Evaluate Multi-Turn Sessions
Span-level evaluation answers "did this step do its job?". But in a multi-turn assistant, that is only half the story. A user does not care whether each individual LLM call was coherent in isolation - they care whether the conversation as a whole got them what they asked for.
Deepchecks evaluates both levels.
Sessions vs. Traces vs. Spans
Quick recap of the hierarchy:
- Span - one unit of work (one LLM call, one tool invocation, one agent reasoning loop).
- Trace - all the spans produced by a single user request (one turn).
- Session - all traces from a single end-to-end conversation (possibly multiple turns).
The Academic Researcher is deliberately built so the coordinator may run for several turns - the user describes a paper vaguely, the agent asks for clarification, the user narrows it down, the agent performs the analysis.
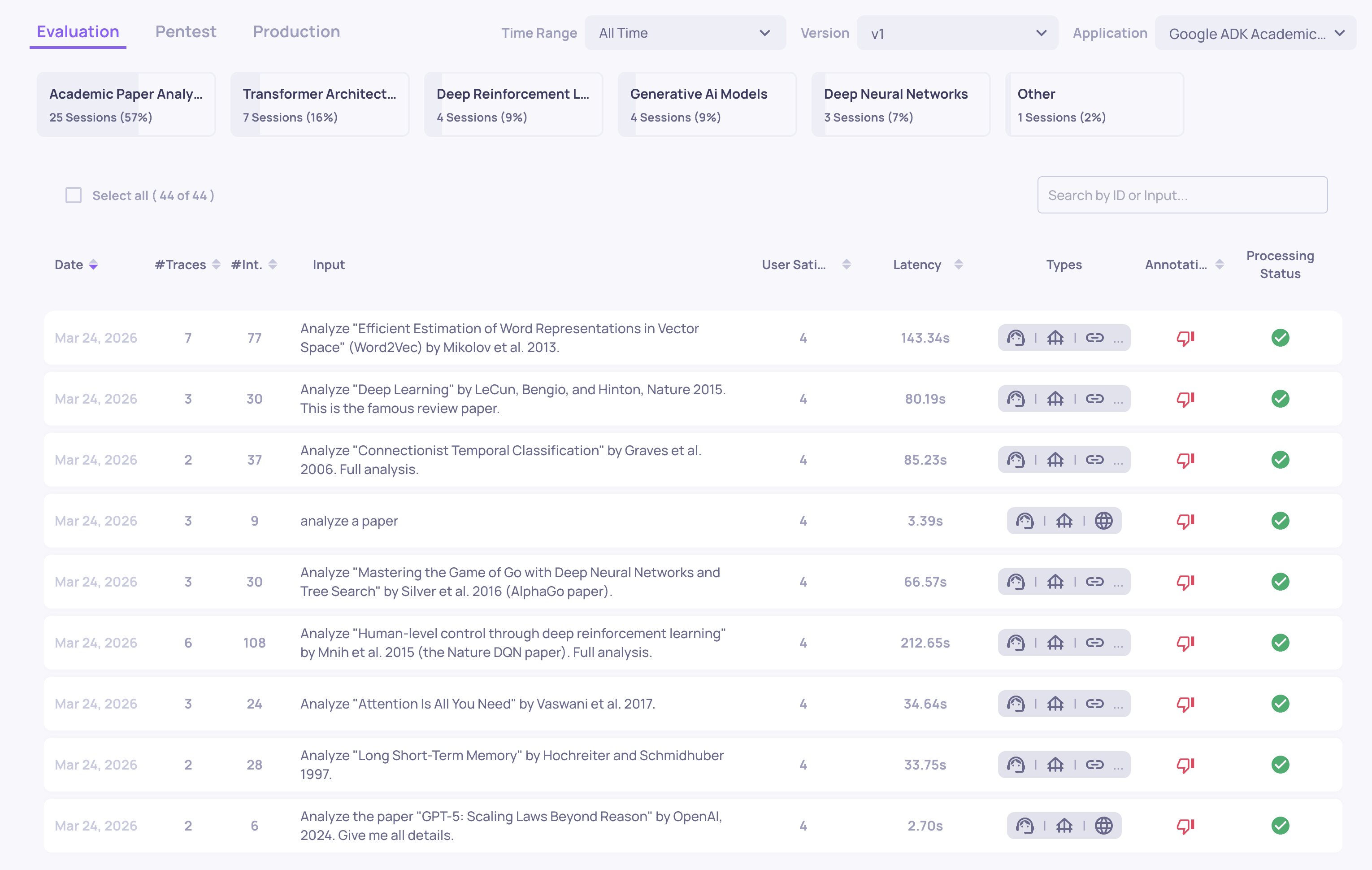
Opening the Sessions Screen
The Sessions screen shows every session as a row, ordered by default by time. Each row shows:
-
The full input → output for the session (collapsing all turns).
-
Session-level annotation (
Good/Bad/Unknown) computed across the conversation. -
Any session-level properties you have configured.
Clicking a session opens the Session View - the full parent/child graph of every trace and every span across all turns.
Session-Level Properties
On top of the span-level properties, Deepchecks can evaluate properties that judge the session as a whole - for example:
- Did the agent ultimately fulfill the user's request across all turns?
- Did information carry forward correctly between turns?
- Did the conversation meander, backtrack, or repeat itself?
This is where multi-turn failures surface that no single span could reveal. A conversation can consist of individually-fine turns and still fail collectively - the agent answered every turn politely but never actually delivered the analysis the user was asking for.
The Multi-Turn Failure Modes We Found
Looking at the multi-turn sessions, two recurring patterns showed up:
1. Dropped context on handoff
When the coordinator delegated to the web-search sub-agent, it passed only the paper's title - losing the user's specific research angle from earlier turns. The sub-agent then searched for generic citing papers instead of ones relevant to the angle the user actually cared about.
2. Incomplete retrieval
The web-search agent would issue a single, broad query, get moderately-useful results, and stop - never iterating or refining the search based on what it got back. A human researcher would re-search; the agent didn't.
Neither of these is a span-level error. Each individual LLM call and each tool call looked fine in isolation. They only become visible when you evaluate the whole session against the original user intent.
Where to Go Next
We now have quality signals at both the span and session level. But "is this good?" is only half of what you need in production. The other half is operational: how long does it take, how much does it cost, and is anything stuck?