Run a Version Comparison
Step-by-step guide to comparing two or more versions of your LLM application in Deepchecks - from uploading against a shared dataset to picking a winner.
Version comparison answers: which prompt, model, or configuration change actually made things better? This guide walks through the full workflow - from uploading your versions to reading the comparison results.
→ For an overview of the comparison screens and features, see Version Comparison.
Prerequisites
For a meaningful comparison, every version you compare should run on the same inputs. That means:
- You have an evaluation set that all versions are tested against
- Each version's interactions use the same
user_interaction_idvalues - this is how Deepchecks pairs interactions across versions for side-by-side comparison
If your versions have different inputs, you can still compare at the high-level metrics level, but you won't be able to use granular interaction-by-interaction comparison.
Step 1: Upload each version against your evaluation set
For each version you want to compare, run your pipeline on the evaluation set inputs and log the outputs to Deepchecks with env_type=EVAL:
from deepchecks_llm_client.client import DeepchecksLLMClient
from deepchecks_llm_client.data_types import EnvType, LogInteraction
dc_client = DeepchecksLLMClient(api_token="YOUR_API_KEY")
# Get your evaluation set inputs
eval_data = dc_client.get_data(
app_name="my-app",
version_name="eval-set",
env_type=EnvType.EVAL
)
# Run your new version and log results
interactions = []
for _, row in eval_data.iterrows():
output = my_pipeline_v2(row["input"]) # your new version
interactions.append(LogInteraction(
input=row["input"],
output=output,
user_interaction_id=row["user_interaction_id"], # critical for pairing
))
dc_client.log_batch_interactions("my-app", "v2", EnvType.EVAL, interactions)Repeat for each version you want to compare.
Step 2: Rank versions on the Versions screen
Go to the Versions screen. You'll see all versions with their overall score, property averages, latency, and token usage.
Sort by Score w. Est to rank versions by their annotation score. To focus on a few finalists, click the up-arrow icon next to any version to stick it to the top of the list.
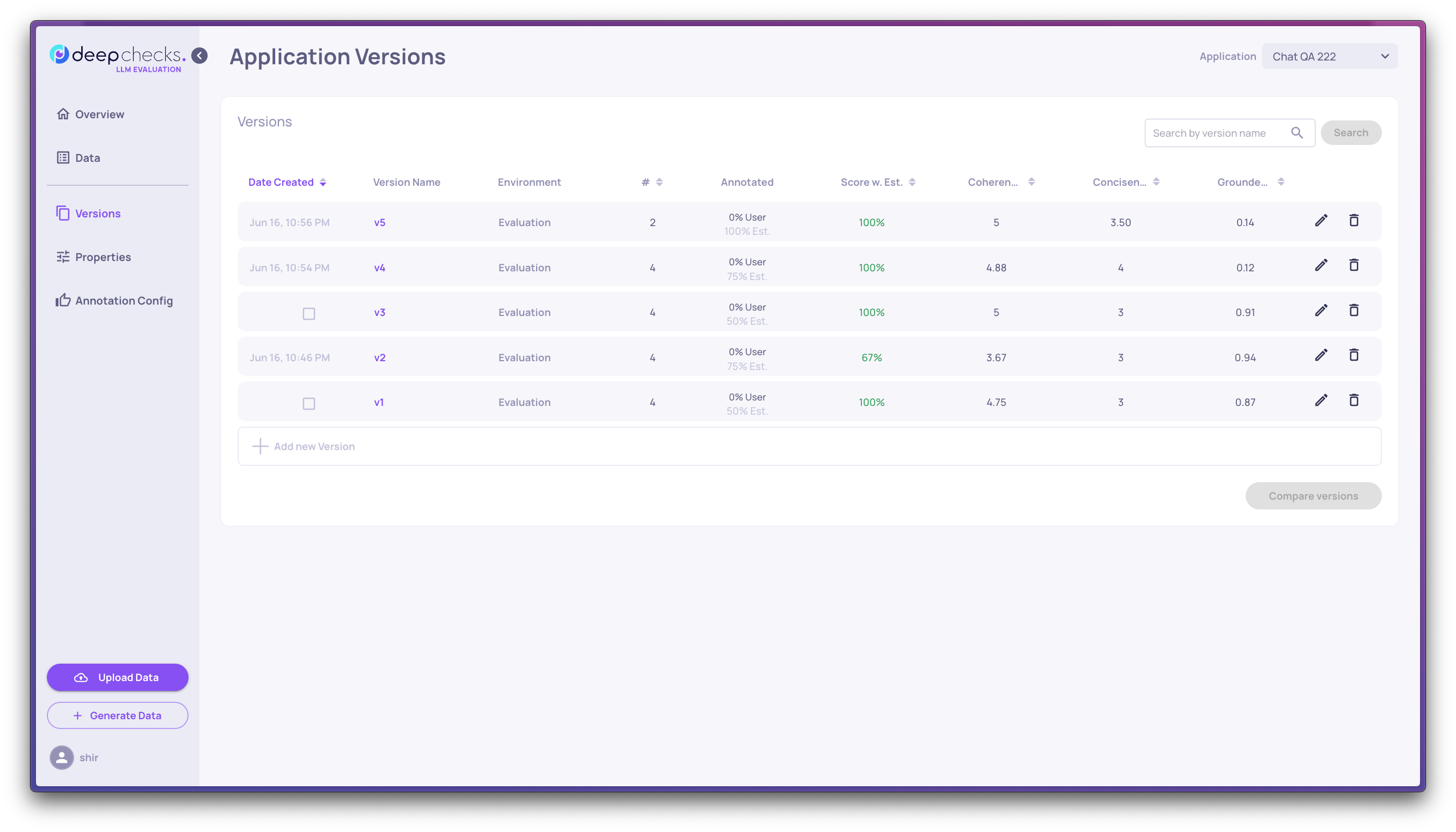
At this stage you're looking at: which version scores best overall, and on which properties?
Step 3: Select two versions for granular comparison
Select exactly two versions and open the comparison view. This shows interactions side by side - the same inputs, different outputs, with scores and annotations for each.
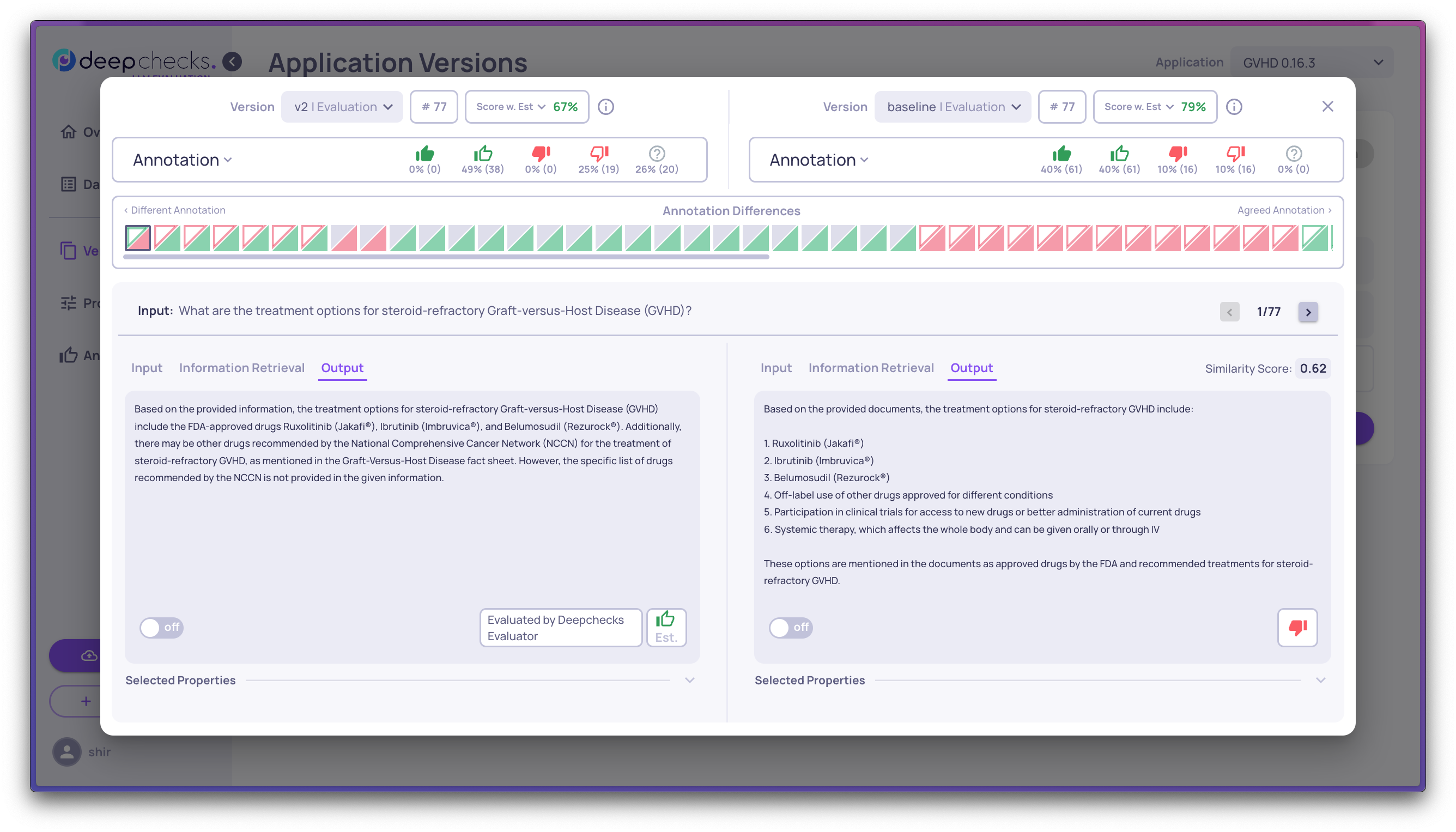
Choose what to focus on:
- Most different outputs (lowest similarity) - find where the versions diverge most
- Property score differences - filter by a specific property to see where one version outperforms the other
- Annotation differences - show only pairs where the two versions got different Good/Bad labels
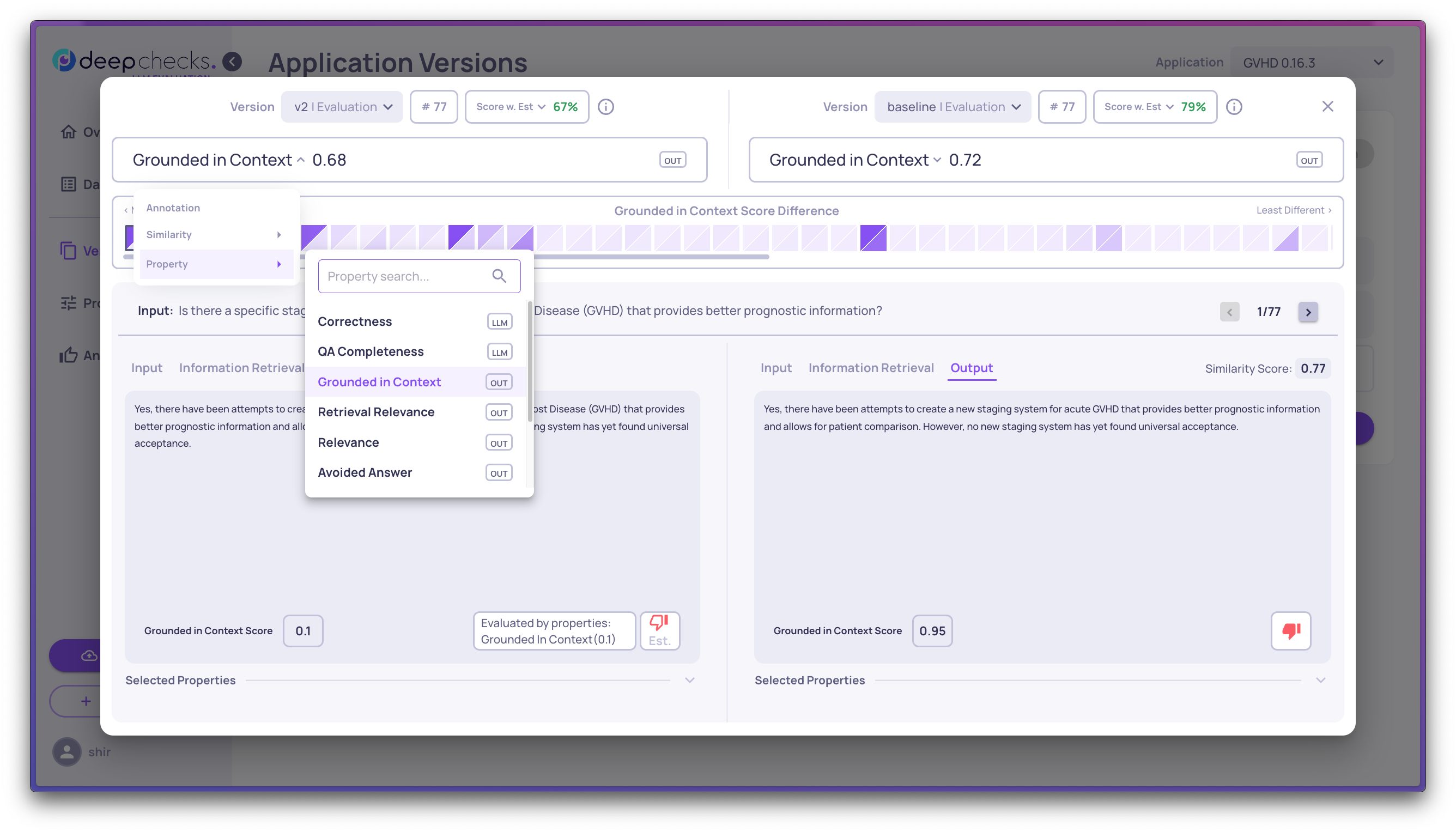
Step 4: Read the star ratings
Each interaction pair gets a star next to the better version, based on the average of the first three pinned numerical properties. A star at the version level marks the overall winner.
Hover over any star for a tooltip explaining the reasoning.
Use this to quickly spot: does v2 win consistently, or only on certain types of interactions?
Step 5: Investigate regressions
A new version often improves some things while breaking others. To find regressions:
- Filter for interactions where v1 was Good but v2 is Bad
- Review those interactions side by side - what changed that hurt them?
- Filter the opposite way (v1 Bad, v2 Good) to confirm your improvements worked
This is the most efficient way to characterize what a new version actually changed.