Analyze Multi-Agent Performance
Once the traces start flowing in, open the application in Deepchecks. The first thing you see is the Overview - a single screen that summarizes the health of the entire application.
The Headline Score Is Misleading by Design
The top-line Overview score for this app comes in low. On its own, that number is almost useless - it tells you something is wrong but nothing about where. Treat it as a smoke alarm, not a diagnosis.
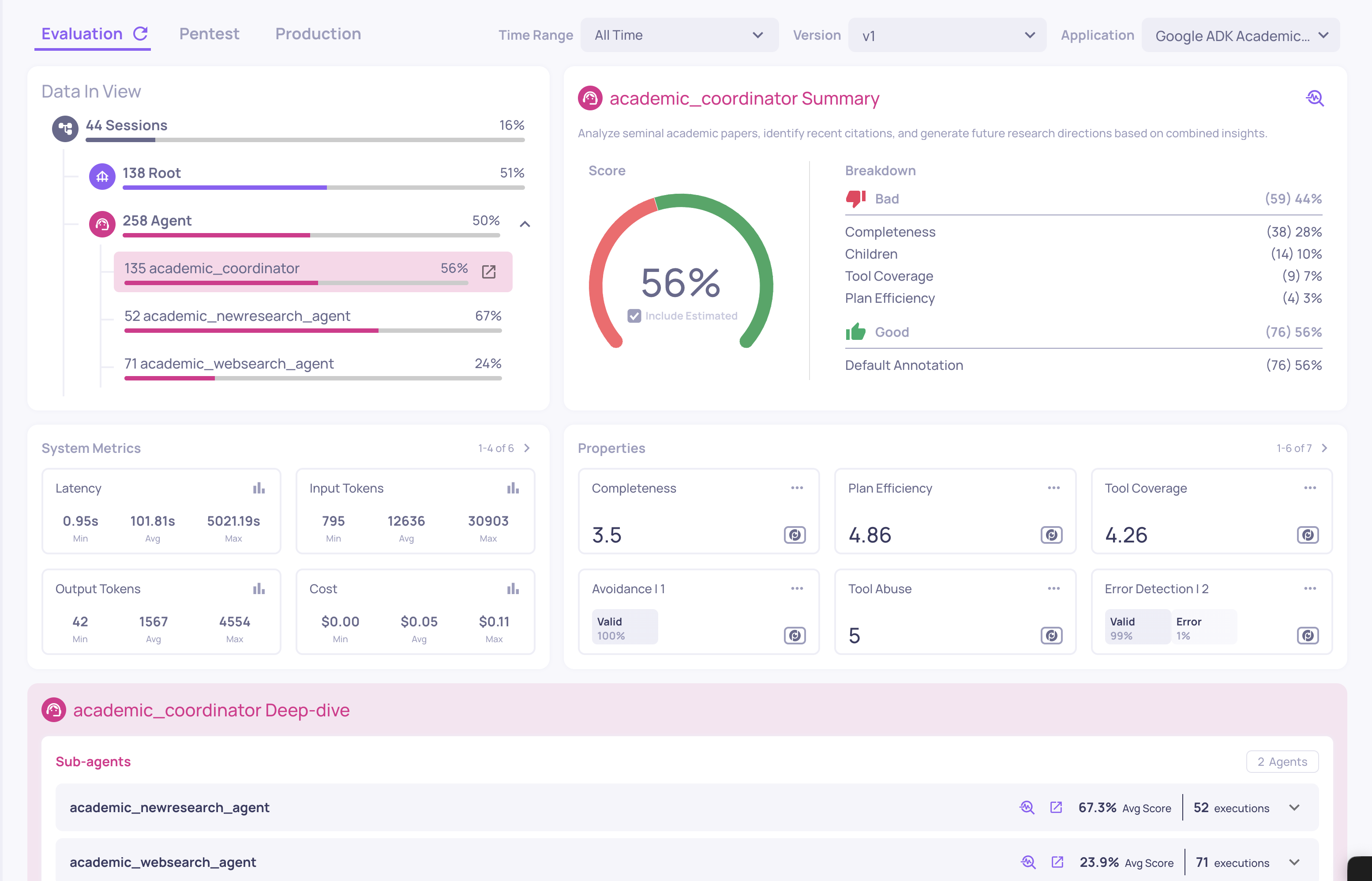
Break Down by Interaction Type
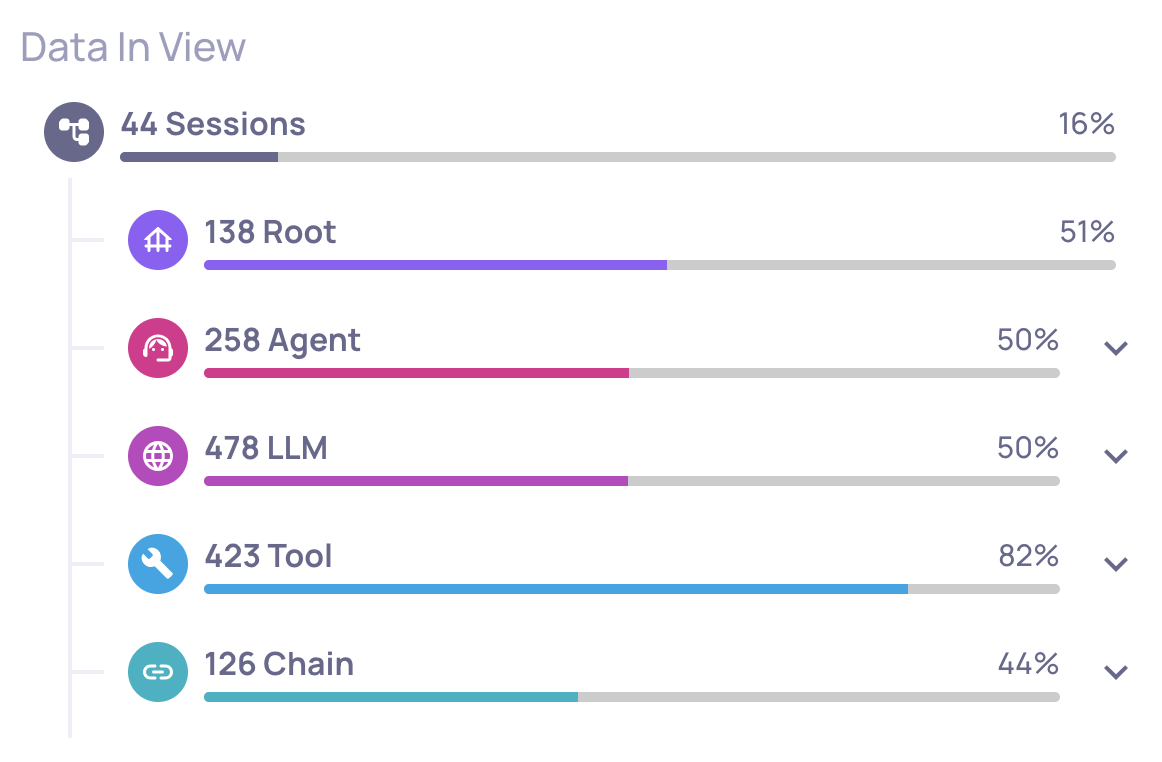
The left-hand panel of Overview splits the score across interaction types:
- Root - the end-to-end traces from the user's point of view.
- Agent - each autonomous agent (here: the coordinator, the web-search agent, the new-research agent).
- LLM - every individual language model call.
- Tool - every tool invocation (here: the
web_searchtool).
For this demo the breakdown reveals something counterintuitive:
- Tool (web_search): very high. The tool executes flawlessly almost every time - valid JSON, real results, no API errors.
- Agent (academic_websearch_agent): low. The agent using that tool is the problem.
- LLM calls: middling. Reasoning quality is uneven.
The takeaway: the tool works; the agent using it doesn't. That distinction is impossible to see if you look only at aggregate scores or at raw logs. It is the whole reason Deepchecks evaluates each span and each interaction type independently.
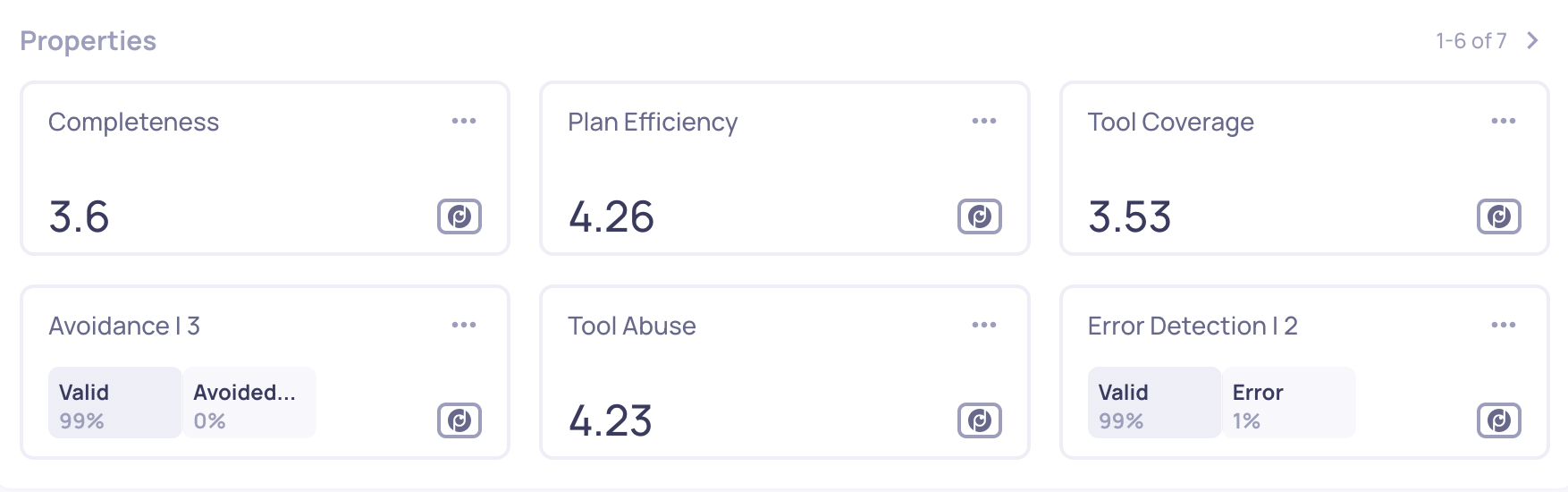
The Properties (Quality Metrics) Being Applied
Each interaction type has its own property set - small evaluators that measure specific dimensions of behavior. For this multi-agent app, the important ones are:
Agent properties (applied to the coordinator and sub-agents)
- Tool Coverage - did the agent retrieve all the information it needed from tools before answering?
- Plan Efficiency - did the agent use its tools appropriately, without redundant or missing steps?
- Tool Abuse - did the agent call tools unnecessarily or with malformed arguments?
- Instruction Following - did the agent follow its system prompt?
LLM properties (applied to every LLM call)
- Reasoning Integrity - is the LLM's reasoning coherent and consistent with the context?
- Instruction Following - did the LLM follow the instructions it was given?
Tool properties
- Tool Completeness - did the tool response actually fulfill its intended purpose?
Where to Go Next
The per-interaction-type panel has told us the Agent layer is the weak link. The next step is to evaluate the agent not just at the span level but across entire multi-turn sessions, then drill into the root cause.