Production Monitoring
Tracking model performance in the wild
In production environments, we face a unique challenge: unlike our evaluation sets with their ground truth labels, we're operating in a labelless landscape. This makes it considerably more difficult to assess model performance and conduct thorough error analysis. However, Deepchecks Evaluator bridges this gap by generating estimated annotations for the majority of samples, leveraging insights learned from our evaluation dataset.
Performance Trends
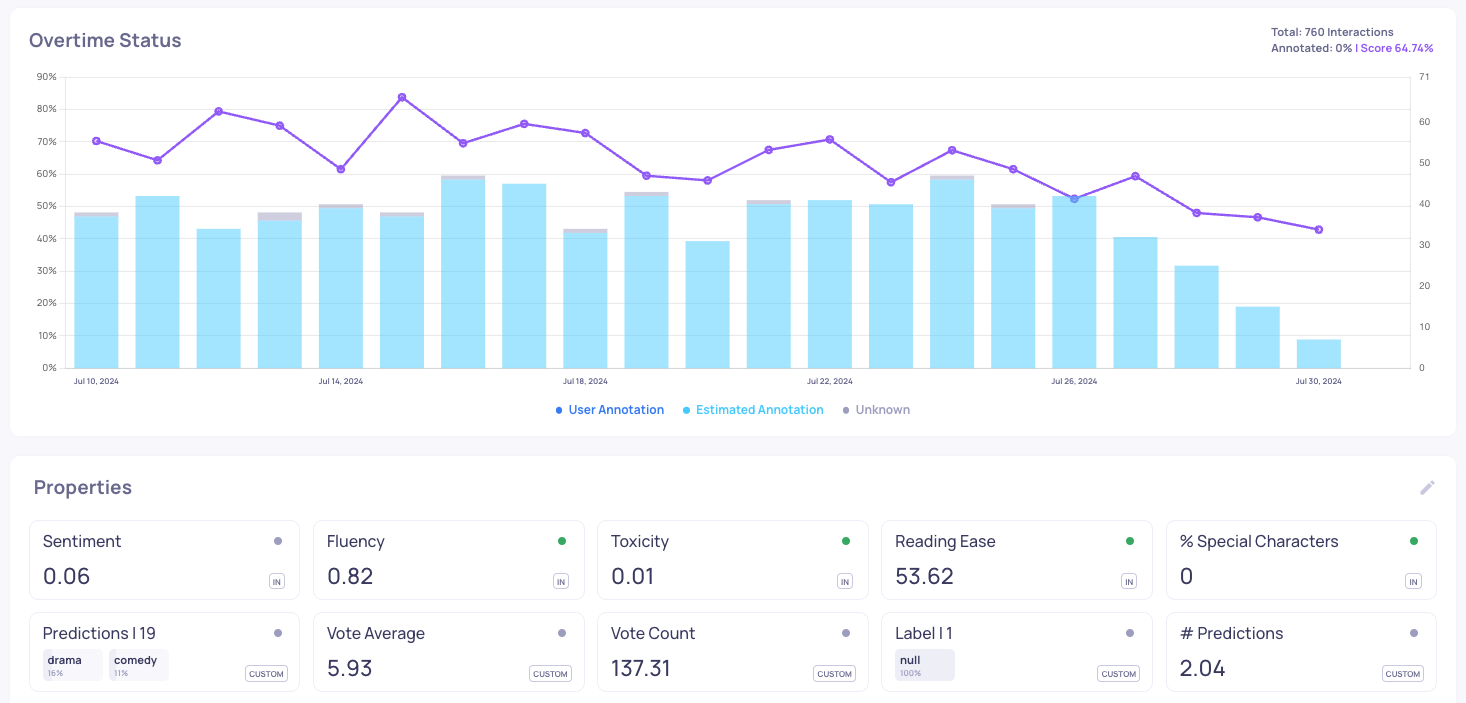
Our production dashboard reveals an interesting story: while the model initially performed on par with evaluation set benchmarks, we observed a gradual decline in performance over time. Furthermore, we detected an unexpected divergence - our production environment yielded 19 unique predictions, exceeding the 17 classes present in our evaluation set.
Root Cause Analysis
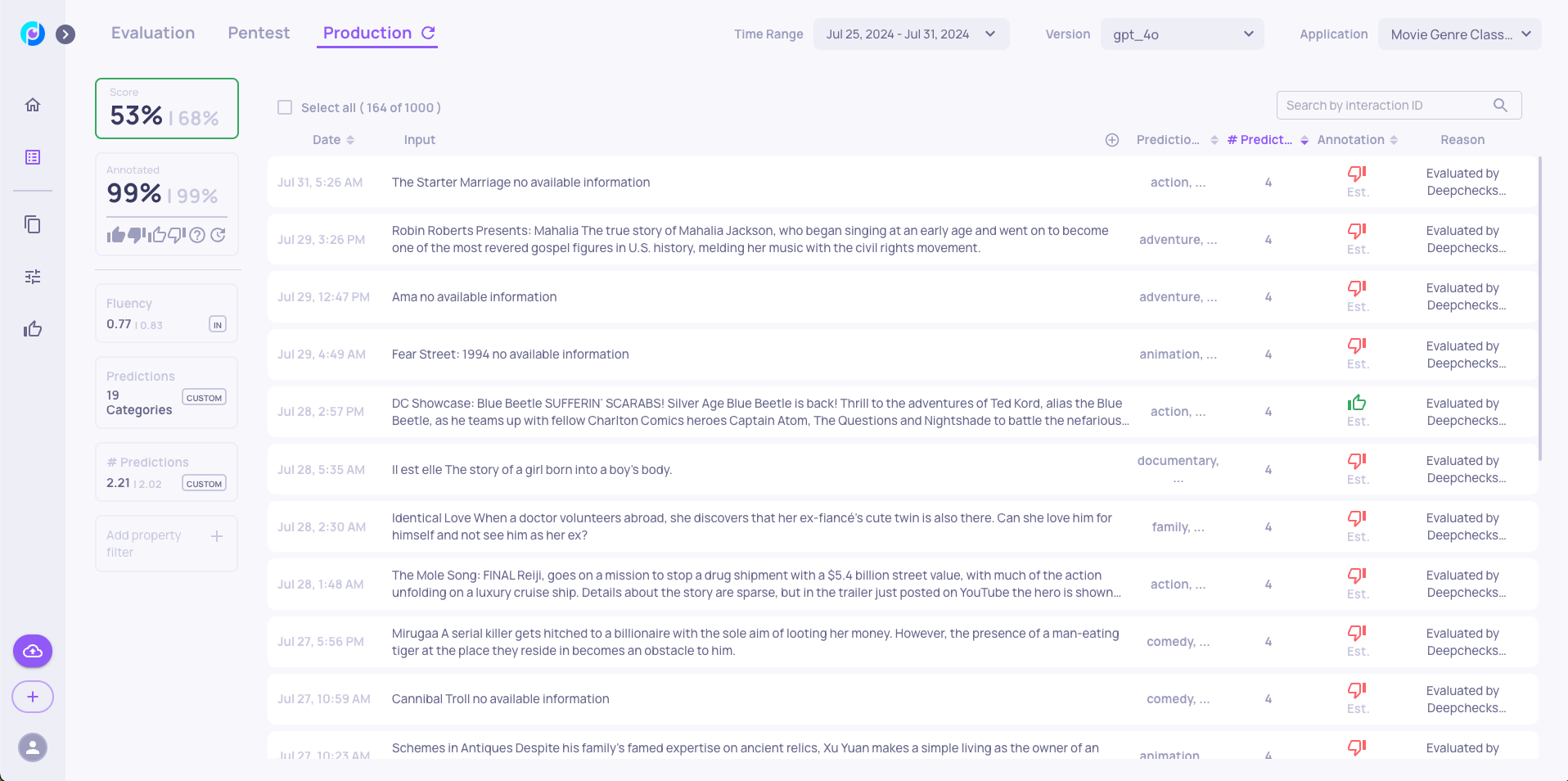
To understand this performance degradation, we conducted a detailed investigation focusing on late July data. Our analysis on the "Interactions" page, particularly examining the Prediction and # Prediction properties, revealed several key insights:
- Higher Prediction Density: We observed an elevated average number of predictions (2.21) compared to both:
- Overall average in the production data (2.02)
- Evaluation set average (1.96)
This increase is particularly significant as our Evaluation Set Analysis had previously identified this as a vulnerable area for our model.
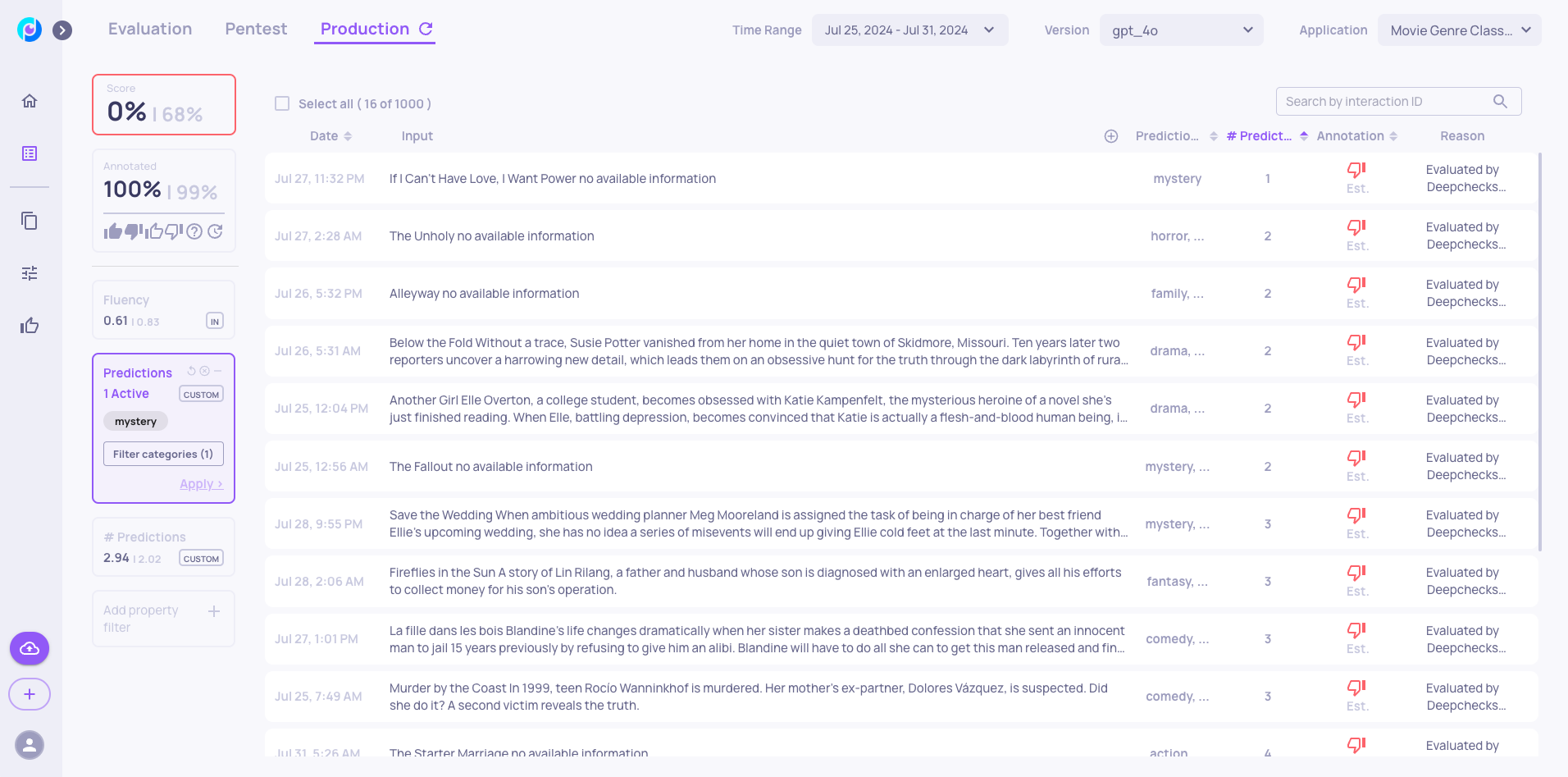
- The Mystery Class: Perhaps most intriguingly, we discovered a new prediction class - "Mystery" - absent from our evaluation set. Further investigation of these samples revealed predominantly negative annotations, suggesting one of two possibilities:
- Either this represents a genuine blind spot in our model's capabilities
- Or the Deepchecks Evaluator lacks the context to properly assess this new class
Either way, the clear action item is to update our evaluation set with "Mystery" class samples to improve model robustness.
Challenge for Advanced Users
For those looking to test their analytical skills: the production dataset contains two additional factors contributing to the performance decline. Can you identify these hidden issues?