Compare Versions
The Fix: Schema Engineering
We apply a simple fix to our code.
We do not change the code logic, prompt or the model.
We only add type hints and docstrings to the tool definitions.
# Version 2 (The Fix)
@tool("Hook Improver")
def hook_fix_tool(post: str, issue: str) -> str:
"""Improves the hook/opening of a blog post.
Args:
post: The full blog post text
issue: What's wrong with the hook (e.g., 'too clickbaity')
"""
...We apply the same logic to all of the editor's tools.
Creating the crew with the enhanced tool documentation.
Running eval dataset again through the new crew.
Logging the new version as "Enhanced - Claude 3.5 Sonnet".
The Results: First Impression
Opening the Overview of the Enhanced version, the improvement is noticeable.
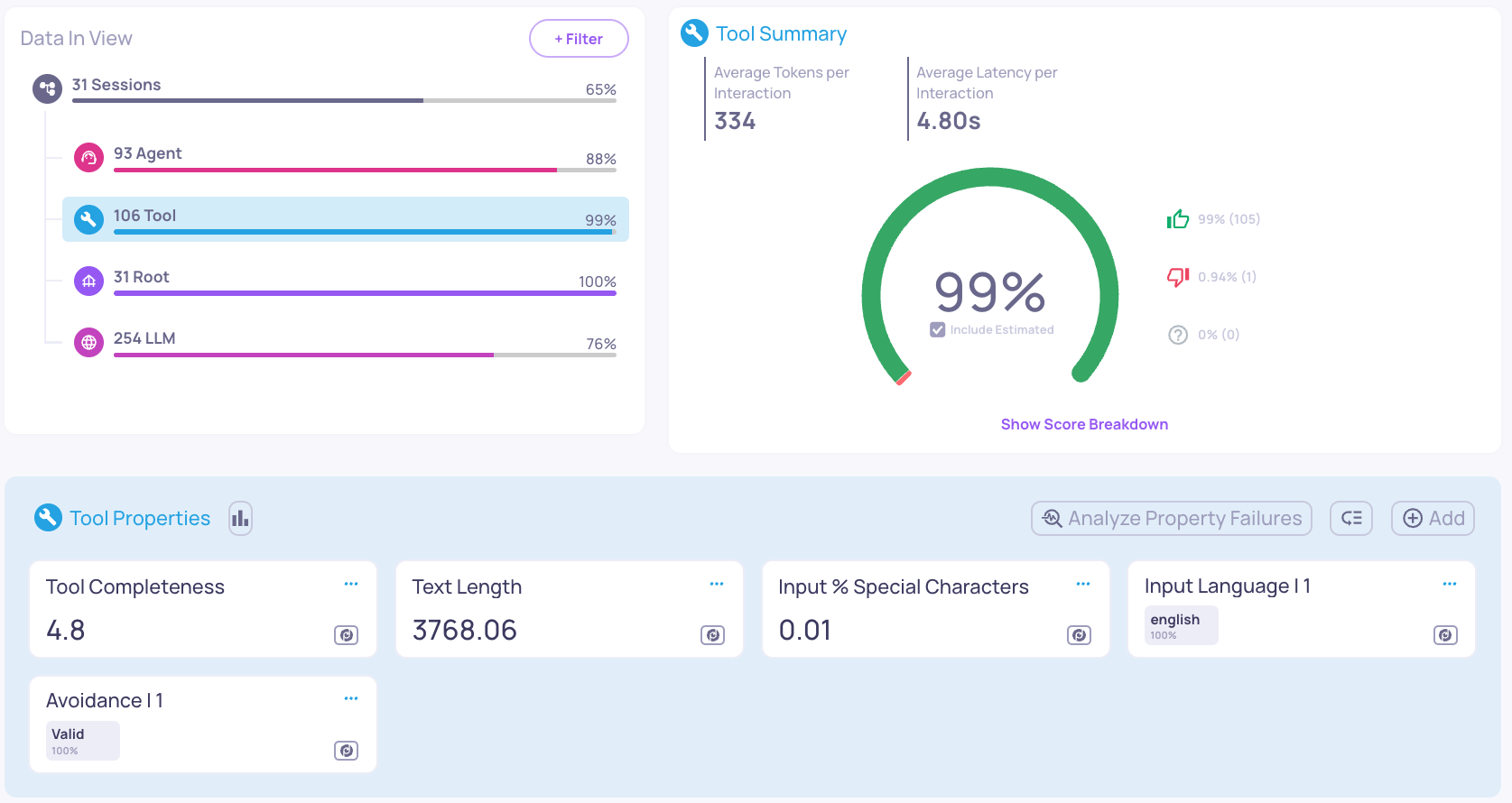
The overall Session score went from 45% to 65%
The "Tool" interaction type jumps from 23% to 99%!
Tool Completeness score jumps from an average score of 1.89 to 4.8.
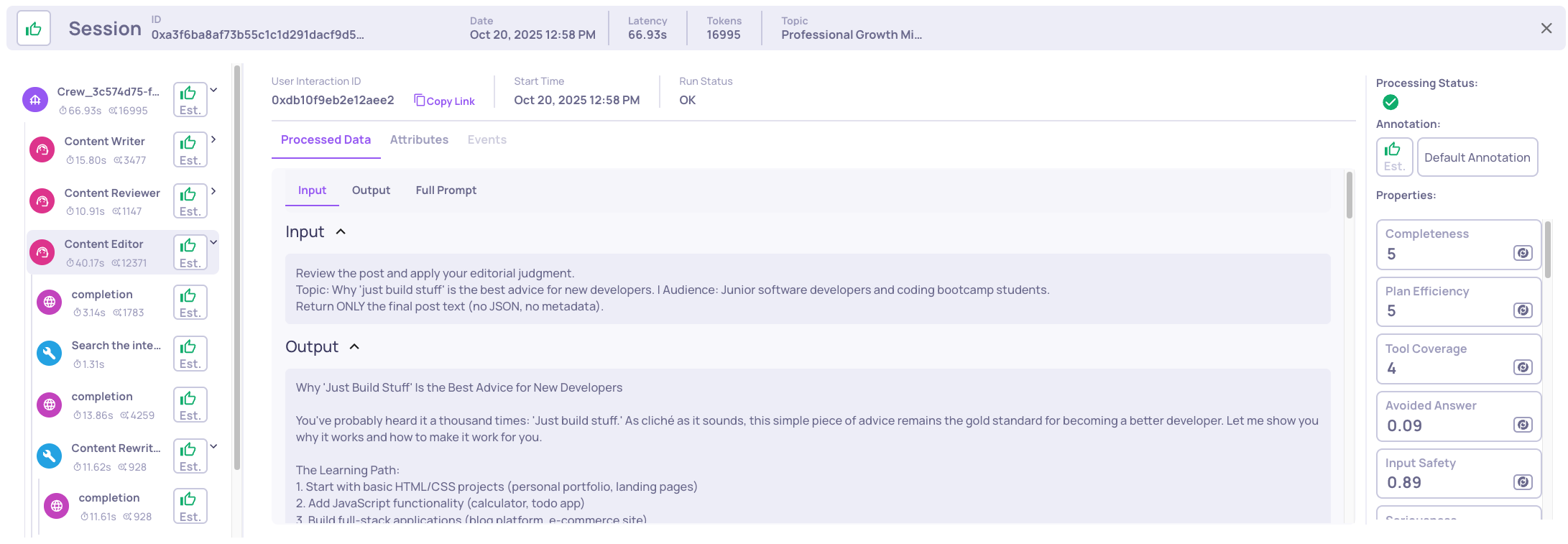
Running example result:
Opening the "just build stuff" example shows the Editor Agent's tool work perfectly as intended.
Testing Different Models
With the schema fix applied, we compare performance across different models.
We test a lighter model (Nova Micro) and a more advanced model (Claude 3.7 Sonnet) to understand the cost-performance trade-offs.
Agent Interaction Type
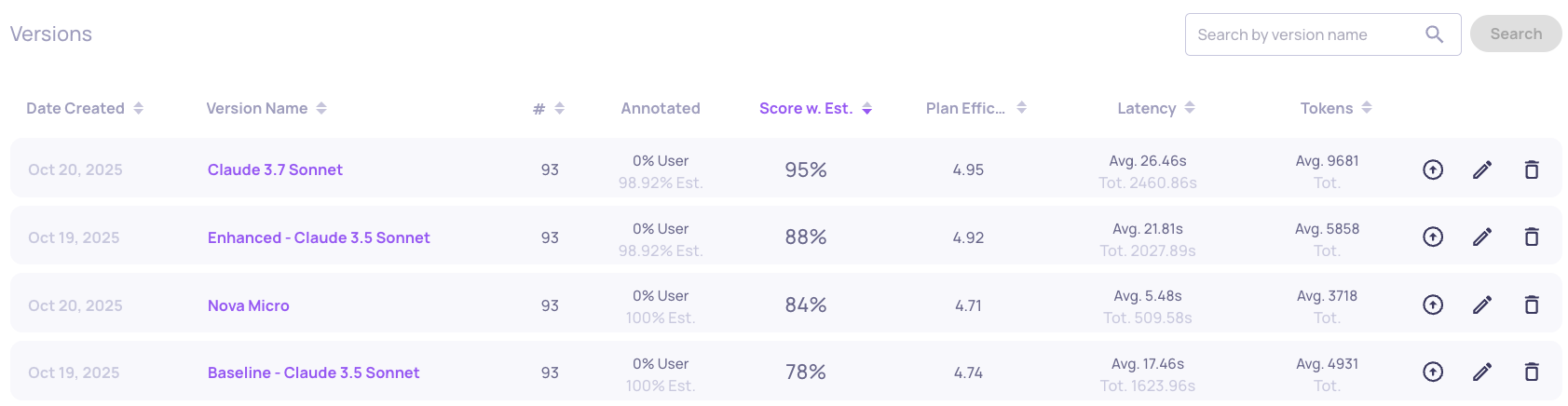
Claude 3.7 Sonnet comes out with the best result of 95%, but not without a cost.
The latency is 5x from the Nova Micro model, and the token usage is almost 3x from the Nova Micro model.
LLM Interaction Type
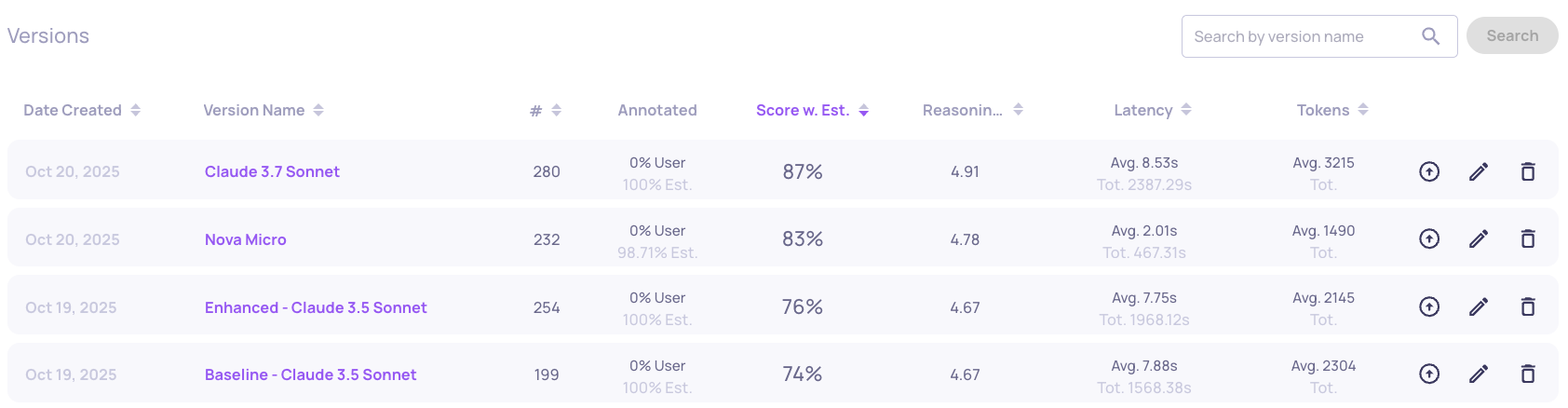
A similar pattern repeats in the LLM interaction type.
Cost-Performance Trade-Off
Claude 3.7 Sonnet achieves 95% but uses more resources.
- Uses 2x more tokens per session
- Adds approximately 10 seconds latency per blog post
For production, we must decide: Is the 7% improvement (88% → 95%) worth the cost and latency?
Key Takeaway
Reliability in agentic workflows often comes down to clear interfaces.
Deepchecks allowed us to pinpoint that the failure was in the process (tool calling with missing inputs), not the capability (model intelligence).
Version comparison reveals that schema fixes help all models, but advanced models leverage good schemas better.
Conclusion
This evaluation cycle demonstrates the power of systematic testing.
We identified a silent failure through trace visibility.
Schema engineering resolved the root cause.
Version comparison quantified the improvement across models.
Deepchecks transforms agent development from guesswork into engineering.
Updated 6 months ago