Evaluation Set Analysis
Analyzing performance on the labeled evaluation set.
In this section, we will conduct a comprehensive evaluation of our candidate model to identify its strengths and weaknesses and ultimately decide on its readiness for production deployment.
Label Error Distribution
Let's begin by examining the labels present in our evaluation dataset. To do this, we can filter by the 'Expected Output Similarity' property and select those with low scores. We'll then analyze the negatively annotated samples to identify any classes that have become more frequent.
We can see that some classes, specifically TV Movie, and Thriller are more frequent in the negatively annotated segment. Since those classes are relatively rare we can decide to move forward with the version despite this finding.
Weak Segments
Deepchecks automatically detect segments in the data in which the average score is significantly lower than the average. By reviewing the insights in the dashboard we can quickly see that when our models predict 3 or more labels it is usually mistaken. This makes sense as in our task definition even a single wrong label would ruin the output yet definitely something we would want to note before shipping the version to production.

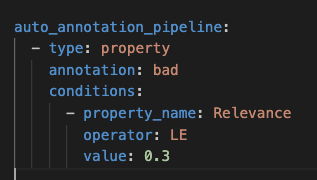
Modifying the Auto Annotation Yaml
In our specific scenario, the Relevance property appears to be a reliable indicator of incorrect predictions. While Deepchecks' Evaluator typically handles estimated annotations for classification tasks, our case suggests it would be beneficial to update the auto-annotation YAML to incorporate this property as well.