Measuring Evaluation Set Quality
After Building Your Initial Evaluation Set you’ll want to assess its quality to ensure it meets the required standard. This involves two main steps: confirming that the inputs reflect real production usage, including edge cases, and verifying that the expected outputs are of high quality.
Realistic & Diverse Inputs
Your evaluation set should reflect the variety of inputs seen in production. Use Deepchecks’ Built-in Properties to analyze this. On the Properties page, select input-related metrics like input length, language, content type, and text quality, whichever are most relevant to your use case. User-Value Properties and Prompt Properties can be highly useful to cover additional dimensions relevant for your use case.
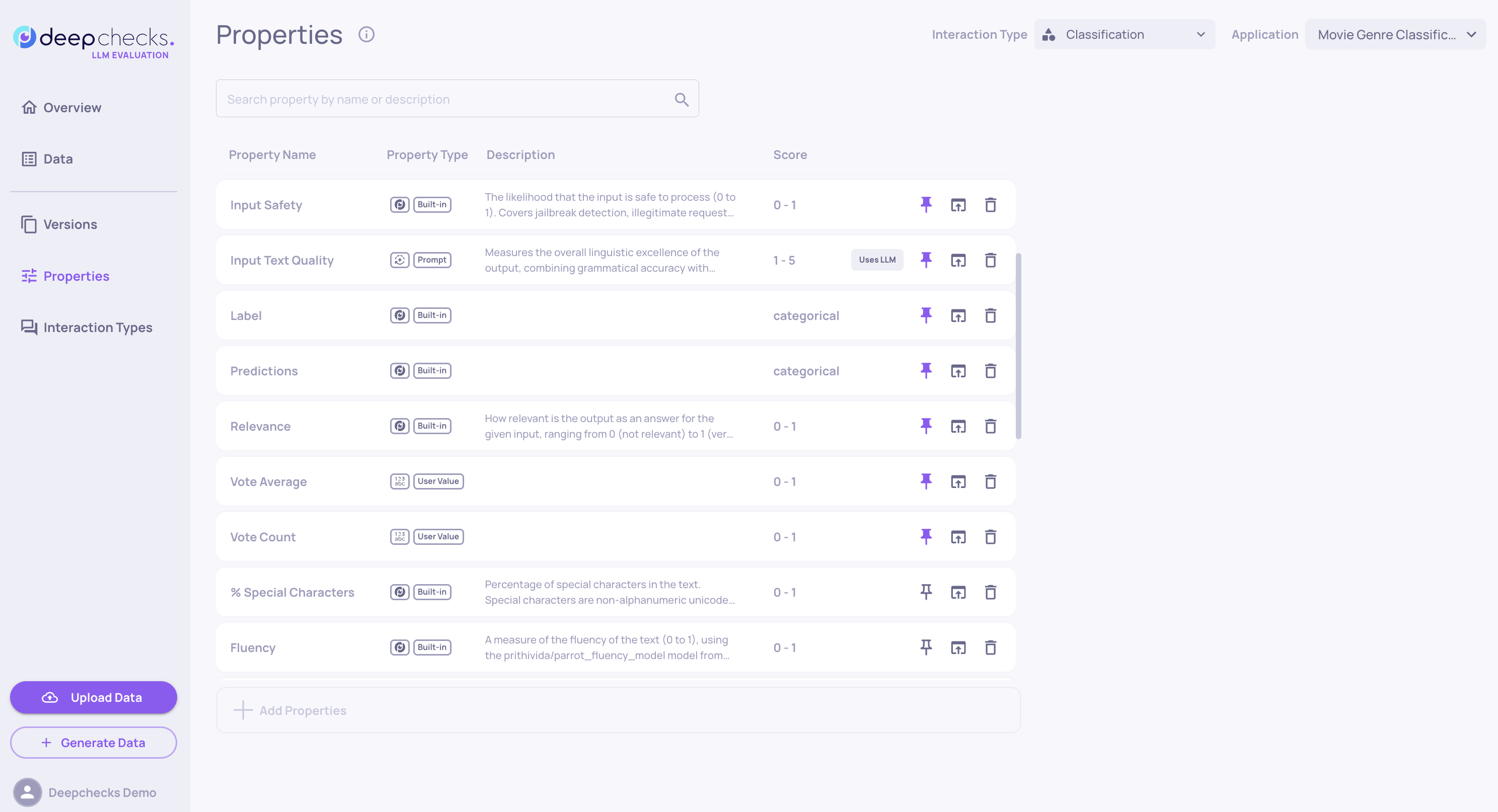
Add these to the dashboard and review the score distributions. A healthy set will show variety and include important edge cases-like very long or poorly written inputs. If you have access to production data, use it as a benchmark to understand the expected distribution for each property. You can also use Deepchecks’ automatic topic detection to ensure all relevant topics are covered.
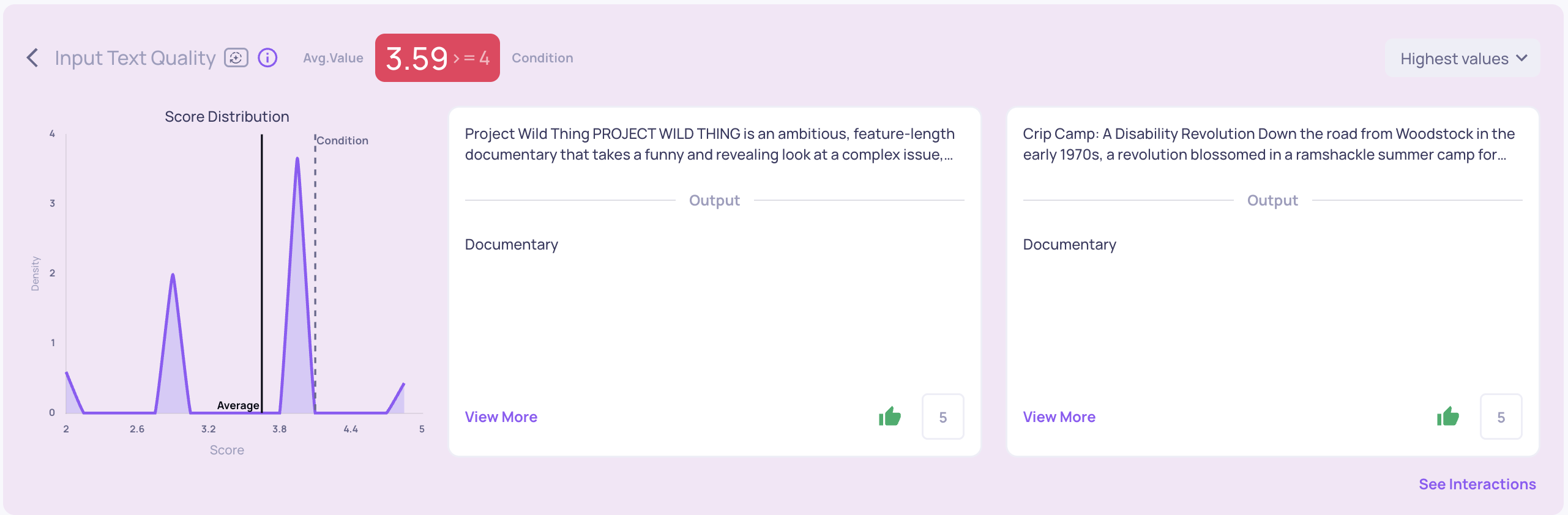
High Quality Expected Outputs
Even before configuring Auto Annotation, you can use Deepchecks’ Built-in Properties and out-of-the-box Auto Annotation to flag outputs that don’t meet your standards. These may include incomplete answers, low-quality text, or even irrelevant responses-often caused by attention slips during manual curation of the expected outputs.
Obvious errors are usually labeled as "bad" or "unknown" by Auto Annotation and can be found in the score breakdown on the main dashboard. However, more subtle issues might slip through. That’s why it’s recommended to also review interactions with the lowest scores in key properties.
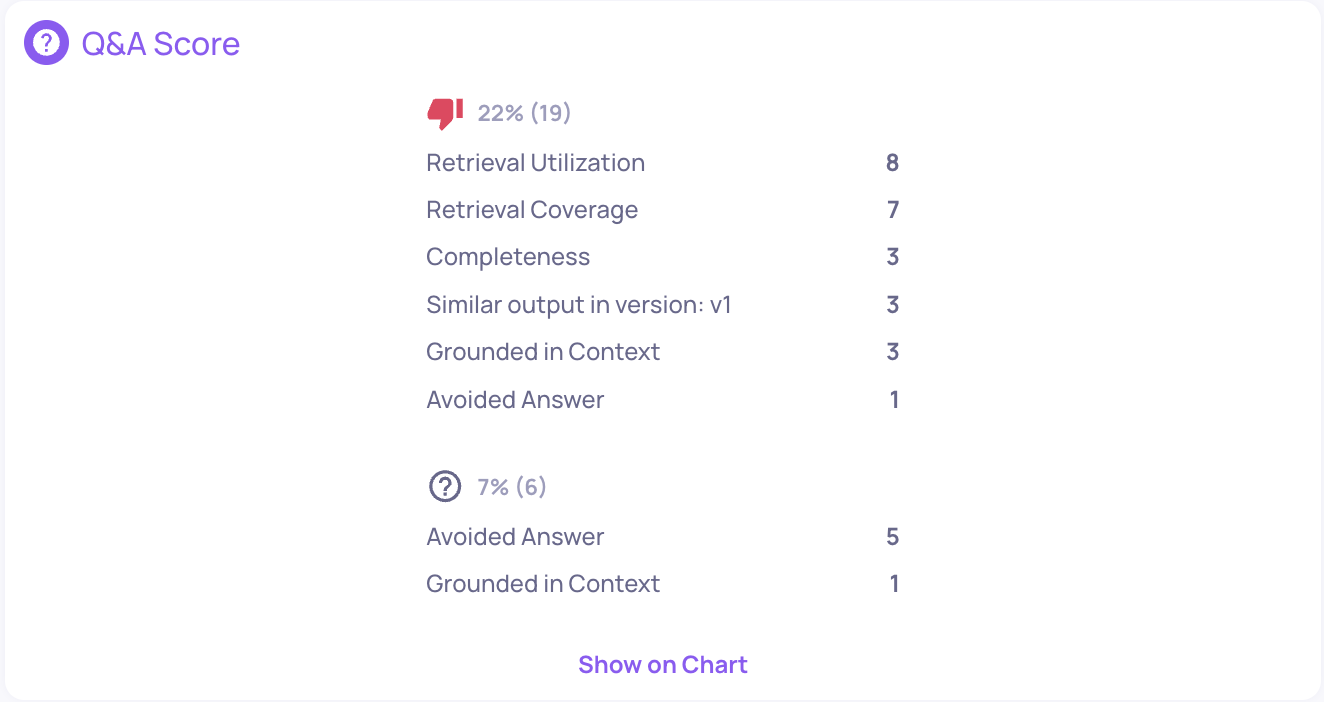
To dig deeper into issues in specific interactions or properties, use Deepchecks’ Root Cause Analysis (RCA) and Explainability tools.
Updated 3 months ago