Deepchecks' UI
Quickly onboard to the system using only a csv file
This quickstart is the place to start if you are new to Deepchecks LLM Evaluation. We'll walk you briefly through uploading data to the system and using the system to automatically annotate the outputs of your LLM pipeline.
Demo LLM ApplicationWe will be using as an example a simple Q&A Bot, based on the Blendle HR manual. This simple langchain based bot is intended to answer questions about Blendle's HR policy. It receives as input user questions, performs document retrieval to find the HR documents that have the best chance to answer the given question and then feeds them to the LLM (in this case, gpt-3.5-turbo) alongside the user question to generate the final answer.
Uploading Data
Upon signing into the system, you will either be presented right away with the Upload Data screen, or with the Dashboard (if you have already uploaded interactions previously). In the second case, click the "Upload Data" button in the bottom left side to open the Upload Data screen.
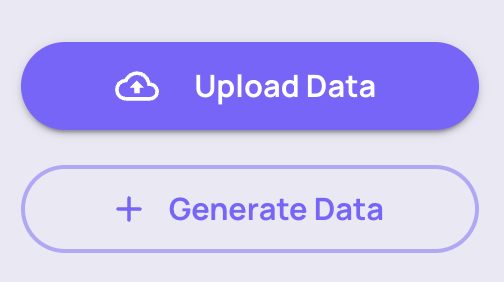
In order to upload interactions, select an application and application version. An application represents a specific task your LLM pipeline is performing (in our case - answering HR-related question of Blendle employees). A Version is a specific version of that pipeline - for example a certain prompt template fed to gpt-3.5-turbo.
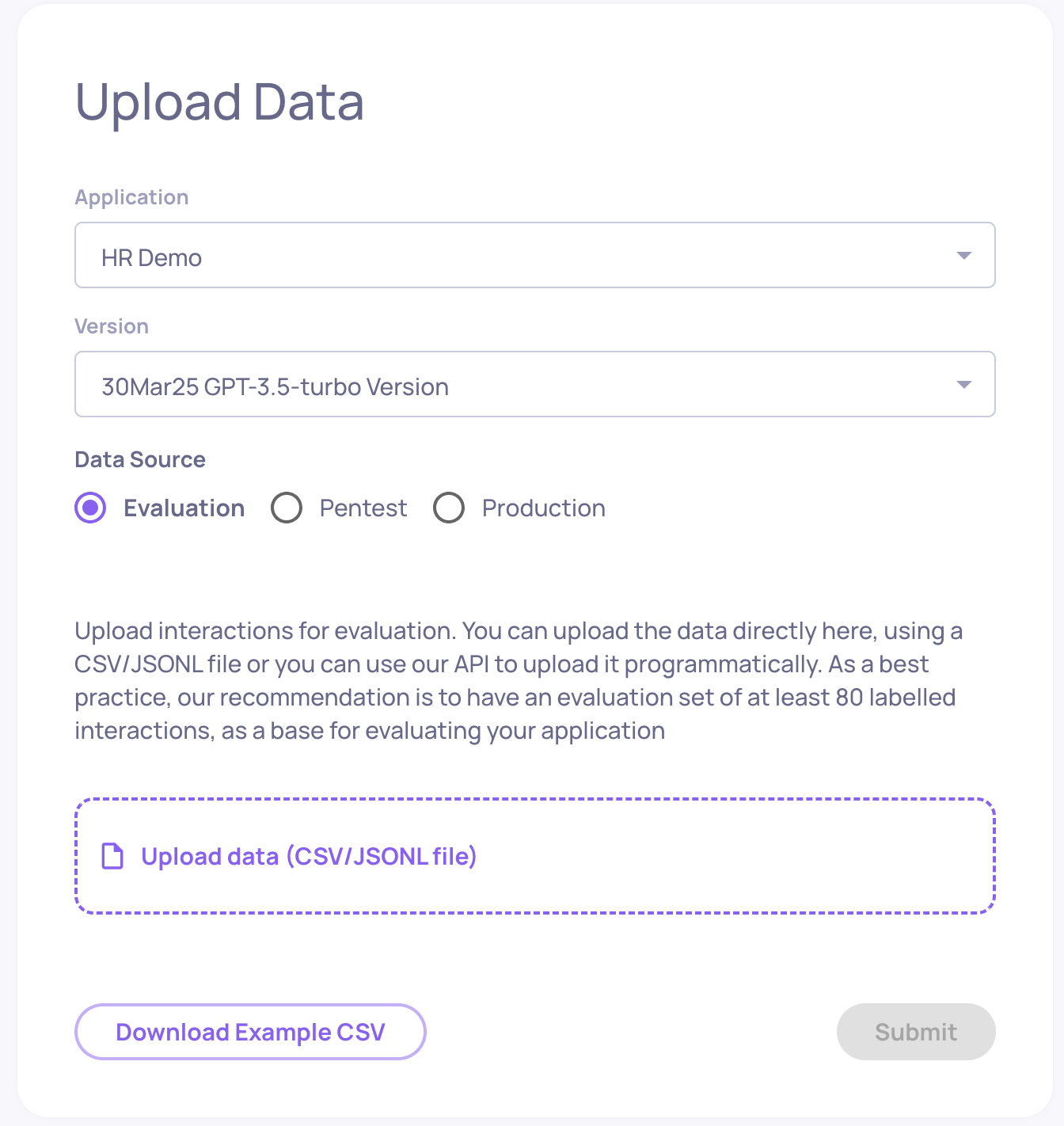
Names selected, you can now upload your data. The data you're uploading should be a csv file reflecting individual interactions with your LLM pipeline. The structure of this csv should be the following:
user_interaction_id | session_id | input | information_retrieval | full_prompt | output | annotation | interaction_type | step_my_step | step_my_additional_step | started_at | finished_at |
|---|---|---|---|---|---|---|---|---|---|---|---|
Must be unique within a single version. Used for identifying interactions when updating annotations, and identifying the same interaction across different versions | (optional) The identifier for the session grouping related interactions. | (mandatory) The input to the LLM pipeline | Data retrieved as context for the LLM in this interaction | The full prompt to the LLM used in this interaction | (mandatory) The pipeline output returned to the user | Was the pipeline response good enough? | Specifies the type of interaction (e.g., Q&A, Summarization). Defaults to the application kind if not provided. | Specifies any logical steps of your application to indicate its internal logic. | This column is translated as a key/value representation of the step used in the model. order matters, the order in which you create the columns will determine the order of the steps | Specifies the time stamp of the start of the interaction (e.g. 2025-01-01 00:00:01 UTC) | Specifies the time stamp of the end of the interaction (e.g. 2025-01-01 00:00:02 UTC |
CSV Upload NoteData can be uploaded to the Deepchecks app using a CSV file as long as the file contains an input and output. All other fields are not mandatory. If the "user_interaction_id" field is empty for a certain interaction, the Deepchecks app will assign it a random ID.
You can download the data for the Blendle HR Bot, GPT-3.5-prompt-1 version here. This dataset contains 97 interactions with the bot, alongside human annotations for some of the interactions.
Dashboard and Properties
Once the data has been uploaded you are directed to the dashboard. The dashboard serves to give you a high level status of your system. The Score section lets you see what percent of interactions are annotated, and what percent out of the annotated interactions represent good interactions.
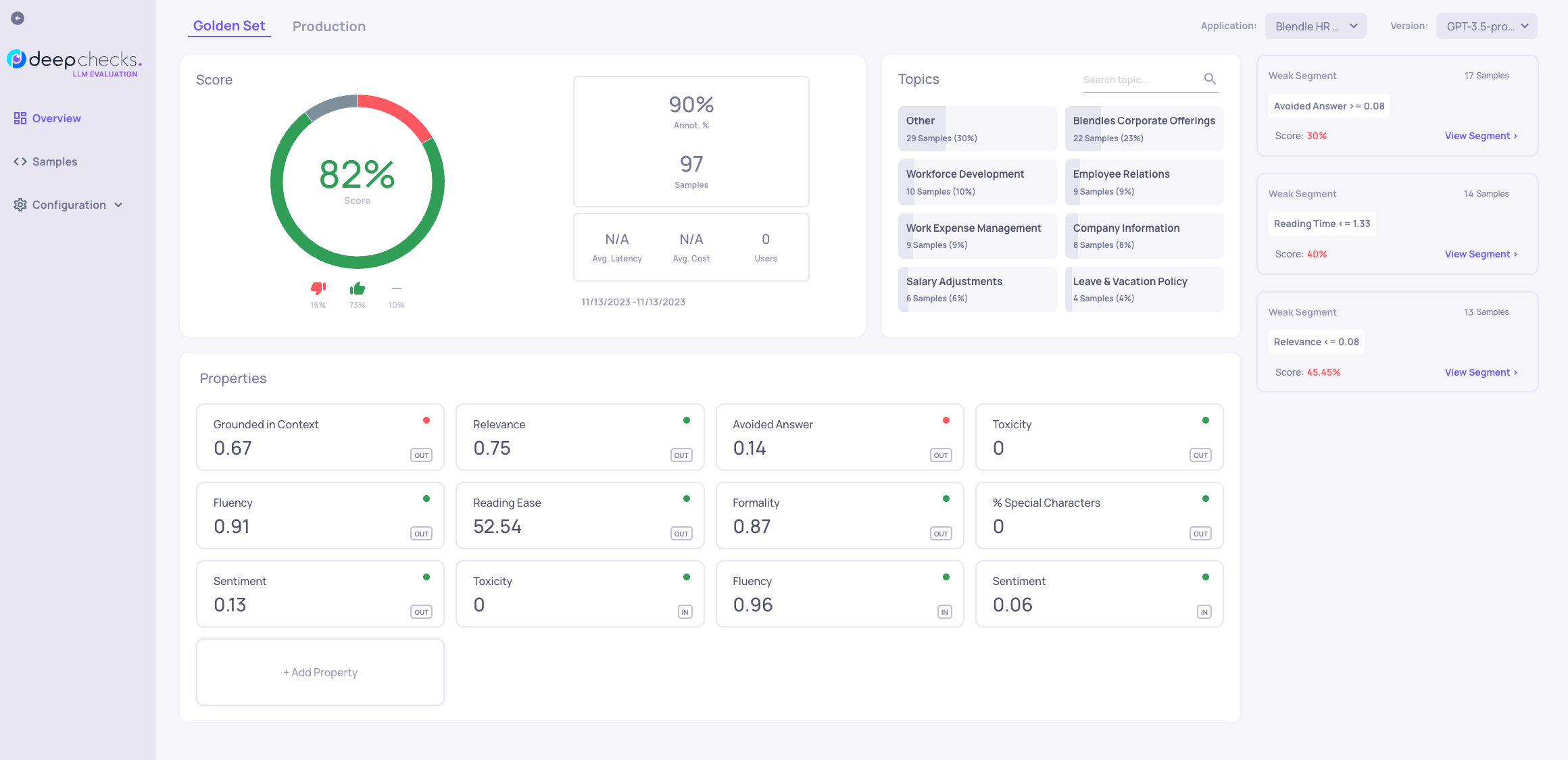
Below it is the Properties section. Properties are characteristics of the interaction user input or model output that are calculated for each interaction. In this section, the average value of these properties is presented, and anomalous values are flagged. For example, in the image above we can see that 14% percent of the model outputs were detected as "Avoided Answers", meaning that the model avoided answering the user question for some reason. You can read more about the different kinds of properties here.
Data Page
The data page is the place to dive deeper into the individual interactions. You can use the filters (both on topics, annotations and properties) to slice and dice the dataset and look at the interactions relevant for you, or click on the individual interactions to inspect their components and view and modify the interaction's annotations.
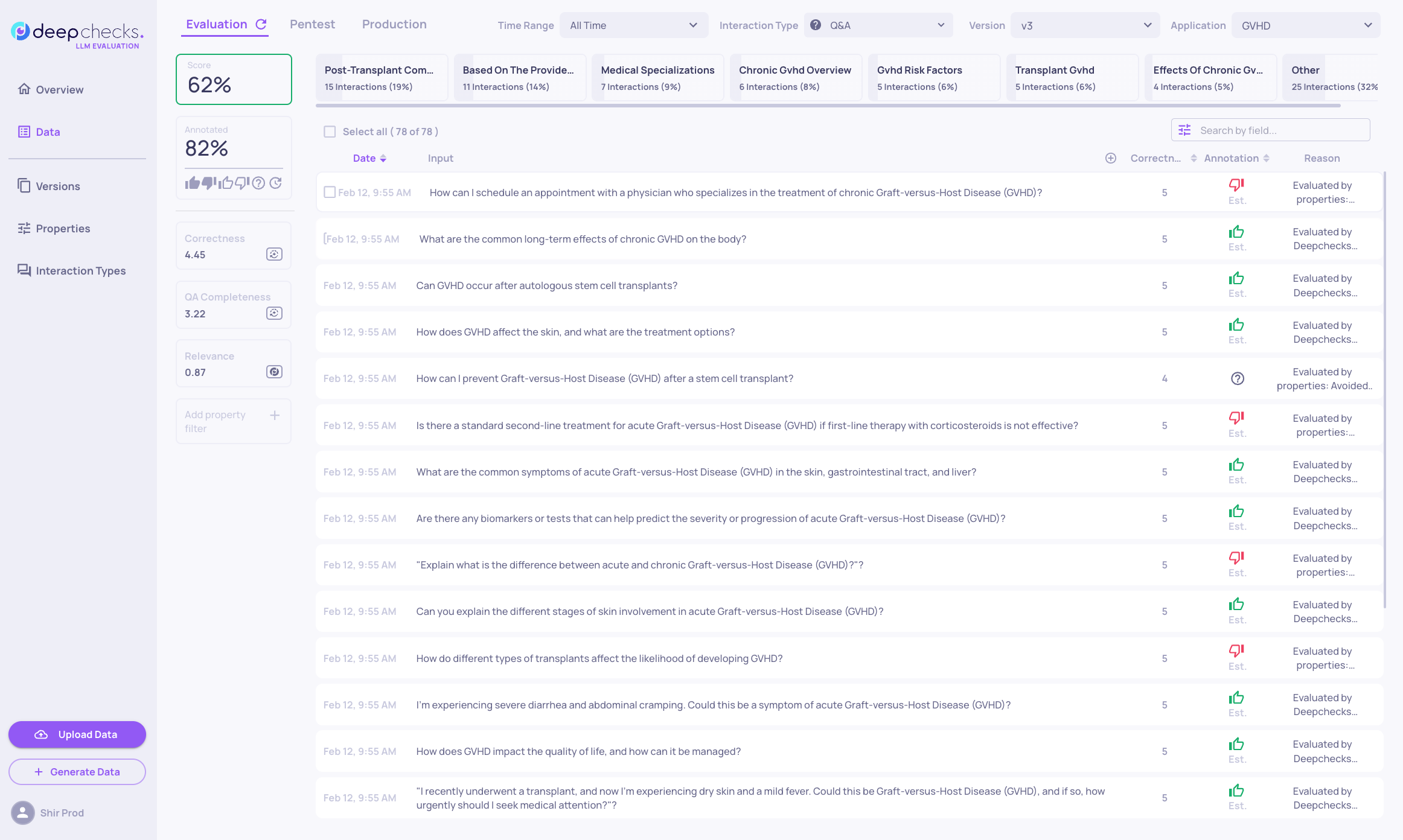
Estimated Annotations
While the full colored annotations are provided by you (in the "annotations" column of the csv), estimated annotations (marked by having only colored outlines) are estimated by the system. These estimations are made by Deepchecks Automatic Annotations pipeline and can be configured and customized to your needs.