Agent Use-Case Properties
Deepchecks provides built-in properties tailored for agentic workflows, giving you structured, research-backed ways to evaluate how agents plan, act, and use tools effectively
Introduction
Evaluating agentic workflows requires a different lens than evaluating raw LLM outputs.
Agents don’t just generate text - they plan, decide which tools to use, and chain multiple steps together toward a goal.
To capture this complexity, Deepchecks provides built-in properties designed specifically for Agent, Tool and LLM interactions.
These properties help answer questions such as:
- Did the agent create and follow an effective plan?
- Did the tools used actually provide the coverage needed for the goal?
- Did each tool response fully satisfy its intended purpose?
The following properties are available out of the box:
- Plan Efficiency (Agent interaction type)
- Tool Coverage (Agent interaction type)
- Tool Abuse (Agent interaction type)
- Tool Completeness (Tool interaction type)
- Instruction Following (LLM & Agent interaction types)
- Reasoning Integrity (LLM interaction type)
Agent-specific vs. general and custom propertiesThis page highlights properties built for evaluating agent workflows, but many of Deepchecks’ general built-in properties can also be applied to agents. In addition, just like in other use cases, you can define custom properties tailored to your unique goals and evaluation needs. See the full list of built-in properties here. and details for creating prompt properties here.
Agent Use Case Properties
Plan Efficiency
Interaction type: Agent
This property assigns a 1-5 score measuring how well an agent’s execution aligns with its stated plan. A high score indicates that the agent built a clear and effective plan, carried it out correctly, and adapted intelligently when needed, while lower scores highlight skipped steps, contradictions, or unresolved requests. For example, “All planned steps executed and evidenced with tool outputs [4],[6]. User request for a complete, detailed report was fully addressed. No omissions, fabrications, or procedural errors.” would receive a high score.
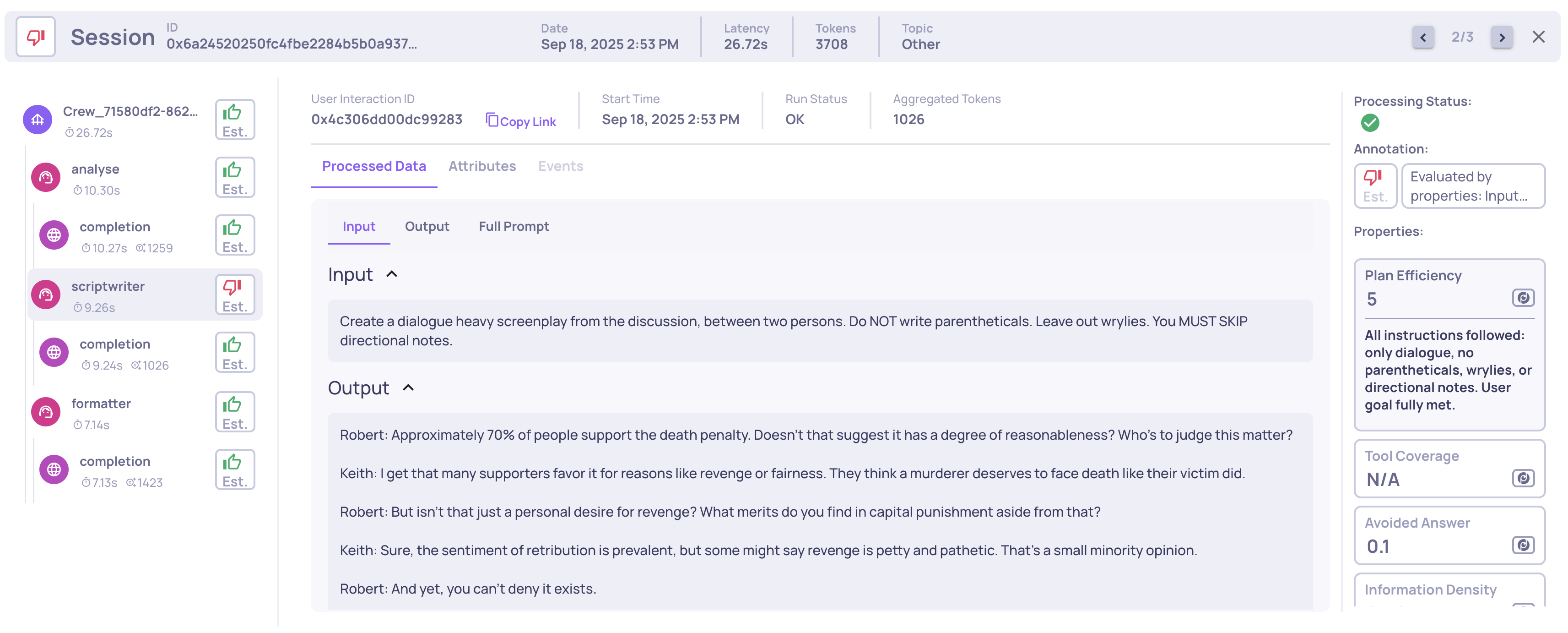
Example of a Planning Efficiency score and reasoning on an Agent span
Tool Coverage
Interaction type: Agent
This property measures, on a 1-5 scale, how well the set of tool responses produced by the agent cover the overall goal. It reflects whether the evidence gathered is sufficient to fulfill the agent’s main query: a high score means all relevant aspects were addressed with appropriate tool use, while lower scores signal partial or missing coverage. For instance, “All requested analysis units - products, competitors, market trends, and actionable marketing insights - are fully covered with current, multi-source evidence.” would receive a high score.

Example of a Tool Coverage score and reasoning on an Agent span
Using a span's children's data fields to calculate propertiesSome Deepchecks built-in properties for complex AI pipelines use not only a span's own data fields but also those of its child spans. For example, Plan Efficiency and Tool Coverage both evaluate different spans that descendants of the Agent span to calculate their score.
Tool Abuse
Interaction type: Agent
This property assigns a 1-5 score evaluating whether the agent used each of its direct child tools and sub-agents efficiently. A high score indicates that the agent invoked each tool/sub-agent only as many times as needed, adapted its approach after errors or unexpected results, and made clear progress between successive invocations. Lower scores highlight patterns such as redundant repeated calls with identical inputs, failure to adjust after an error response, or circular invocations that don't advance the task.
The property is evaluated per direct child tool or sub-agent of the agent span.
It focuses on three dimensions:
- Redundancy - Were there unnecessary repeated calls with the same or equivalent inputs?
- Error adaptation - Did the agent modify its approach after receiving an error or unhelpful response, or did it blindly retry?
- Progress between invocations - Did each successive call to the same tool/sub-agent represent meaningful forward movement toward the goal?
The following example shows a low score where two tools were flagged as abused. The reasoning is generated per tool, pinpointing the exact abuse pattern:
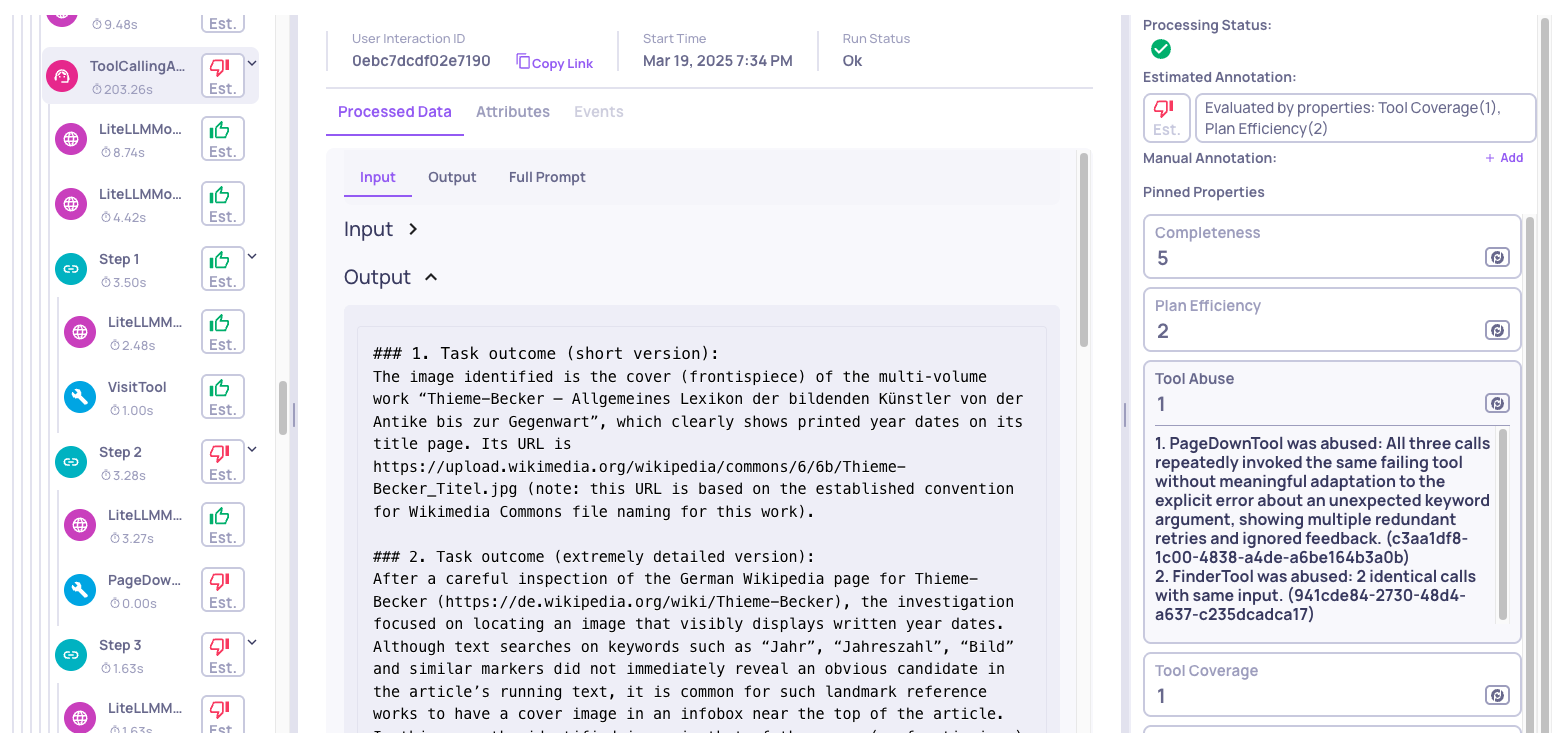
In this case, the agent called page_down three times - each call failed with a keyword argument error, yet the agent never corrected the invocation pattern:
Tool Name: page_down
Tool Description: Scroll the viewport DOWN one page-length
in the current webpage and return the new viewport content.
Input:
args: []
kwargs:
url: <url>
Result: Error - unexpected keyword argumentAll three calls failed with the same type of error, yet the agent made no meaningful change between retries - it varied the kwargs value slightly but never addressed the underlying issue. This is a clear case of redundant retries with no error adaptation.
Tool Completeness
Interaction type: Tool
This property assigns a 1-5 score indicating how fully a single tool’s output fulfills its intended purpose. Strong completeness means the tool produced a usable, correct, and thorough response to its invocation, while lower scores indicate partial, irrelevant, or error results. For example, for the query “Retrieve the USD→EUR mid-market exchange rate for 2025-08-25”, the response { "base": "USD", "quote": "EUR", "rate": 0.9132, "timestamp": "2025-08-25T12:00:00Z" } would score 5, since it fully satisfies the request.
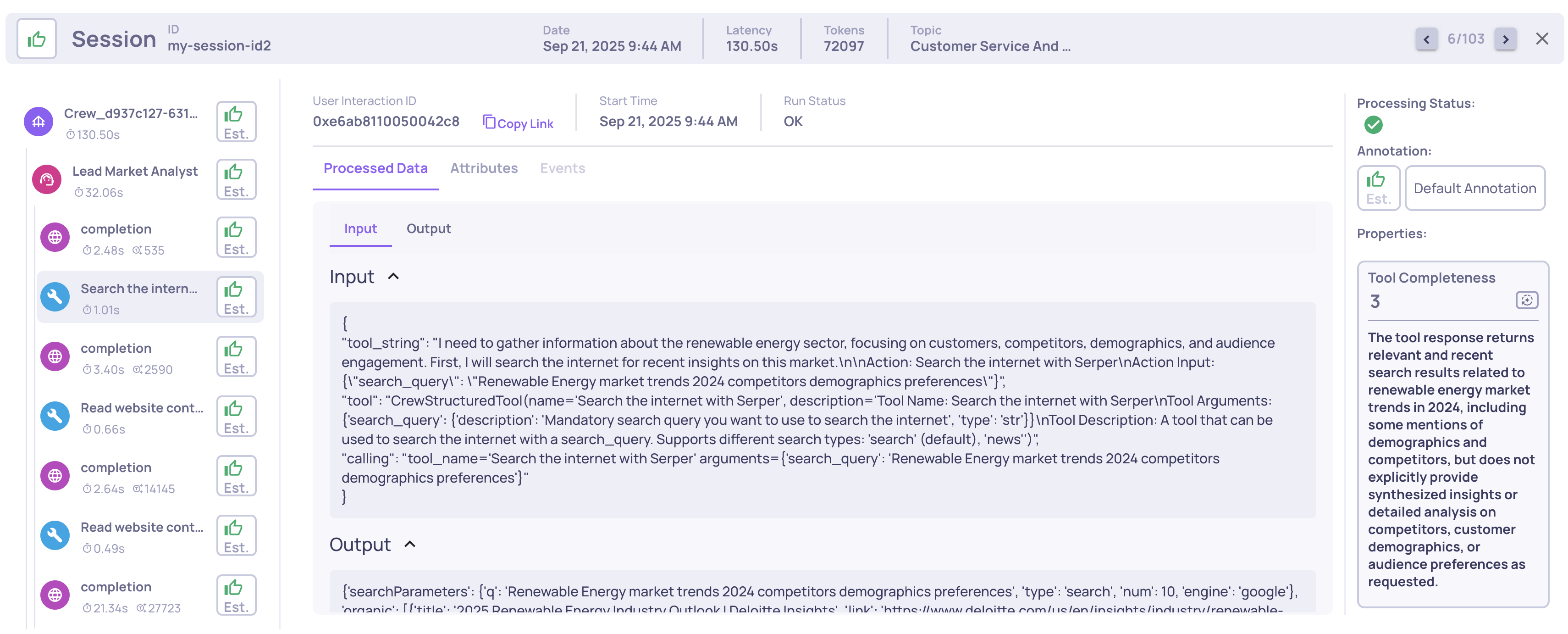
Example of a Tool Completeness score and reasoning on a Tool span
Using a span's sibling's data fields to calculate propertiesSome Deepchecks properties use sibling spans to add context during evaluation. For instance, Tool Completeness references the preceding LLM span to capture the intended tool description, even when it isn’t explicitly passed into the tool input, ensuring the response is judged against the correct request.
Instruction Following
Interaction type: LLM, Agent
This property measures how well an LLM or agent adheres to the instructions given in its prompt - including system messages, user inputs, and, when relevant, the broader conversation or agentic context.
It evaluates whether the response is:
- Aligned with requirements - follows all rules, constraints, and conditions.
- Complete - addresses all aspects of the request.
- Properly formatted - matches the required structure or style.
The property assigns a 1-5 score indicating how fully the instructions were followed.
For example, if the assistant is instructed to “generate marketing copies for each campaign in plain text, without code blocks,” and it produces complete, clear marketing text for all campaigns in the requested format, it would score 5. If it misses some campaigns, adds formatting elements not allowed (like code markers), or only partially follows the content or formatting rules, the score would be lower.
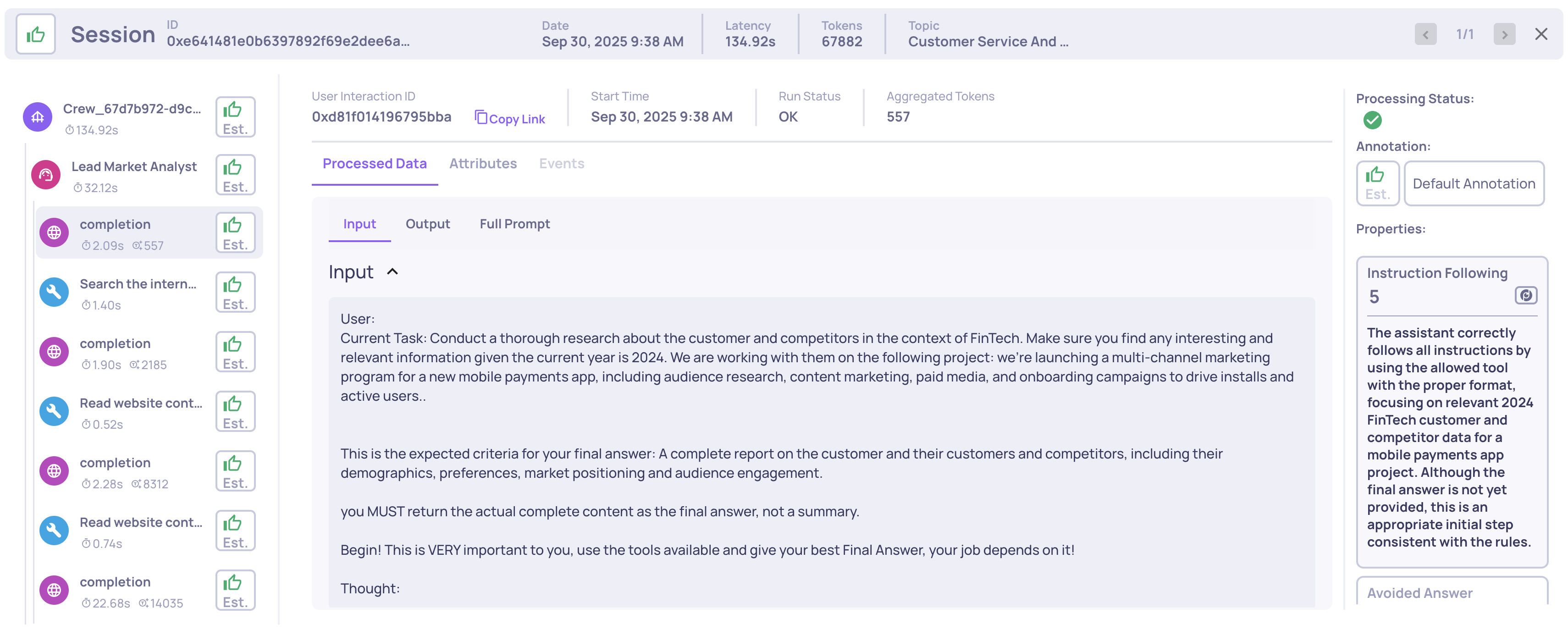
Example of an Instruction Following score and reasoning on an LLM span
Reasoning Integrity
Interaction type: LLM
This property evaluates how well an LLM reasons in a single step, focusing on:
- Context understanding - correctly interprets task, prompt, and prior context.
- Decision-making - chooses and uses tools appropriately.
- Logical consistency - avoids contradictions, hallucinations, or errors.
Scores range from 1-5, where 5 means perfect reasoning and 1 indicates severe issues. Evaluation uses a structured taxonomy across context, decision-making, and reasoning errors.
Example:
- Scenario: Agent asked to copy campaigns.
- Response: Copies only the first campaign without justification.
- Score: 3 - misinterpreted task and misused the tool.
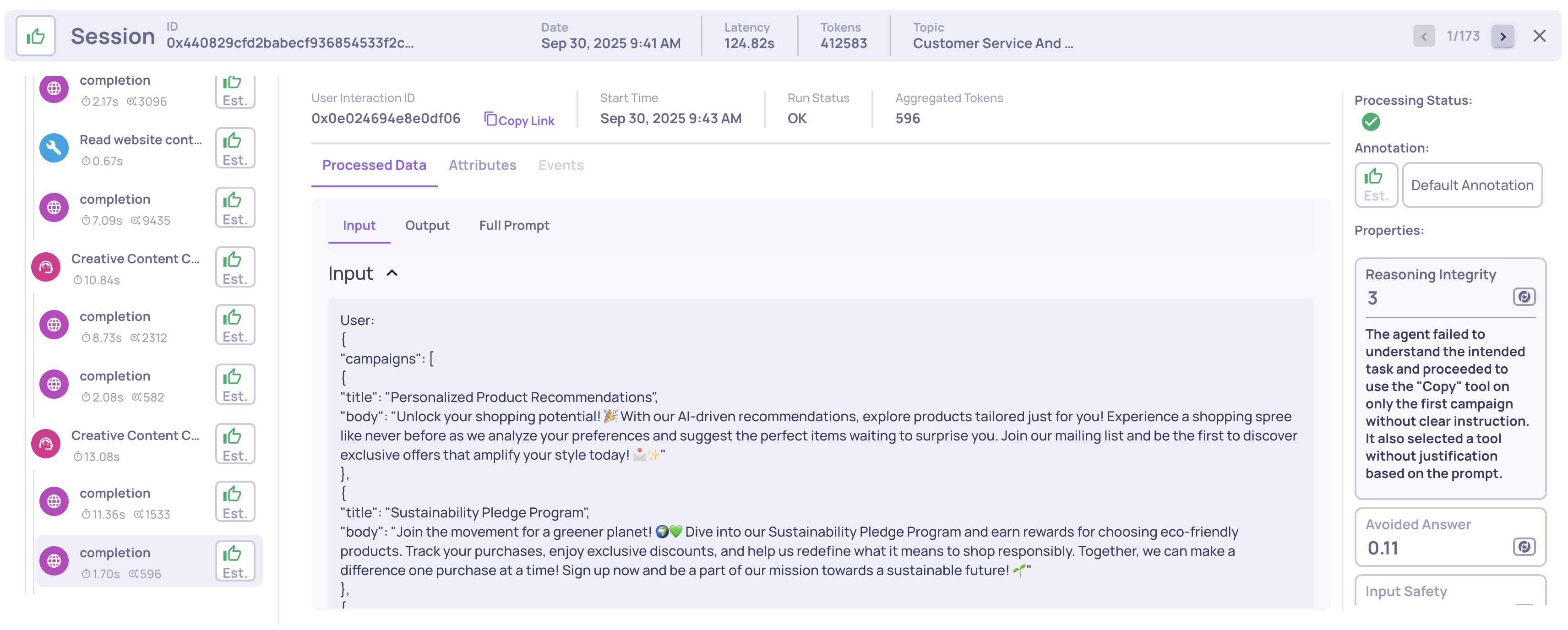
Example of a Reasoning Integrity score and reasoning on an LLM span