Hierarchy & Data Structure
How to structure your data in order to gain the most value from using Deepchecks for Evaluation?
This page enables you to understand the Deepchecks data structure, and how to work with your data to upload it to Deepchecks. It includes both:
- Data Hierarchy - Our structure of: Applications, Environments, and Versions and the interactions inside them.
- Data Upload Format - How to structure the different data fields (and metadata) for Deepchecks to process it.
Data Hierarchy: Concepts
Application 💬
- The application is the highest hierarchy within your organization's workspace.
- It represents a full task (end-to-end use case) and can encompass various** Interaction Types**, each tailored to specific parts of the workflow or evaluation.
- Creating a new application can be done via the Manage Applications screen.
- Editing an existing application, including updating the app name or settings, can be done through the Edit Application flow within the Manage Applications screen.
Note: Applications are standalone. Therefore if you'd like to compare between scores across applications, we recommend considering to upload the data to the same application and separate it by versions.
Version 🔎
Each version of your pipeline. They may differ in base model, prompts, data processing, etc. Creating a new version and editing an existing one, including version name and settings, can be done through the Versions screen.
Environment ♻️
Relates to the stage in your lifecycle:
- Evaluation - Typically for benchmarking the performance, comparing between multiple versions, iterating on a version to improve and fix problems, checking new application candidates, CI/CD, etc. Usually, the samples in the evaluation set would be the same for all versions of an application.
- Production - for deployed applications, usually after choosing the best version amongst a few, and after initial configuration of scores and properties, to enable efficient overtime monitoring.
- Pentesting (where applicable) - Separate environment for safety-related evaluation.
Session
A session represents a set of related interactions that occur within the same user flow - such as a chat conversation, a multi-step agent workflow, or a task sequence. Each session is identified by a session_id and is used to organize interactions that are contextually linked.
Sessions can span multiple interaction types and vary in size - from a single interaction to dozens - depending on the complexity of the use case. They’re particularly useful for analyzing scenarios involving agents, workflows, chat systems, or combinations of these.
When uploading traces from various frameworks, if a session contains only a single trace, the session_id will default to the trace’s ID. If a session contains multiple traces, the session_id will be set to the identifier assigned by the user in the pipeline (and each trace within the session will be represented by a Root interaction with it's descendants)
Interaction (Span)
The interaction is the minimal annotatable unit. It can include input, output, and additional steps along the way. A flow from an initial input to the final output can contain multiple interactions, which should be grouped under a session. Each interaction has an interaction type.
When uploading traces from frameworks - either automatically during runtime or manually afterward - each span is converted into a single interaction within Deepchecks, preserving the structure and hierarchy of the original workflow.
Interaction Type 🧩
Interaction Types define the logical nature of an interaction, allowing the categorization and evaluation of interactions based on their type. Examples of predefined types include Agent, Tool, Q&A, Summarization, Generation, Classification and Other.
Interaction Types are essential for:
- Associating relevant properties with interactions. Properties are defined at the Interaction Type level, allowing flexibility in evaluation.
- Defining auto-annotation YAML configurations for each interaction type, streamlining annotation processes.
- Grouping interactions with similar structures for consistent evaluation and comparison.
Note: Each application can contain multiple interaction types, while one interaction always belongs to a single interaction type. See here for additional information about the default interaction types.
When uploading traces from frameworks each span is assigned an interaction type according to its span kind. For example, an Agent span will be assigned an Agent interaction type.
Extracting a Span to Its Own Interaction Type
If an interaction type contains multiple span names and you want to evaluate them separately, you can extract a span into its own interaction type. This is useful when spans grouped under the same type, such as a Reader and a Writer agent, need different properties or auto-annotation configurations.
To extract a span, navigate to the Interaction Types screen and open the interaction type that contains the span. Under Span Names, click the extract icon next to the span you want to separate. You can then choose to either create a new interaction type or move the span to an existing one.
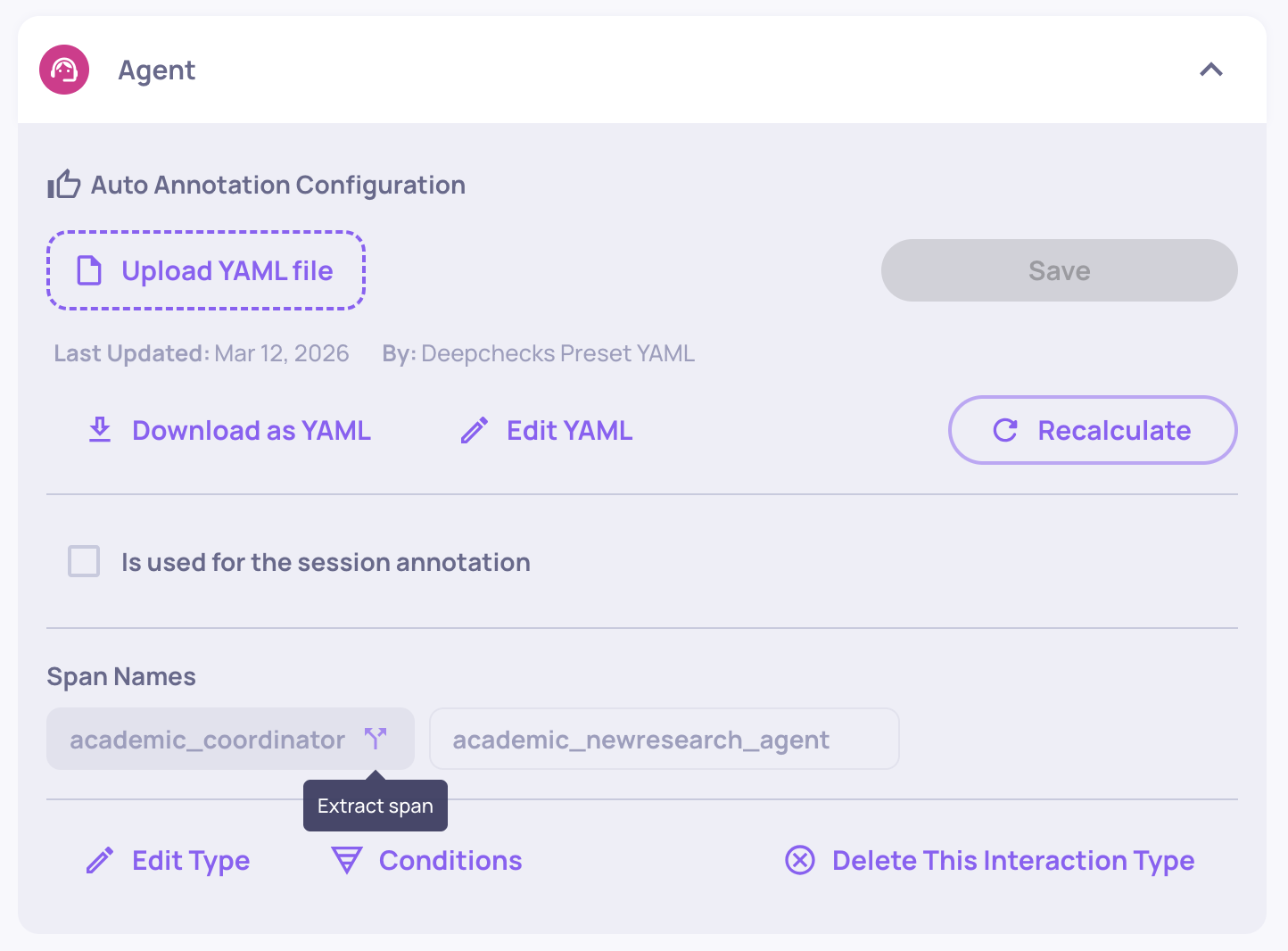
When creating a new type, all configurations (properties, auto-annotation settings) are copied from the original type, and all interactions associated with that span name are moved to the new type. When extracting to an existing type, interactions are moved and properties are matched automatically. Matching properties keep their scores, properties that exist only in the target type will appear as N/A, and properties that exist only in the source type will be removed from the moved interactions.
System Metrics 🕐
Deepchecks lets you upload and visualize system metrics alongside interaction and session data, enabling teams to evaluate not only quality but also operational performance. Metrics such as latency, token usage, and run status are a core part of agent and LLM evaluation, helping teams understand efficiency, cost, reliability, and runtime behavior across their pipelines.
System metrics capture how each interaction is processed. At the interaction level, Deepchecks supports metrics like latency (calculated from start and end times), token usage (input, output and total tokens), run status (indicating whether a span executed successfully), custom metadata such as execution details, and hierarchy metrics (number of descendants, number of unique tools used, etc.). These metrics are also aggregated at the session level to provide a holistic view of performance across multi-step workflows.
Once ingested, system metrics are available throughout the platform: in single session and interaction views, for filtering and sorting in the Interactions screen, and as part of experiment metadata to analyze and compare pipeline versions by both quality and efficiency.
When using Deepchecks tracing integrations, most system metrics are captured automatically. In agentic applications and other pipelines with span hierarchies, system metrics are aggregated across child spans, giving you accurate session-level and agent-level visibility into performance and resource usage.
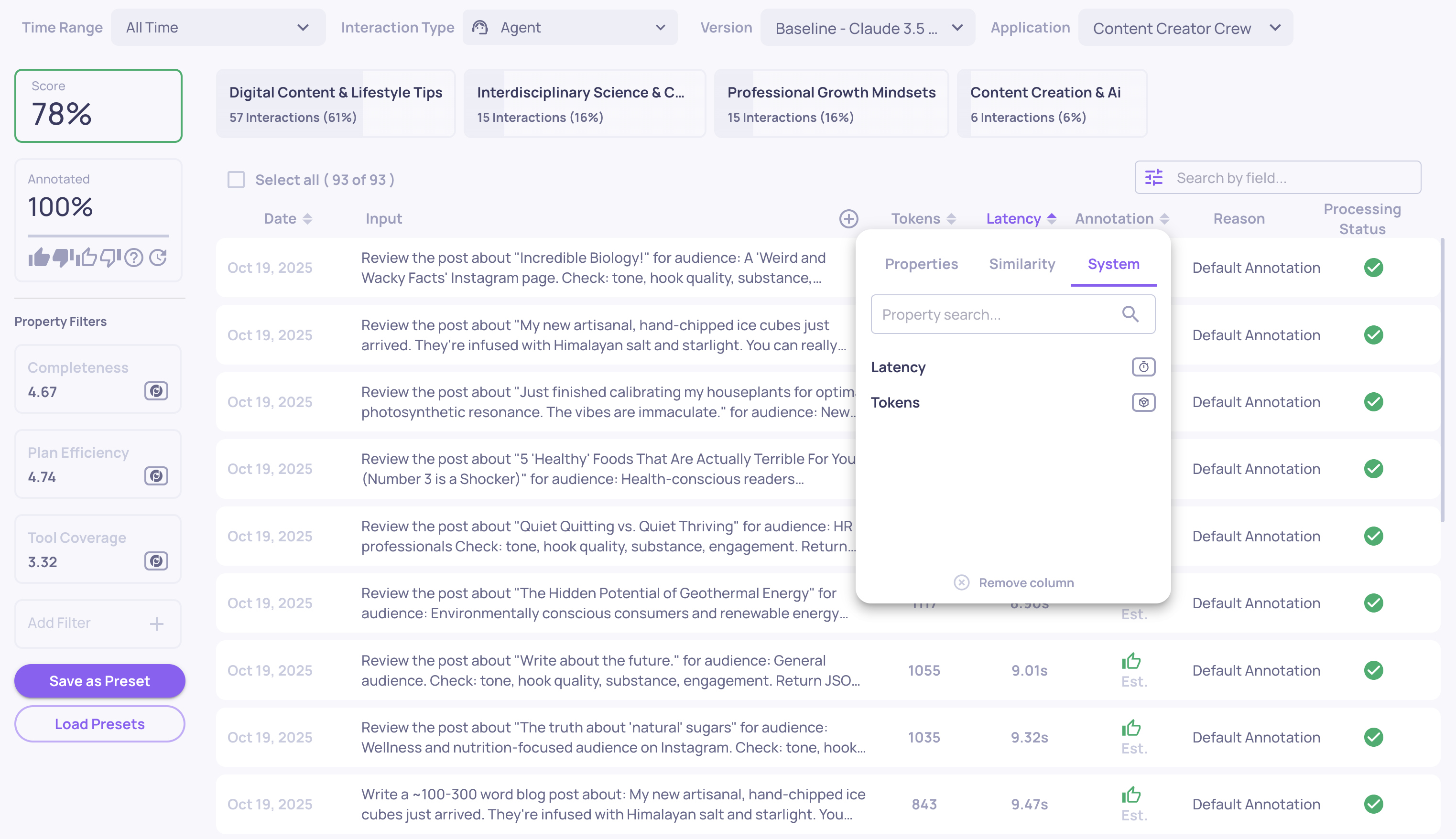
System metrics filtering on the Interactions screen
Data Upload Format: Structure
Uploading Interactions - Target LocationMake sure you have chosen the desired Application, Version & Environment when uploading data to Deepchecks. Whether if you're uploading data from a file, via the system's UI, or with Deepchecks' SDK.
Deepchecks only has access to data that was strictly sent to it for evaluation purposes, in the supported data format (following the structure explained below). Structuring the data correctly is essential so that the evaluation will yield the correct results.
When using tracing integrations to log data to Deepchecks, the platform automatically organizes everything into the correct structure - no manual structuring is needed.
Interactions Overview
Interactions Data FieldsEvery interaction has two kinds of data fields that Deepchecks utilizes:
- Data Content Fields: They contain the actual text from the interaction and are the ones used for the property calculations (with respect to the specific field names and purposes).
- Metadata Fields are everything else: They are used for annotations, enabling version comparison, displaying latency and cost, and much more. All metadata fields are optional.
Each field has its own significance, and almost all of them are optional (though may affect accessible features). Read more about them below:
Interaction Metadata Fields
- user_interaction_id (str) - must be unique within a single version. Used for identifying interactions when updating annotations, and identifying the same interaction across different versions
- session_id (str) - The identifier for the session associated with this interaction. In case your use case only contains a single interaction per flow, ignore this field on data upload.
- started_at (timestamp) - timestamp for interaction start (e.g.
2025-01-01 00:00:01 UTCor Epoch Unix format -1742742893). - finished_at (timestamp) - timestamp for interaction end. Delta with
started_atis used for calculating latency. - interaction_type (str) - Specifying the type of interaction (e.g., Q&A, Summarization). Helps group and evaluate interactions of similar types within an application.
Note: If
interaction_typeis not provided, the default Interaction Type of the application will be assigned. - user_annotation (str) - is the pipeline's output good enough for this interaction? Possible values: Good, Bad, or Unknown.
- user_annotation_reason (str) - textual reasoning for annotation.
All the above fields are optional.
Interaction Data Fields
- input - input for this interaction.
- output - output of this interaction.
- information_retrieval - data retrieved as context for the LLM in this interaction. Separate Documents
- history - additional context relevant to the interaction, which wasn't retrieved from a knowledge base. For example: chat history.
- steps - Additional, custom fields that are part of an interaction such data transformation steps, interaction metadata and so on can be logged as steps. See Uploading Steps.
- full_prompt - the prompt sent to the LLM used in this interaction. For user display, not used for properties.
- expected_output – a reference output serving as the ground truth, typically created by a human annotator or evaluated and deemed high-quality by a human annotator.
All fields are optional, except "input" and "output": every interaction should have at least one of them, and usually both of them.
See Supported Use Cases for further details about the specific content of the data fields for each use caseThere are some nuances for the above field's meaning that vary if the task is Q&A, Summarization, Generation, Classification, or Other.
Updated 25 days ago