Production Monitoring
In production environments, we face the challenge of operating in a labelless landscape. Luckily, the Deepchecks auto annotation pipeline is based on properties that do not require a ground truth response, making model performance evaluation flexible and faster.
In our example, based on the version comparison conducted, we decided to move forward with the Balanced prompt version. In production, we would apply the same auto annotation pipeline to monitor whether our application continues to perform similarly to what we saw in the evaluation set.
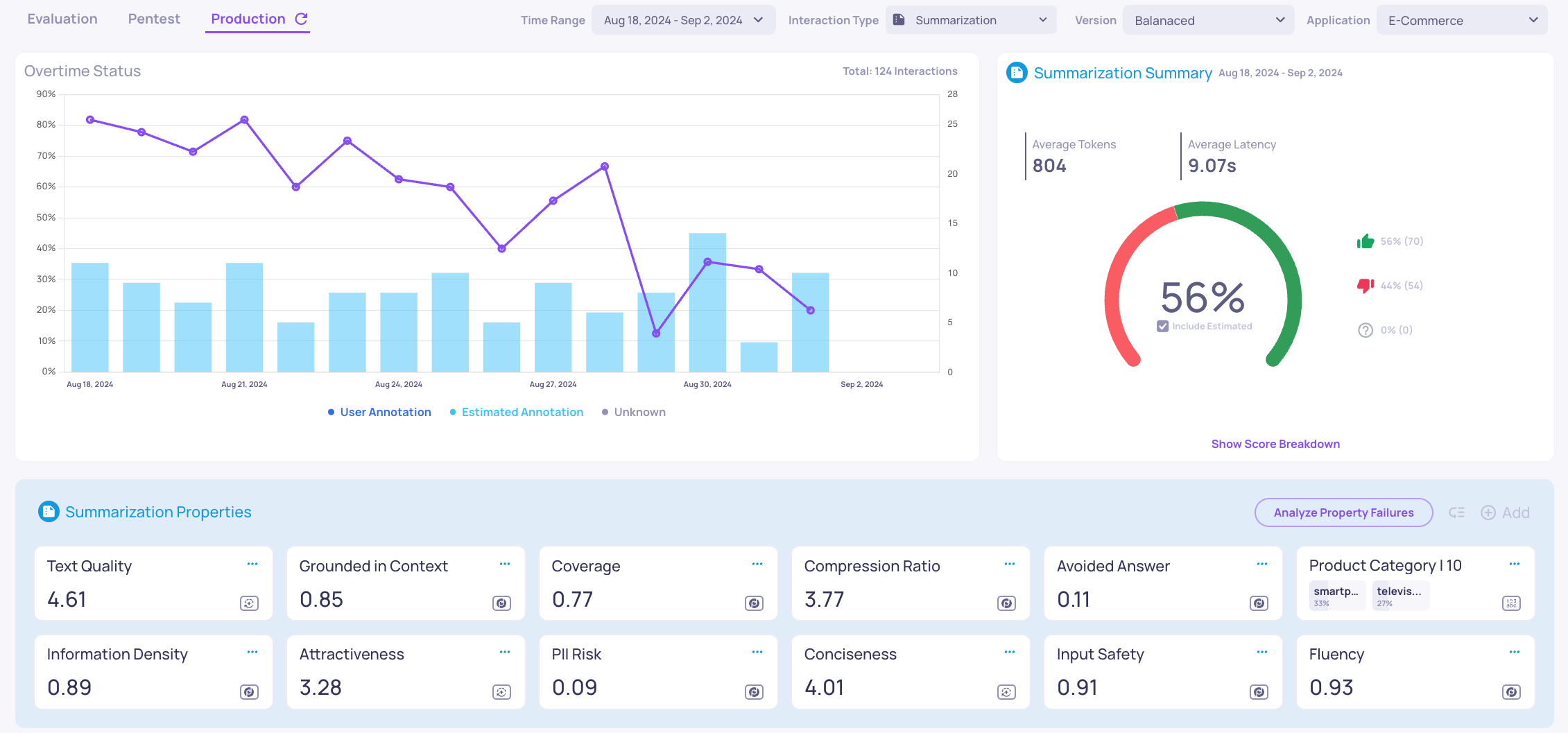
Based on the estimated annotation, we can see that in the beginning the performance is similar to what we saw in the evaluation set, which is expected, and later on a degradation in the performance, specifically after 28/08/2024.
Next, we are going to investigate what properties had degradation in performance.
Attractiveness and Percent of Valid Values show a sudden decrease:
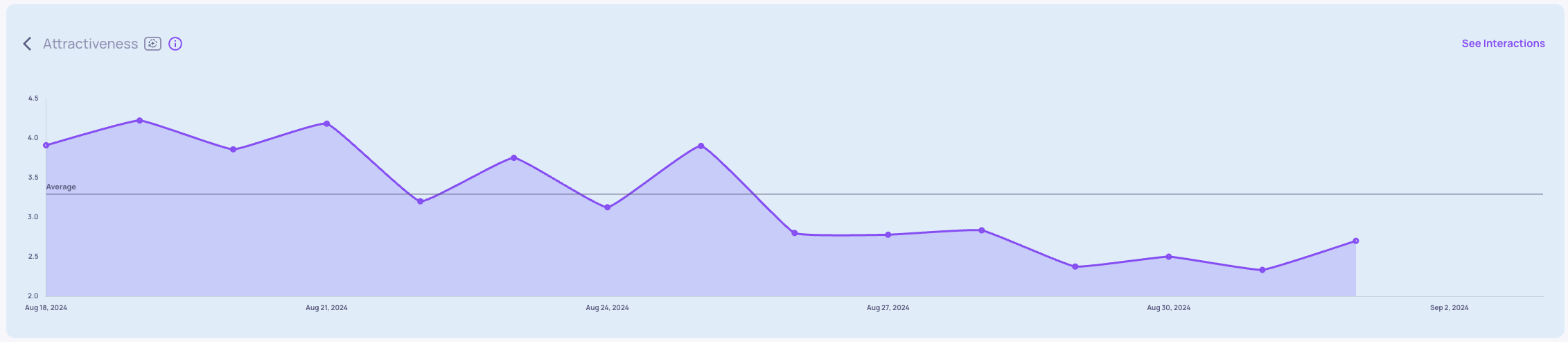
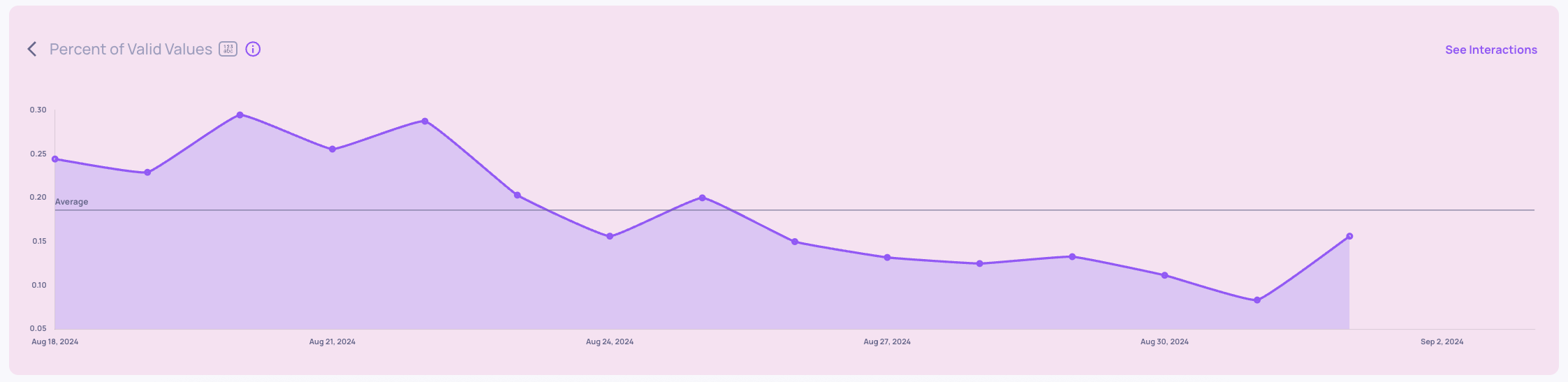
Root Cause Analysis:
To better understand the degradation starting August 26th, we'll use the Analyze Property Failures:
-
Press Analyze Property Failures
-

Choose Attractiveness and select the time range from August 26th to September 2nd
-
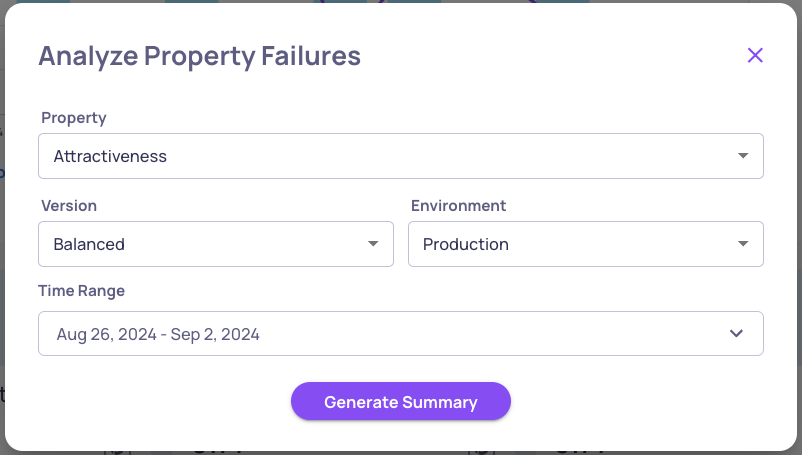
Click the Generate Summary button
The generated summary reveals three main categories of failures:
- Overly technical language lacking customer focus
- Insufficient persuasive and engaging tone
- Inclusion of irrelevant or negative details that detract from marketing effectiveness
Looking into the specific examples in the production data that received low scores in the mentioned properties, we can see the obvious data drift in the input. Before August 26th, the inputs included product descriptions, technical details, and FAQ, while After the input includes only FAQ and is missing product descriptions and technical details.
After 26/08:
- Session ID: 308
- Data: Sep 01, 8:57 PM
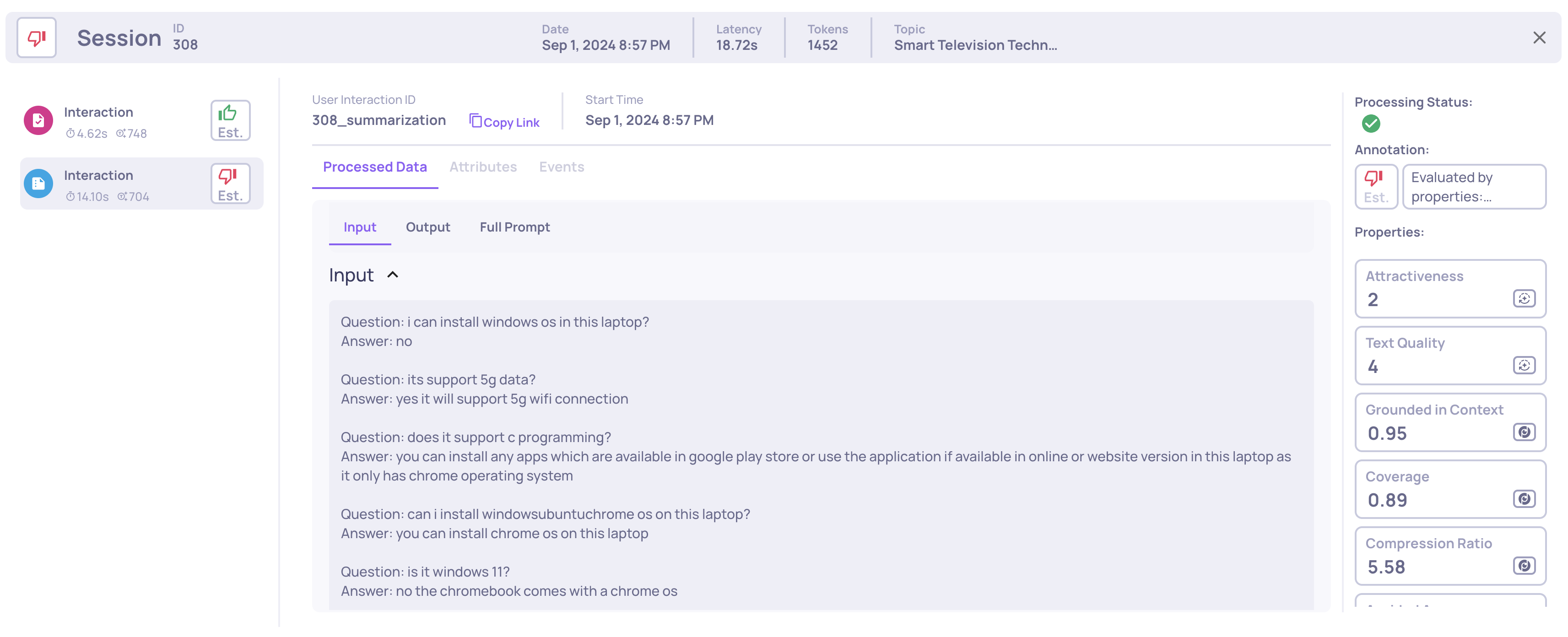
Before 26/08:
- Session ID: 204
- Date: Aug 19, 2:56 AM
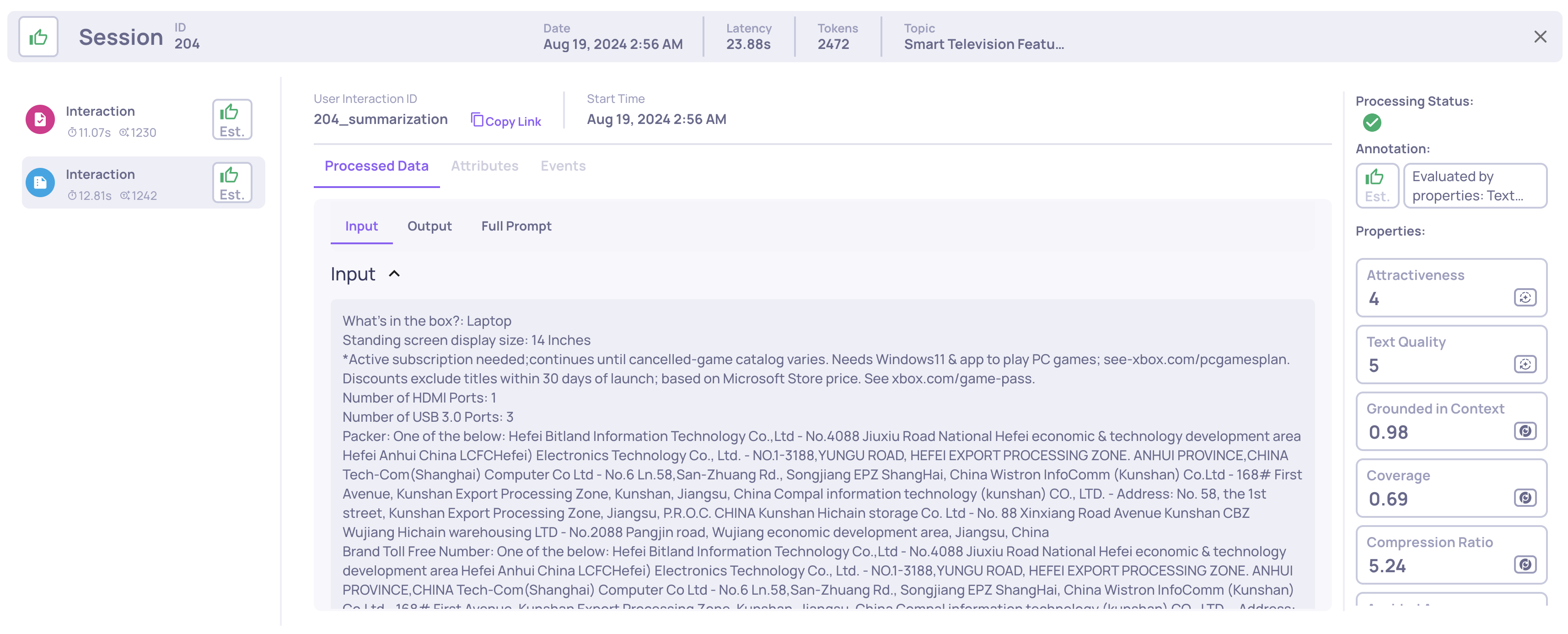
Hooray! Estimated annotations and Monitoring overview have helped us identify a bug in the data collection process!