons: agent “logical unit” is not encapsulated - the parent graph mixes agent internals with higher-level workflow steps, which makes it harder for Deepchecks to treat the entire agent as a single logical interaction when producing built-in, agent-level properties (e.g., agent-level correctness, planning quality).
Agent encapsulated as a subgraph (graph-within-graph) - RECOMMENDED
- Description: create a dedicated subgraph that contains the agent’s LLM nodes, Tool nodes, and conditional edges; then add that subgraph as a node in the parent graph (or invoke the subgraph from a node). LangGraph explicitly supports subgraphs (a graph used as a node in another graph) and documents patterns for invoking or embedding subgraphs.
- This structure allows the parent graph to treat the agent as a single logical step while preserving full internal detail, which enables Deepchecks to recognize the node as an Agent interaction type, produce richer agent-level metrics, and maintain consistent evaluation across runs.
- In cases where an agent contains another agent, apply the same pattern recursively: encapsulate the inner agent as a subgraph node within the outer agent’s subgraph.
Recommendation: Prefer encapsulating agent logic as a subgraph (graph-within-graph) when you want Deepchecks’ built-in agent-level properties and straightforward evaluation across versions.
Naming your agent subgraph so Deepchecks recognizes it as an Agent interaction type
After structuring your agent according to the first rule - encapsulating it as its own dedicated subgraph - you need to name that subgraph in a way that Deepchecks can reliably identify as an Agent.
To do this, name the subgraph using one of the following patterns:
*agent_graphagent_graph*
In other words, the subgraph’s name must include the word agent_graph and should be connected to another token (prefix or suffix).
Examples: agent_graph, chat_agent_graph, agent_graph_planner, etc.
Using this naming convention ensures that Deepchecks automatically maps the subgraph to the Agent interaction type and applies all relevant agent-level configurations, properties, and visualizations.
Use LangChain inside LangGraph nodes for agent logic, tools, and LLM features
LangChain provides mature abstractions for tools, ReAct agents, and structured output, while LangGraph handles the orchestration and control flow. Combining them - LangChain inside LangGraph - is the recommended best practice for building clean, maintainable, and production-ready graphs, and evaluating them with Deepchecks.
LangGraph Best PracticesUsing the listed best practices isn't a must. If you built your LangGraph application differently (e.g one flat graph without subgraphs for each agent), you'll still get great observability and evals. We suggest using these best practices to have more granularity on your evals and to simplify RCA processes.
Example
This example shows how to build a LangGraph workflow that performs automated company research using a ReAct-style agent subgraph - created and named according to Deepchecks best practices - along with a structured-output extraction step. It also demonstrates how to enable full Deepchecks telemetry logging, allowing you to inspect the agent’s behavior, tool calls, and spans in the Deepchecks interface.
import os
from typing import Annotated
from langchain_community.utilities import GoogleSerperAPIWrapper
from langchain_core.messages import HumanMessage
from langchain_core.tools import StructuredTool
from langchain_openai import AzureChatOpenAI
from langchain.agents import create_agent
from langgraph.graph import END, START, StateGraph
from langgraph.graph.message import add_messages
from typing_extensions import TypedDict
from pydantic import BaseModel, Field
from dotenv import load_dotenv
from deepchecks_llm_client.data_types import EnvType
from deepchecks_llm_client.otel import LanggraphIntegration
load_dotenv()
# Can change to any other llm
llm = AzureChatOpenAI(
api_key=os.getenv("AZURE_OPENAI_API_KEY"),
api_version=os.getenv("AZURE_OPENAI_API_VERSION", "2024-02-01"),
azure_endpoint=os.getenv("AZURE_OPENAI_ENDPOINT"),
deployment_name="gpt-4.1-mini", # your deployment name for gpt-4.1-mini
)
# Initialize Serper search tool
search = GoogleSerperAPIWrapper(
serper_api_key=os.environ.get("SERPER_API_KEY")
)
search_tool = StructuredTool.from_function(
func=lambda query: search.run(query),
name="search",
description="Search the web for information about companies. Use this to find facts about the company.",
)
# Configure deepchecks logging
tracer_provider = LanggraphIntegration().register_dc_exporter(
host=os.environ.get("DEEPCHECKS_HOST"),
api_key=os.environ.get("DEEPCHECKS_API_KEY"),
app_name="APP_NAME", # Need to create the app prior to logging!
version_name="VERSION_NAME",
env_type=EnvType.EVAL,
log_to_console=True,
)
# Create a research agent node - runs the research
# Practically this will be used as a sub-graph in the full end to end graph
react_agent = create_agent(
name="research_agent_graph", # Required for deepchecks to automatically detect this sub-graph as an Agent,
model=llm,
tools=[search_tool],
system_prompt="""You are a research assistant. Your goal is to gather at least 5 distinct facts about a company.
Instructions:
1. Use the search tool multiple times to gather comprehensive information
2. Search for different aspects: company overview, founders, products, funding, recent news, etc.
3. Continue searching until you have found at least 5 solid facts
4. Once you have 5+ facts, summarize what you found and stop
5. Be thorough - don't stop after just one search""",
)
# Build the main e2e execution graph
class ResearchState(TypedDict):
messages: Annotated[list, add_messages]
company: str
facts: list[str]
def research_agent_node(state: ResearchState):
"""Run the ReAct agent to gather information."""
if len(state["messages"]) == 0:
state["messages"] = [HumanMessage(content=f"Research {state['company']} and gather at least 5 distinct facts."
)]
result = react_agent.invoke(state)
return {"messages": result["messages"]}
# Extraction node - extracts facts using structured output
class CompanyFacts(BaseModel):
"""Extracted facts about a company from search results."""
facts: list[str] = Field(
description="List of distinct, factual statements about the company. Each fact should be a complete sentence."
)
llm_with_structured_output = llm.with_structured_output(CompanyFacts)
def extract_facts_node(state: ResearchState):
"""Extract structured facts from the research conversation."""
company = state["company"]
messages = state["messages"]
extraction_prompt = f"""Based on all the search results about {company}, extract all distinct facts you found.
Each fact should be a complete, standalone, verifiable sentence.
Review all the search results and extract every unique fact."""
try:
extracted: CompanyFacts = llm_with_structured_output.invoke(
messages + [HumanMessage(content=extraction_prompt)]
)
print(f"✓ Extracted {len(extracted.facts)} facts\n")
return {"facts": extracted.facts}
except Exception as e:
print(f"✗ Extraction error: {e}")
return {"facts": []}
# Build the graph and define the flow: START → Research Agent → Extractor → END
workflow = StateGraph(ResearchState)
workflow.add_node("research_node", research_agent_node)
workflow.add_node("facts_extraction", extract_facts_node)
workflow.add_edge(START, "research_node")
workflow.add_edge("research_node", "facts_extraction")
workflow.add_edge("facts_extraction", END)
# Compile the graph
research_app = workflow.compile()
# Run the application to gather facts about deepchecks
initial_state = {
"company": "Deepchecks",
"messages": [],
"facts": [],
}
research_app.invoke(initial_state)
Updated 5 months ago