Automatic Annotations
Deepchecks automatically labels every interaction as Good, Bad, or Unknown using a configurable pipeline - defined per interaction type.
Once properties are calculated on every interaction, the next step is turning those scores into actionable quality verdicts. Automatic annotations apply configurable rules to label each interaction as Good, Bad, or Unknown - so you can compare versions, filter by quality, and monitor trends without manual review.
Annotations are the bridge between raw property scores and the tools in Analyze & Improve: Root Cause Analysis, Version Comparison, and Production Monitoring all work from annotation labels.
How it works
Each interaction type in your application has its own independent annotation pipeline. A Q&A interaction, a Tool span, and an Agent span all need different signals to be judged Good or Bad, so Deepchecks lets you define a distinct pipeline for each type.
A pipeline is an ordered sequence of blocks evaluated top to bottom - the first block whose conditions match decides the annotation. Blocks can be based on property scores, similarity to previously annotated interactions, the annotations of child spans, or a built-in LLM evaluator that learns from your manual annotations. If no block matches, a default annotation is applied.

→ For the full walkthrough of block types, conditions, and pipeline design, see Configure Auto Annotation in the How To Guides.
Session annotations
A session is a complete multi-turn workflow - one or more interactions from one or more interaction types. Session annotations answer: was this whole conversation or workflow successful?
Which interaction types affect session annotations
The session annotation is derived only from the interaction types you designate as important. For example, in an agent workflow, the final generation step may matter more than intermediate tool calls.
In the interaction type configuration screen, the "Affects Session Annotation" checkbox controls this. All types are included by default. Disable it for any type whose annotations should not count toward the session verdict.
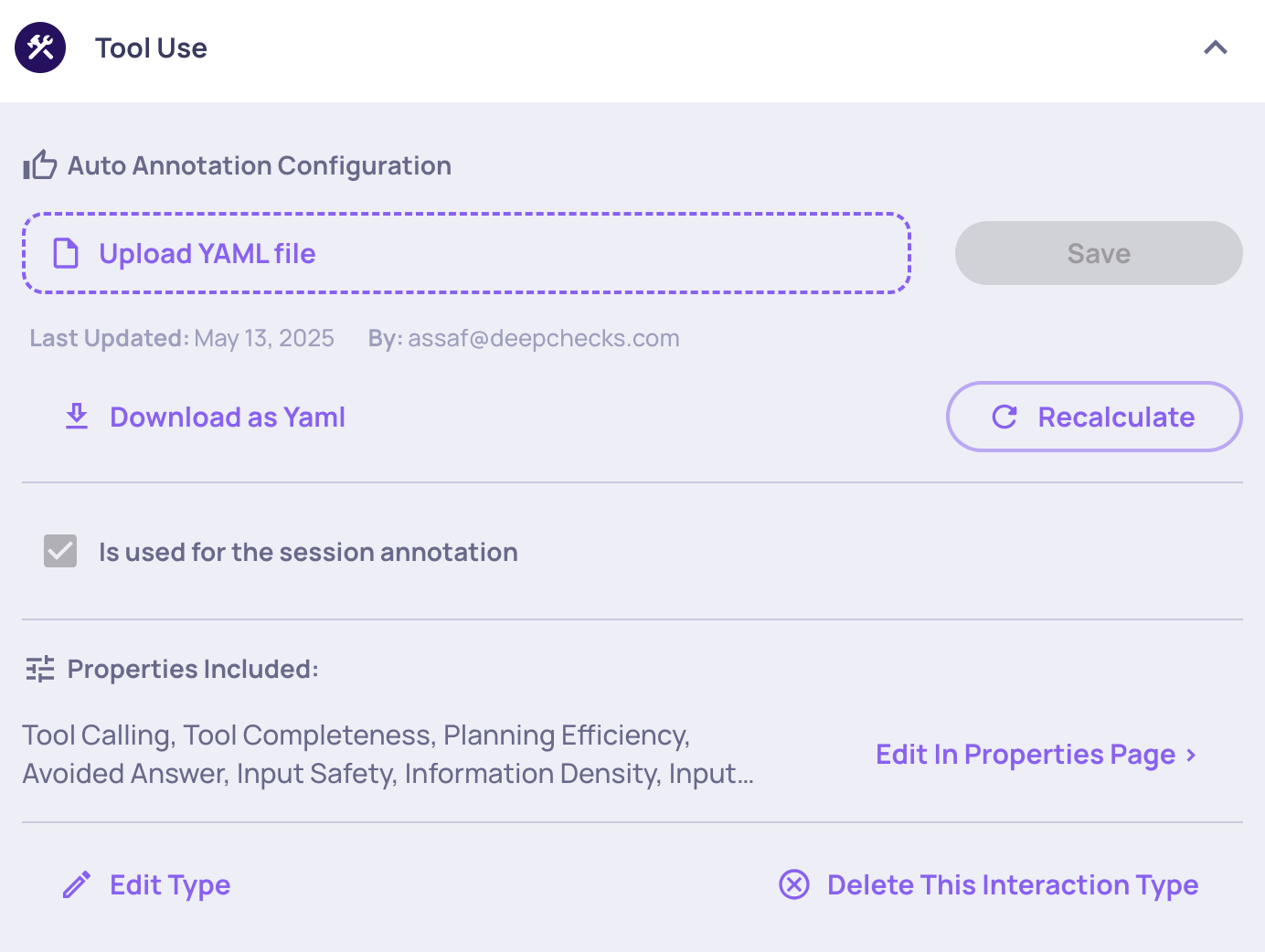
Tool-Use Interaction Type configured to affect the session annotation
How session annotations are calculated
Session annotations are Good, Bad, Pending, or Unknown, based on the interactions from types marked as "Affects Session Annotation":
| Result | Condition |
|---|---|
| Bad | Any included interaction is Bad |
| Pending | No Bad interactions, but at least one is Pending |
| Good | No Bad or Pending interactions, and at least one is Good |
| Unknown | None of the above conditions apply |
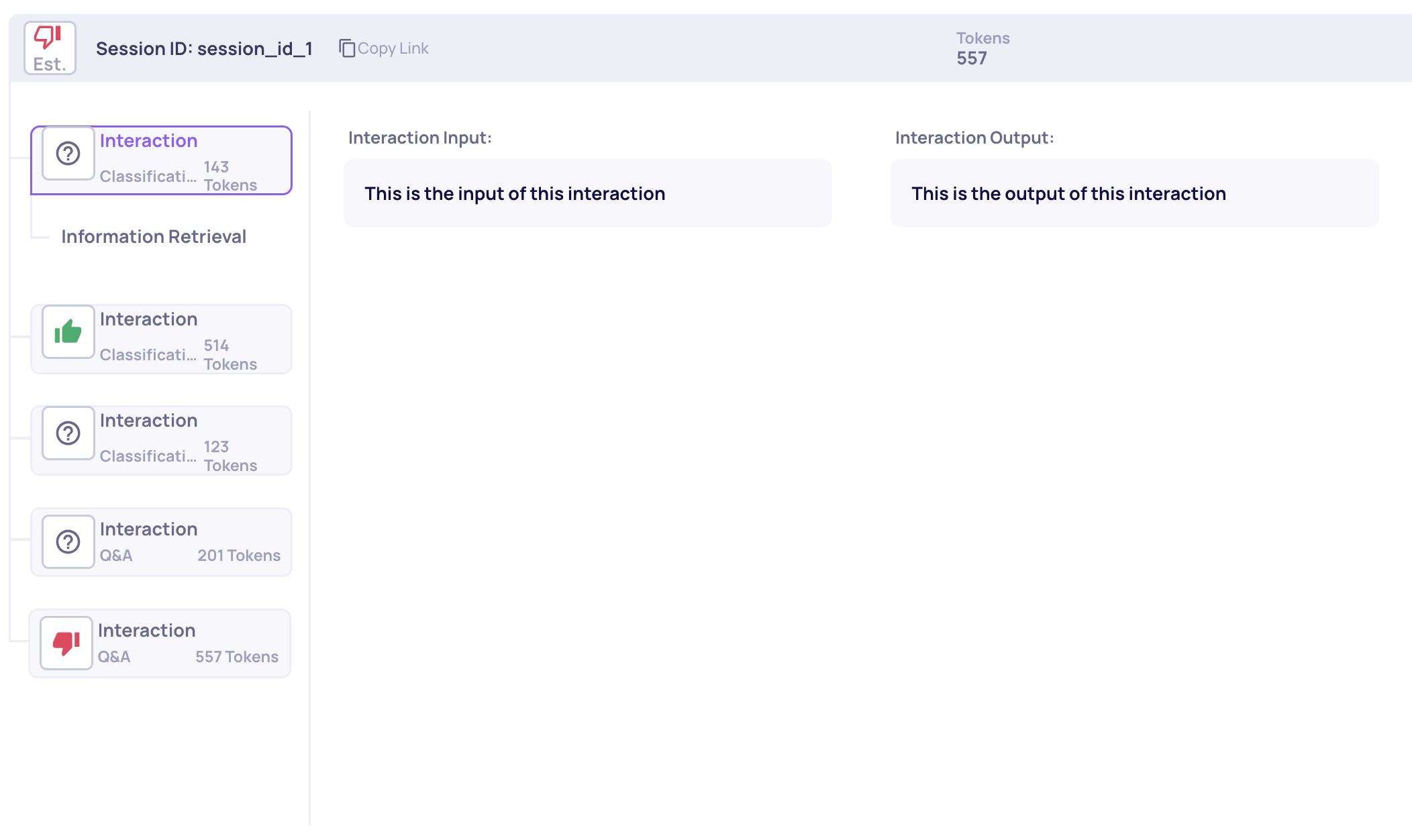
A session annotated Bad because a Q&A interaction (a flagged type) was annotated Bad
Manual annotations take precedence. If an interaction has been manually annotated, that label overrides the automatic one and is used in the session calculation.
Updated 3 months ago