Your Own Data: SDK Quickstart
If you need to evaluate your LLM-based apps by: understanding their performance, finding where it fails, identifying and mitigating pitfalls, and automatically annotating your data, you are in the right place!
Setup
Install the Python SDK
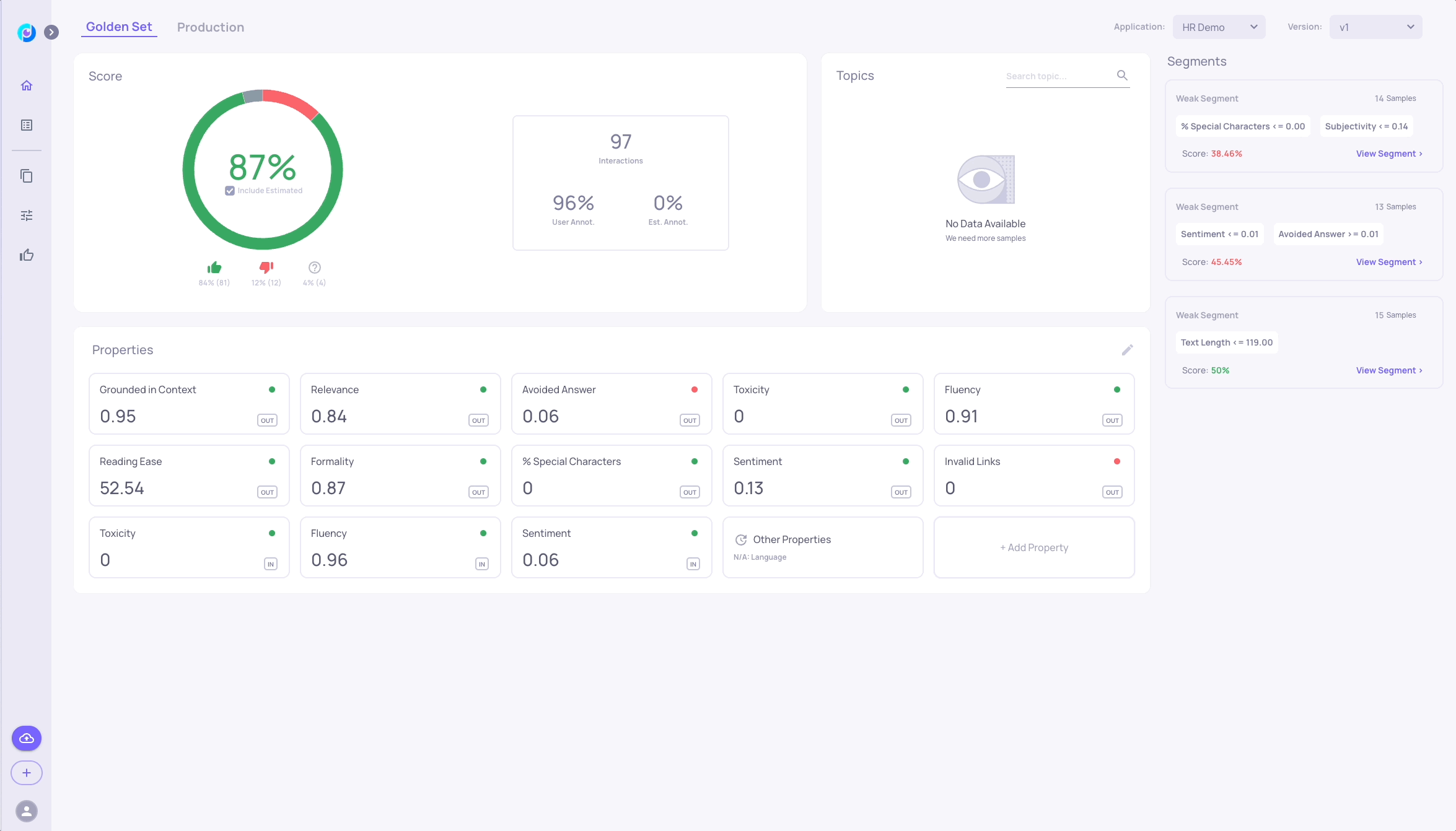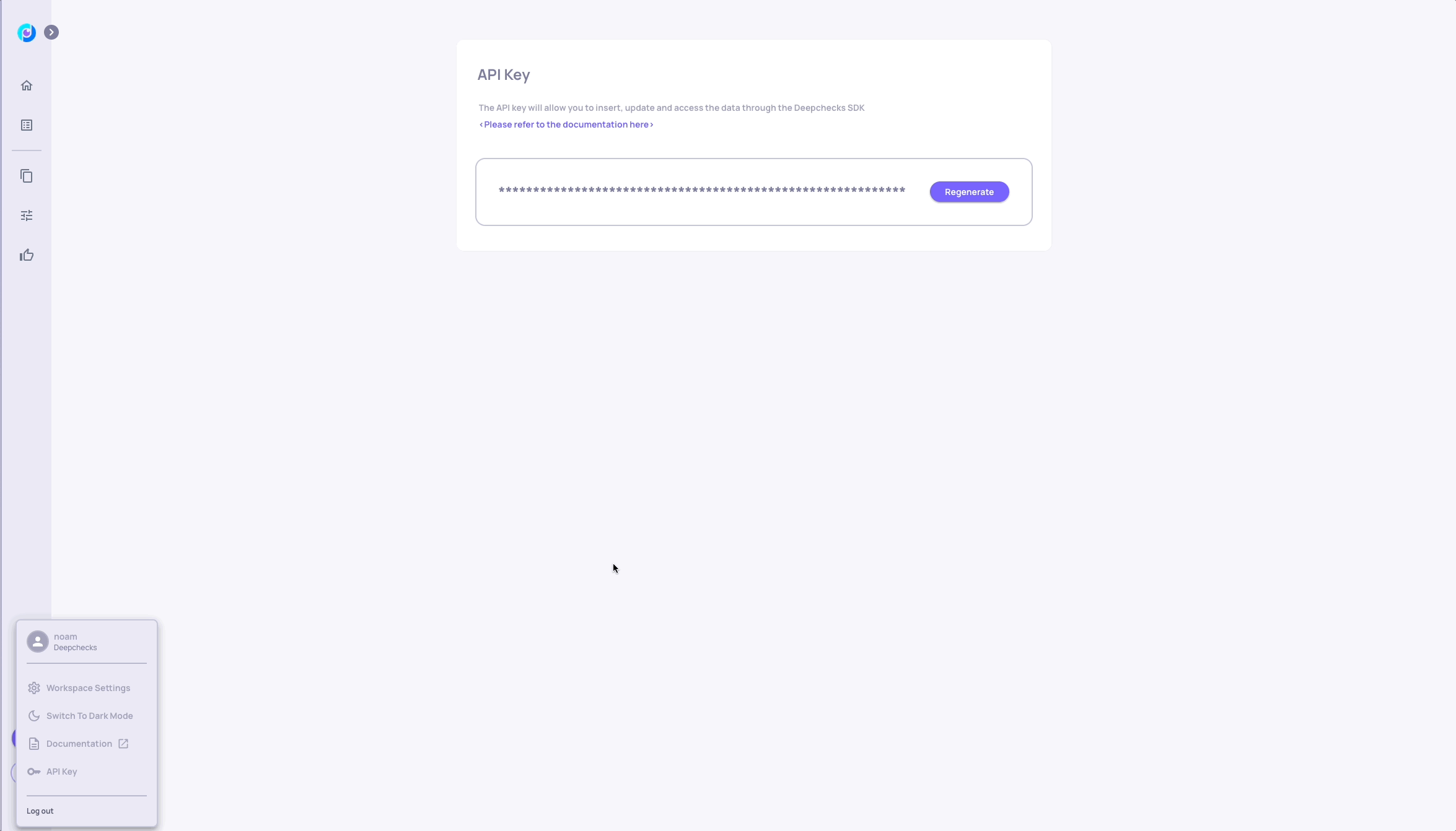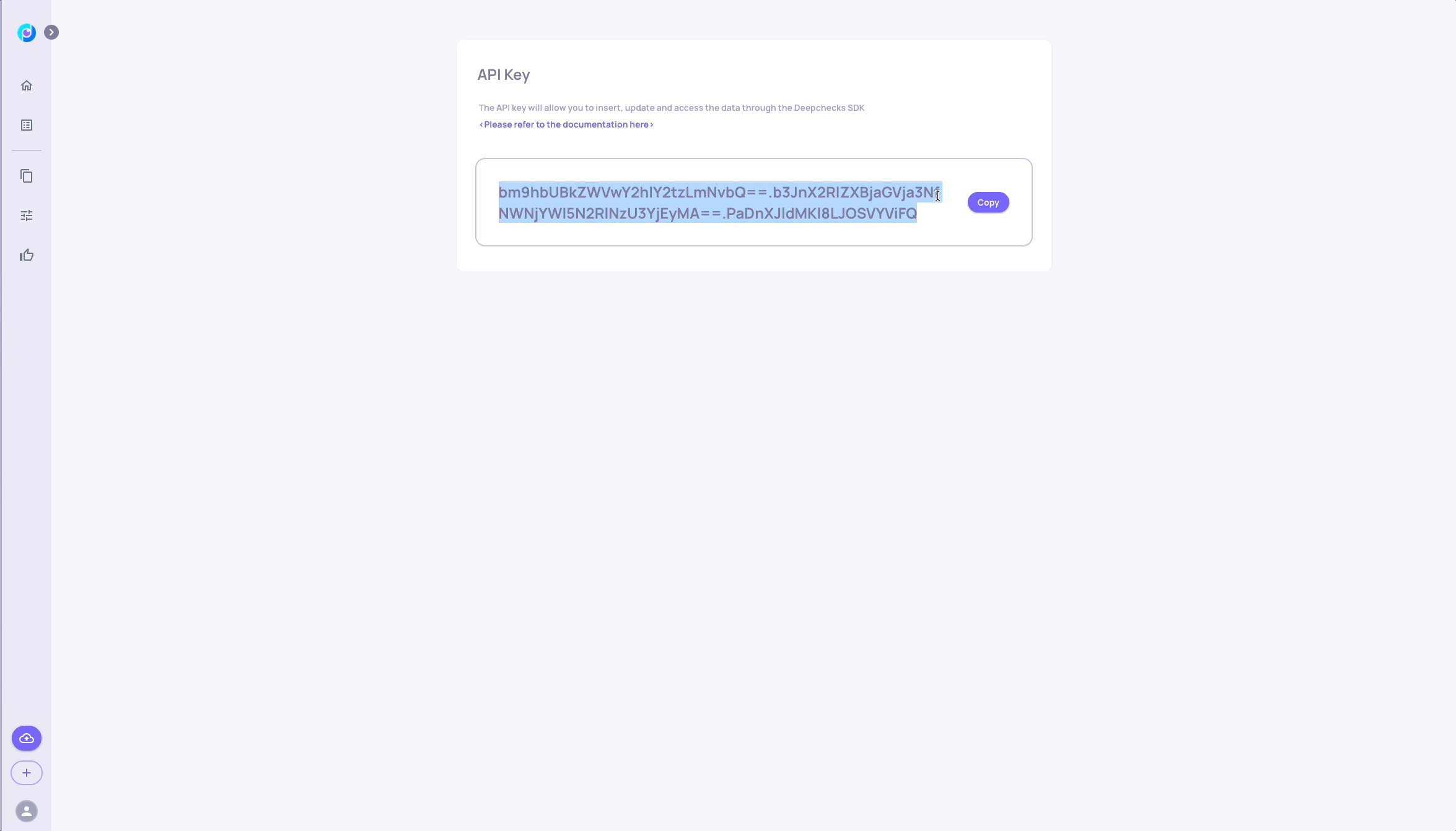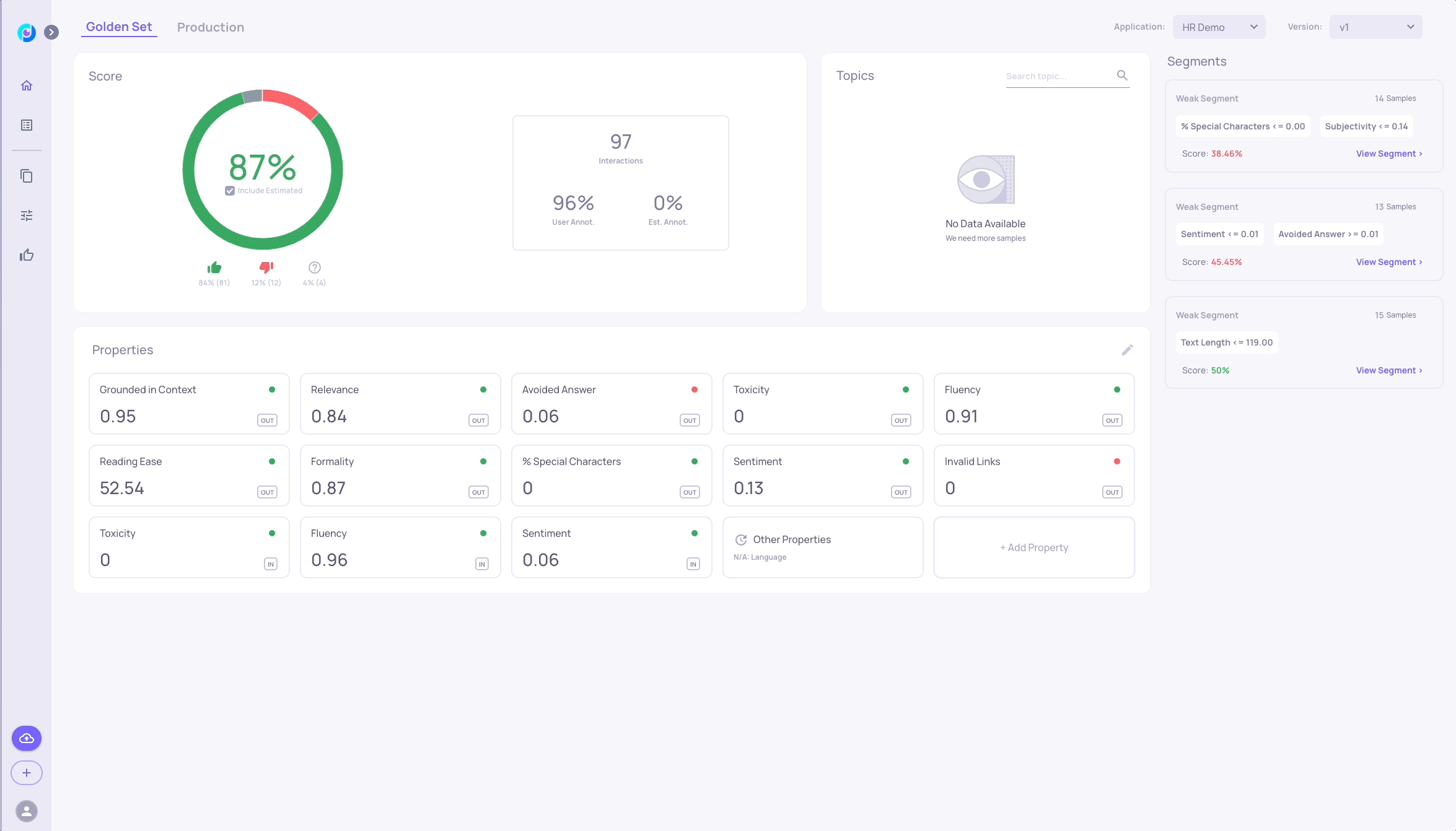
pip install deepchecks-llm-clientGenerate an API Key
Initialize the Deepchecks Client
Before any information can be tracked using the Deepchecks LLM Eval client, you must first initialize a DeepchecksLLMClient instance.
from deepchecks_llm_client.client import DeepchecksLLMClient
dc_client = DeepchecksLLMClient(
api_token="Fill API Key Here"
)
Managing Error HandlingBy default, any issues whilst using the SDK and logging data will result in an error being raised. Since the SDK can be integrated in production environments, we have the option to not to catch these exceptions and instead print error/warn logs. This can be done by setting the
silent_modeflag toTrue. The level of the log used ifsilent_modeisTruecan be set using thelog_levelargument.
Uploading Data to the system
Create an application, if it doesn't already exist
APPLICATION_NAME = "DemoApp"
dc_client.create_application(APPLICATION_NAME, ApplicationType.QA)Intro
Deepchecks LLM Evaluation SDK is a python package built on top of Deepchecks LLM Evaluation REST API, to install it simply run pip install deepchecks-llm-client. The SDK allows interacting with the system: uploading the raw interactions, or downloading the interactions enriched by Deepchecks' Features: properties, topics, annotations, and more.
Note: you can also upload data to the system using CSV/XLSX format directly from the UI
For a comprehensive list of available functionality, please check out the full SDK reference: Python SDK Reference
SDK Minimal Example
Before diving in, let's outline the most basic example for using the SDK to log an interaction to the system.
from deepchecks_llm_client.client import DeepchecksLLMClient
from deepchecks_llm_client.data_types import (EnvType, AnnotationType,
LogInteractionType, ApplicationType)
# Initiate the Deepchecks LLM Evaluation client
dc_client = DeepchecksLLMClient(
api_token="Fill API Key Here"
)
dc_client.create_application("DemoApp", ApplicationType.QA)
# Log two interactions to the system
dc_client.log_batch_interactions(
app_name="DemoApp",
version_name="v1",
env_type=EnvType.EVAL,
interactions=[
LogInteractionType(
input="my user input1",
output="my model output1",
annotation=AnnotationType.GOOD,
),
LogInteractionType(
input="my user input2",
output="my model output2",
annotation=AnnotationType.BAD,
),
]
)
The basic two steps are first initiating the client, and then logging samples to the system. The client, dc_client, can be initiated once within your code and then can be used throughout your application to log interactions.
To better understand what is an application, a version, an environment type and an interaction please refer to the UI Quickstart.
Logging and Downloading Data
Uploading a New Golden Set Version
The Golden Set are the interactions used by you to regularly evaluate your LLM pipeline and to compare its performance between different versions. For that reason, the inputs for the golden set interactions will often be identical between different versions, to enable "apples to apples" comparison between the two versions. The golden set will usually contain a relatively small but diverse set of sample representative of the interactions you've encountered in production.
You will probably start out by collecting these inputs, joined by the outputs generated by your system for these given inputs. If you have these inputs and outputs in a DataFrame, you can upload them using the log_batch_interactions command.
dc_client.log_batch_interactions(
app_name="DemoApp",
version_name="v1",
env_type=EnvType.EVAL,
interactions=[
LogInteractionType(
input=row["input"],
output=row["output"],
user_interaction_id=row['id']
) for idx, row in df.iterrows()
]
)This will upload the data to the application, and will initiate calculation of the various components provided by the Deepchecks LLM Eval system, such as properties, similarity scores and estimated annotations.
Downloading Data
Once the calculations have completed, you may now download a the data "enriched" by the various Deepchecks components.
# To download compoments computed by the system, such as properties and similariy scores,
# request them by setting the relevant arguments to True
dc_df = dc_client.get_data(
"DemoApp",
"v1",
EnvType.EVAL,
return_output_props=True,
return_llm_props=True,
return_similarities=True
)Uploading Further Golden Set Versions
When you've made some changes to your LLM pipeline, you can quickly use the golden set downloaded from the system to generate the outputs for this new version and upload them to the system as well.
golden_set_inputs = dc_df['input']
v2_outputs = v2_llm_pipeline(golden_set_inputs) # Replace this with the code for running your updated LLM pipeline
dc_df['output'] = v2_outputs
dc_client.log_batch_interactions(
app_name="DemoApp",
version_name="v2", # Set dc_client to upload to a new version, named v2
env_type=EnvType.EVAL,
interactions=[
LogInteractionType(
input=row["input"],
output=row["output"],
user_interaction_id=row['id']
) for idx, row in df.iterrows()
]
)- To change the application, version or environment type to which you wish to log your interactions, use the
app_name,version_nameandenv_typearguments of thelog_batch_interactionsmethod.
Uploading Production Data
A further use-case is logging data to production. This can be done inside your production code in the following way:
## Your Production code here
sample_output = your_llm_pipeline(sample_input)
## /End Production code
dc_client.log_interaction(
app_name=app_name, # Application name in production environment
version_name=current_version, # Current production pipeline version
env_type=EnvType.PROD, # Set logging to prod env
input=sample_input,
output=sample_output
)Advanced Logging Options
Updating Annotations and Custom Properties
You can update an annotation and the value of any custom properties:
dc_client.update_interaction(
app_name="DemoApp",
version_name="v2",
user_interaction_id="user_interactions_id_2",
annotation=AnnotationType.GOOD,
annotation_reason=None,
custom_props={"My Custom Property": 1.5}
)Note: Custom Properties must be set using the properties configuration screen before you can log their values using the SDK.
User Interaction IDIn the SDK/API you might see
user_interaction_id, This is your way to set unique identifier for you "inputs", so the same "input" cross versions will get the sameuser_interaction_idIf you maintain such id in your system, please add it when you upload data. You will be able to search by the id from the UI / REST API. This is very helpful in cases were you have feedback you got on a particular interaction and what to observe that interaction in Deepchecks LLM Eval.
Notice that
user_interaction_idmust be unique in the context of a single version!
If you do not set it, Deepchecks will generate global unique UUID and put it in for you.
Steps
In many cases LLM systems are composed of chains of various steps - multiple LLM calls, RAG systems, queries made to some DB and so on. In addition to the key fields of an interaction (input, output, information_retrieval) you may log an arbitrary amount of steps, each containing an input and an output.
from deepchecks_llm_client.data_types import Step, StepType
import uuid
from datetime import datetime, timedelta
dc_client.log_interaction(
"DemoApp",
"v2",
EnvType.EVAL,
input="my user input",
output="my model output",
full_prompt="system part: my user input",
annotation=AnnotationType.BAD,
user_interaction_id=str(uuid.uuid4()),
started_at=(datetime.utcnow() - timedelta(days=1)).timestamp(),
finished_at=datetime.utcnow().timestamp(),
steps=[
Step(
name="Information Retrieval",
type=StepType.INFORMATION_RETRIEVAL,
attributes={"embeddings": "ada-02"},
input="my user input",
output="This is a relevant document for this input"),
Step(
name="LLM",
type=StepType.LLM,
attributes={'model': 'gpt-3.5-turbo'},
input="Full prompt with my user input + the retrieved document",
output="my model output"),
]
)Additional Interaction Data
Interactions have many more fields that can be set when logging. Logging these fields will make them viewable in the system (e.g. Latency, calculated if start and finish times are were logged).
# Log a batch of LLM calls to Deepchecks server
import uuid
from datetime import datetime, timedelta
user_interactions_id_1 = str(uuid.uuid4())
user_interactions_id_2 = str(uuid.uuid4())
dc_client.log_batch_interactions(
"DemoApp",
"v2",
EnvType.EVAL,
interactions=[
LogInteractionType(
input="my user input2",
output="my model output2",
information_retrieval=["my information retrieval2"],
full_prompt="system part: my user input2",
annotation=AnnotationType.BAD,
annotation_reason='Output is not correctly grounded in information retrieval result',
user_interaction_id=user_interactions_id_2,
started_at=(datetime.utcnow() - timedelta(days=1)).timestamp(),,
finished_at=datetime.utcnow().timestamp(),
custom_props={'My Custom Property': 2}
),
LogInteractionType(
input="my user input1",
output="my model output1",
information_retrieval=["my information retrieval - first document",
"my information retrieval - second document"],
full_prompt="system part: my user input1",
annotation=AnnotationType.GOOD,
user_interaction_id=user_interactions_id_1,
started_at=(datetime.utcnow() - timedelta(days=1)).timestamp(),
finished_at=datetime.utcnow().timestamp(),
custom_props={'My Custom Property': 1}
)
]
)OpenAI Call Integration
Example of a simple OpenAI call and how to integrate the input/output into deepchecks LLM.
from deepchecks_llm_client.client import DeepchecksLLMClient
from deepchecks_llm_client.data_types import LogInteractionType, AnnotationType, EnvType
from openai import OpenAI
user_input = "how much is 1 + 1?"
openai_client = OpenAI(api_key="Fill OpenAI API Key Here")
chat_completion = openai_client.chat.completions.create(
model="gpt-3.5-turbo",
temperature=0.7,
messages=[
{"role": "system", "content": "you are a calculator"},
{"role": "user", "content": user_input},
]
)
dc_client = DeepchecksLLMClient(api_token="YOUR_API_KEY")
dc_client.log_interaction(
app_name="Test app",
version_name="test_sdk",
env_type=EnvType.EVAL,
input=user_input,
output=chat_completion.choices[0].message.content,
annotation=AnnotationType.GOOD # Optional annotation
)Langchain Tracing
You can automatically trace your Langchain calls using our Langchain Tracing SDK integration.
Full Use Case
Let's now outline how you would upload a complete version to the system.
# In this code snippet we demonstrate how to upload Evaluation data (Golden Set)
# to Deepchecks' LLM Evaluation using our python SDK
import uuid
from datetime import datetime
import pandas as pd
from deepchecks_llm_client.client import DeepchecksLLMClient
from deepchecks_llm_client.data_types import EnvType, AnnotationType, LogInteractionType, Step, StepType
# Login to deepchecks' service and generate new API Key (Configuration -> API Key) and place it here
DEEPCHECKS_LLM_API_KEY = "YOUR API KEY"
# Use "Update Data" in deepchecks' service, to create a new application name and place it here
# This application must be exist, deepchecks' SDK cannot function without pre-defined application
# to work with
DEEPCHECKS_APP_NAME = "DemoApp"
# download data and read as csv
df = pd.read_csv('https://figshare.com/ndownloader/files/44077487')
# Init SDK's client
# Please notice - when using Deepchecks' SDK in an environment that rquires that exceptions won't stop
# execution, please set the silent_mode argument to True
dc_client = DeepchecksLLMClient(
api_token=DEEPCHECKS_LLM_API_KEY
)
# Log a batch of 97 LLM calls to Deepchecks server, some with user annotations and some without
dc_client.log_batch_interactions(
app_name=DEEPCHECKS_APP_NAME,
version_name="0.0.1",
env_type=EnvType.EVAL,
interactions=[
LogInteractionType(
input=row["input"],
output=row["output"],
information_retrieval=row["information_retrieval"],
user_interaction_id=idx,
annotation=AnnotationType.UNKNOWN if pd.isnull(row["annotation"]) else (
AnnotationType.GOOD if row["annotation"] == 'Good' else AnnotationType.BAD),
) for idx, row in df.iterrows()
]
)
print(f"Created version 0.0.1 in deepchecks server")
# Add another version equivalent to the first, this time logging the individual steps.
def log_eval_interactions(app_name, version, env, df):
interactions = []
for index in range(len(df)):
interaction = df.iloc[index]
steps = []
# Append the data retriever (information retrieval) step
steps.append(Step(
name='Data Retriever',
type=StepType.INFORMATION_RETRIEVAL,
started_at=datetime.now().astimezone(),
input=str(interaction['input']),
output=str(interaction['information_retrieval']),
finished_at=datetime.now().astimezone(),
attributes={'model': 'gpt-3.5-turbo'}
))
# Append the full prompt and response step
steps.append(Step(
name='LLM',
type=StepType.LLM,
started_at=datetime.now().astimezone(),
input=str(interaction['full_prompt']),
output=str(interaction['output']),
finished_at=datetime.now().astimezone(),
attributes={'model': 'gpt-3.5-turbo'}))
interaction_to_log = LogInteractionType(
input=steps[0].input,
output=interaction['output'],
user_interaction_id=index,
steps=steps,
)
# Annotate the current interaction if annotation is provided
if not pd.isna(interaction['annotation']):
interaction_to_log.annotation = AnnotationType.GOOD if interaction['annotation'] == 'Good'\
else AnnotationType.BAD
else:
interaction_to_log.annotation = AnnotationType.UNKNOWN
interactions.append(interaction_to_log)
dc_client.log_batch_interactions(app_name, version, env, interactions)
log_eval_interactions(DEEPCHECKS_APP_NAME, '0.0.2', EnvType.EVAL, df)
print(f"Created version 0.0.2 in deepchecks server")You can now access the version created in the system at https://app.llm.deepchecks.com/?appName=DemoApp&versionName=0.0.1&env=EVAL, or by searching for the new application name within the "Applications" selection. After a short while, properties and estimated annotations will be calculated (see the Properties Guide and UI Quickstart for more information about these).