RAG Use-Case Properties
Overview of the classification of documents and built-in retrieval properties on the Deepchecks app
Introduction
In a RAG (Retrieval-Augmented Generation) pipeline, the retrieval step is pivotal, providing essential context that shapes the subsequent stages and ultimately the final output. To ensure the effectiveness of this step, we have introduced specialized properties for thorough evaluation. The process for each interaction is divided into two key stages:
- Document Classification: An LLM is used to classify retrieved documents into distinct quality categories-Platinum, Gold, or Irrelevant-based on their relevance and completeness.
- Retrieval Property Calculation: Using the classifications from the first stage, various properties are computed for each interaction to assess performance and identify potential areas for enhancement.
Enabling Classification and Property CalculationIf you don't see document classification taking place, it means both the classification process and property calculations are disabled to prevent unintended use. To enable these features, navigate to the "Edit Application" flow in the "Manage Applications" screen.
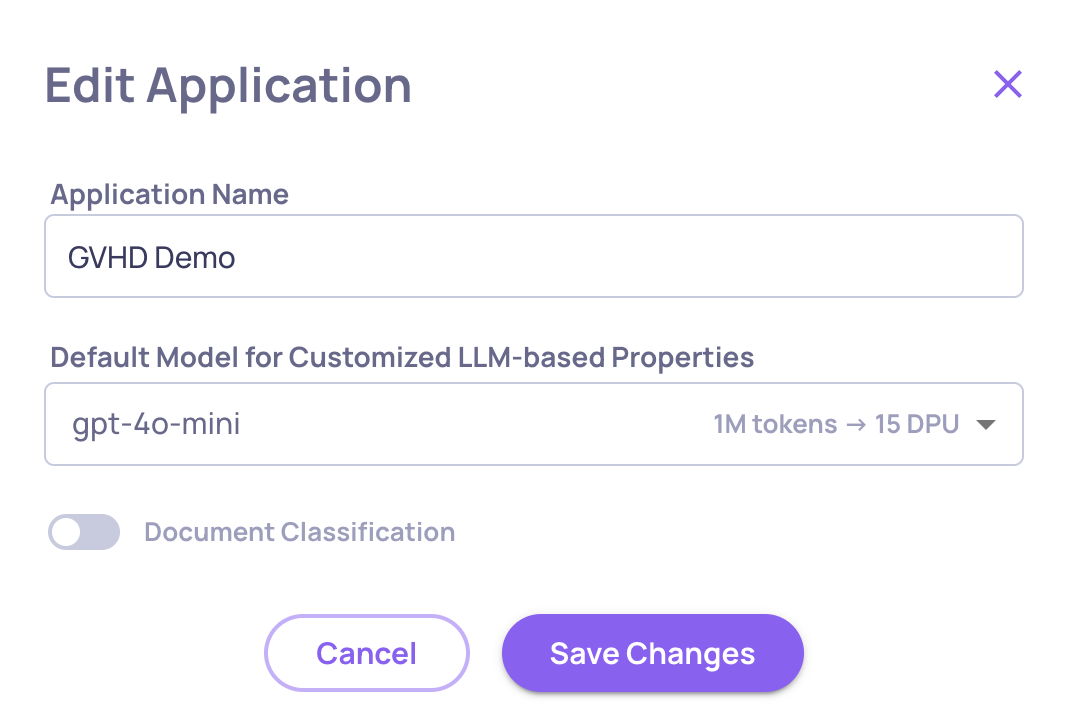
Enabling/Disabling the Classification on the "Edit Application" Window
Document Classification
Deepchecks evaluates the quality of documents by looking at how well they cover the information needed to answer the user’s input. Every input usually requires several pieces of information to be fully addressed. Based on how much of this information a document provides, it is classified into one of three categories:
- Platinum: The document includes all the necessary information to fully and confidently answer the user’s input. No important details are missing, and the document alone is enough to provide a complete response.
- Gold: The document includes some relevant information that helps answer the input but does not cover everything. It contributes useful parts of the answer but would need to be combined with other documents for a complete response.
- Irrelevant: The document does not provide any of the information needed to answer the input. It does not help in understanding or addressing the user’s question.
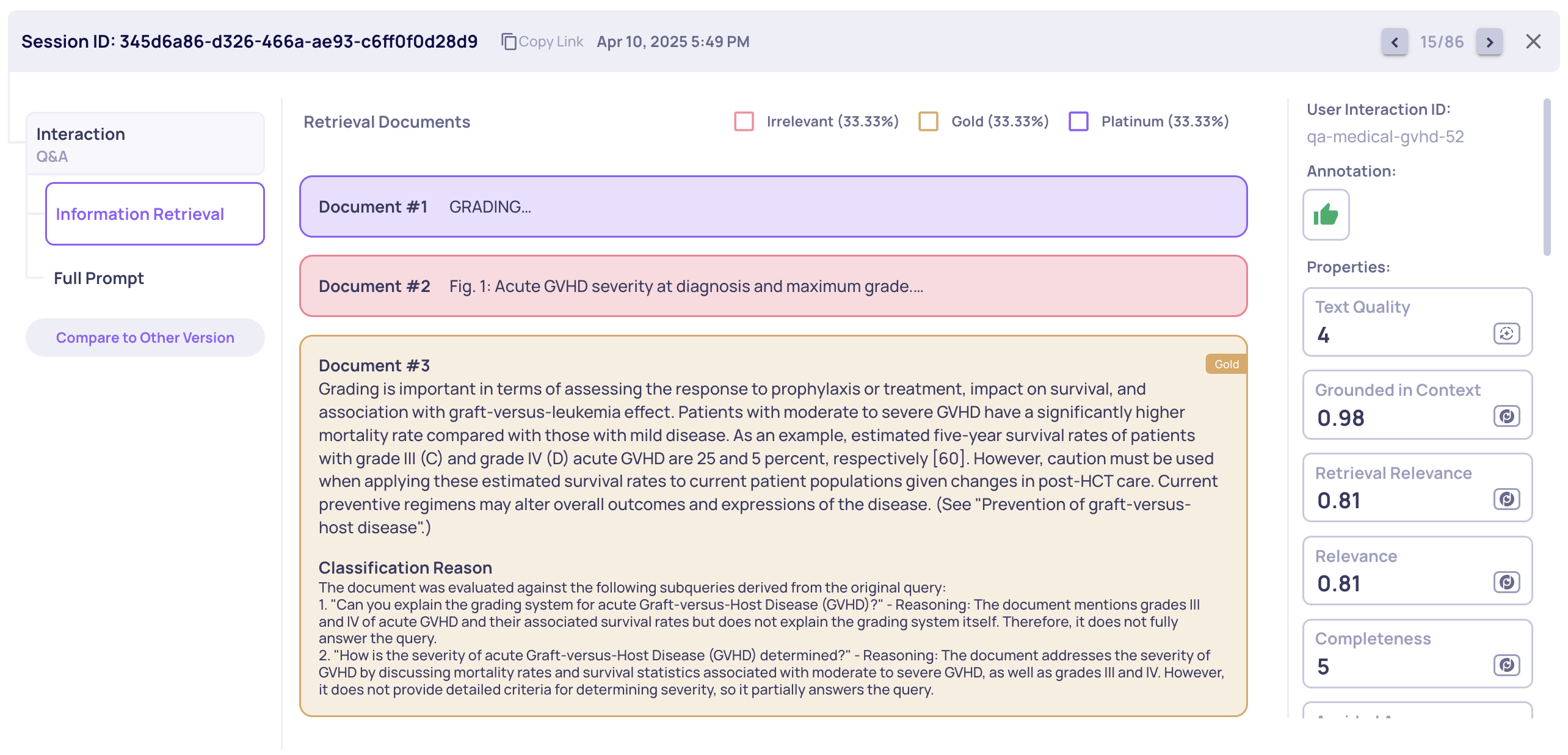
Example of Document Classification for a Single Interaction
The bottom section of each document, in its expanded form, states the reasons for its classification.
"Unknown" DocumentsNote: If classification fails or is disabled, documents will be marked as "unknown" and shown in the default interaction color.
This classification forms the basis for calculating retrieval properties, allowing the quality of the retrieval process to be measured both at the individual interaction level and across the entire version.
RAG Properties Unreliant on Document Classification
Grounded in Context
When it comes to generative AI one of the most concerning problems is Hallucinations. In order to avoid this kind of mistake we would want to make sure that all factual claims by our LLM are entailed by trusted sources of truth, in most cases, documentation about the relevant topic.
The Grounded in Context Score is a measure of how well the LLM output is grounded in the provided context (a concatenation of the input, information retrieval, full prompt and chat history), ranging from 0 (not grounded) to 1 (fully grounded). Specifically, this property separately validates that each factual statement in the output is entailed by the provided context.
A single significant ungrounded detail in the output is often enough to result in a low score.
Examples
| Input | Retrieved Information | LLM Output | Grounded in Context Score |
|---|---|---|---|
| In what year was Michael Jordan born? | Michael Jordan (1963) is an American former professional basketball player and businessman. | He was born in 1963. | 0.99 |
| When was Michael Jordan born? | Michael Jordan (1963) is an American former professional basketball player and businessman. | Michael Jeffrey Jordan was born in 1963. | 0.76 |
| What were Michael Jordan's life achievements? | Michael Jordan (1963) is an American former professional basketball player and businessman. | He won many NBA championships with the Cleveland Cavaliers. | 0.07 |
Explainability Highlighting
In the Interactions Screen, you can click on a property while viewing an interaction to see all ungrounded statements in the output:

Handling Low Grounded in Context Scores
A low Grounded in Context score can result from application design issues or data modeling problems within Deepchecks. Below are several common mitigation strategies:
- Prompting - When using an external data source, ensure the model relies on it rather than its internal knowledge, which may be outdated or inaccurate. Clearly instruct the LLM to base its answer strictly on the provided information and to refrain from responding if the necessary information is missing.
- Model Choice - If improving prompting does not resolve the issue, the model itself may struggle with instruction adherence. Consider upgrading to a model that is better at following complex instructions.
Ensuring Complete Context for Grounding Evaluation
- The Grounding Evaluation assesses all factual elements of the output and verifies that they are supported by the available data fields: Full Prompt, Input, Information Retrieval, and History. If any crucial information is missing from the system, it will likely result in a low Grounded in Context score.
- For example, if only the Input and Information Retrieval are provided, but the Prompt (which was not uploaded to Deepchecks) includes an instruction to append references to additional resources, the Grounding Evaluation may classify these references as hallucinations.
Retrieval Relevance
The Retrieval Relevance property is way of measuring the quality of the Information Retrieval (IR) performed as part of a RAG pipeline. Specifically, it measures the relevancy of a retrieved document to the user input, with a score ranging from 0 (not relevant) to 1 (very relevant).
The property calculation is based on several models and steps. In the first step the retrieved document is divided into meaningful chunks, then each chunk's relevance is evaluated using both a semantic evaluator and a lexical evaluator. In the final step the scores per chunk are aggregated into a final score.
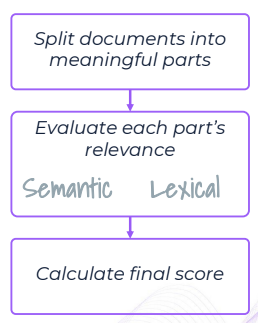
Explainability Highlighting
In the Interactions Screen, you can click on a property while viewing an interaction to see the most relevant paragraphs in the retrieved documents:

RAG Properties Reliant on Document Classification
Retrieval properties are based on the Platinum, Gold, and Irrelevant classifications. They offer insights into the effectiveness of retrieval, helping to assess performance and spot areas for improvement in the RAG pipeline.
Normalized DCG (nDCG)
Normalized Discounted Cumulative Gain (nDCG) is a score ranging from 0 to 1. It evaluates the relevance of ranked retrieval results while normalizing scores to account for the ideal ranking. This metric helps determine how effectively the retrieved documents maintain their relevance order, with higher scores representing better alignment with an ideal ordering.
Retrieval Coverage
Retrieval coverage is a score between 0 and 1. It evaluates whether the retrieved gold and platinum documents provide all the necessary information to fully address the input query. Since a query may require multiple distinct pieces of information, the evaluation considers each part individually. A high retrieval coverage score indicates that most of the required information is present in the retrieved documents.
Explainability
The Retrieval Coverage property includes attached reasoning, showing a breakdown of the input into sub-queries and assessing whether each is fully, partially, or not addressed by the information retrieval. You can also review the Gold and Platinum documents to see what information is covered or missing.

Retrieval Utilization
Retrieval Utilization is a metric that evaluates how effectively a language model incorporates information relevant to the input query from retrieved documents when generating an output.
The Retrieval Utilization Score measures the proportion of relevant key points from the retrieved content that appear in the model’s output, relative to the total number of relevant key points. The score ranges from 0 (low coverage) to 1 (high coverage). It is calculated by extracting key points relevant to the input query from relevant documents (using document classification), identifying which of these are present in the output, and computing the ratio of preserved to total relevant content.
A low score indicates that the output includes only a small portion of the key points from the documents relevant to the input.
This property uses LLM calls for calculation
Explainability
The Retrieval Utilization property includes reasoning that lists the relevant key points from the documents which were missing from the output.

Handling Low Retrieval Utilization Scores
A low Retrieval Utilization score typically means that relevant information retrieved for a query did not make it into the model’s output. This often stems from two root causes:
- Poor Prompt Guidance - If the prompt doesn’t clearly instruct the model to rely on retrieved information, the output may overlook key points. To address this, ensure the prompt explicitly tells the model to use and prioritize content from the retrieved documents. You can also preprocess the context to highlight essential details.
- Irrelevant or Distracting Contexts - When too many unrelated or low-quality documents are included, they can dilute the useful signal. Filtering the retrieved documents before prompting the model-based on relevance-can significantly improve utilization.
Retrieval Precision
Retrieval precision is a score ranging from 0 to 1. This property calculates the proportion of Gold and Platinum documents among all retrieved documents. High retrieval precision indicates that a significant portion of the retrieved content is relevant, showcasing the quality of the retrieval step.
# Distracting
This metric identifies the number of irrelevant documents that are mistakenly ranked above relevant ones (Gold or Platinum). A high number of distracting documents suggests potential issues in ranking relevance, which may negatively impact the pipeline's output quality.
Mean Reciprocal Rank (MRR)
Mean Reciprocal Rank (MRR) is a score ranging from 0 to 1. It measures the rank of the first relevant document, be it Gold or Platinum. It reflects the efficiency of retrieving relevant content. A higher MRR indicates that relevant content is retrieved earlier in the process, contributing to a more efficient retrieval pipeline.
# Retrieved Docs
This property shows the total number of documents retrieved in the information retrieval process (i.e., the K in top-K). This property is primarily useful for filtering and root cause analysis (RCA) within the system.
Interpreting Retrieval Properties
🔍 Understanding Low Normalized DCG (nDCG)
A low normalized DCG score typically indicates that the ranking of the retrieved documents is suboptimal. This could reflect a problem with the ranking model’s ability to order documents by relevance. However, the cause can vary depending on other metrics. Below are key patterns and how to interpret them:
📉 Case 1: Low nDCG + High #Distracting
This combination suggests that relevant documents are present in the retrieval, but the ranking model failed to prioritize them correctly. Distracting documents (those unrelated but still ranked high) are taking precedence.
🔎 What to do:
- Investigate your ranking or re-ranking strategy.
- Check if the query is ambiguous.
- Explore methods to better prioritize Gold and Platinum documents.
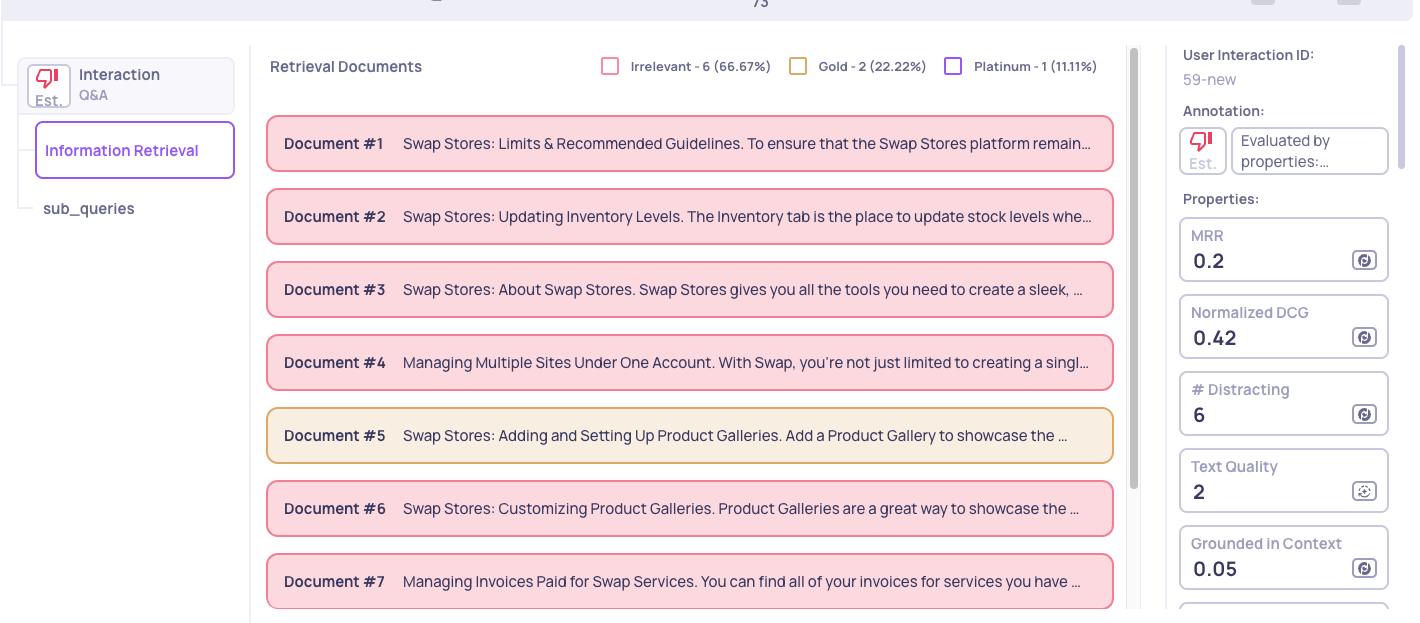
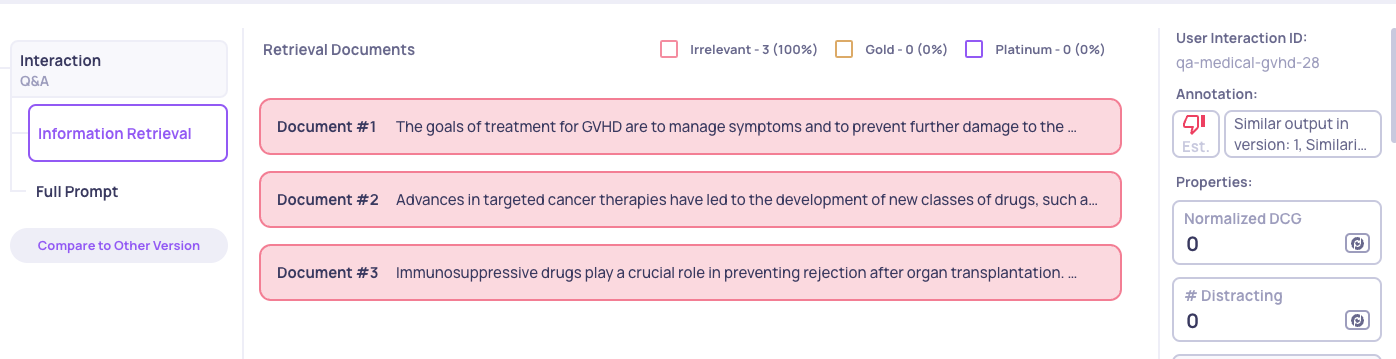
📉 Case 2: Low nDCG + Low #Distracting
Here, like in the example below, few documents are distracting, but the ranking is still poor.
This usually means:
- Either relevant documents don’t exist in the database, or
- The retrieval depth (i.e., #Retrieved Docs) is too shallow to reach them.
🔎 What to do:
- If #Retrieved Docs is low, increase it and check if relevant documents emerge.
- If #Retrieved Docs is already high, consider whether the information simply doesn’t exist in the database.
📚 Detecting Retrieval Overload
Retrieval overload occurs when the information retrieval process successfully fetches enough relevant information to answer the query, but also retrieves too many irrelevant documents. This can be detected using two properties: retrieval precision and retrieval coverage.
When retrieval precision is low (i.e., few of the retrieved documents are relevant), but retrieval coverage is high (i.e., enough relevant information was retrieved to fully address the query), it indicates retrieval overload.
🔎 Common causes:
- Choosing too large a value for K. Consider reducing K to retrieve fewer, more relevant documents.
- A poor ranking mechanism. Consider improving the ranking or reranking strategy.
❌ Detecting Wrongly Avoided Answers
When building a Q&A system, it’s not always obvious whether a bot’s decision to avoid answering a question is intentional or problematic. In some cases, if the relevant information was not retrieved, it’s desirable for the bot to refrain from answering rather than hallucinate a response. In other cases, if the information was available but the bot still avoided the question, this may signal an issue.
To address this, we use two key properties:
- Avoided Answer: Indicates whether the bot chose not to answer.
- Retrieval Coverage: Measures whether the retrieved documents contain the full information needed to answer the query.
By combining these properties, we can distinguish between correctly and wrongly avoided answers-enabling better debugging and refinement of the system’s behavior.
Updated 4 months ago