Uploading an Existing Evaluation Set via Drag & Drop UI
Deepchecks LLM Evaluation was built to have a "dual design" so that users can gain value from the system by using either the SDK or the UI. This means that many workflows that are possible using code are also enabled from the UI. One of the most important workflows is, of course, uploading data.
Uploading Data
Upon signing into the system, you will either be presented right away with the Upload Data screen, or with the Dashboard (if you have already uploaded interactions previously). In the second case, click the "Upload Data" button in the bottom left side to open the Upload Data screen.
In order to upload interactions, you need to first select or create the Application and Application Version. An Application represents a specific task your LLM pipeline is performing. For example in our case - answering HR-related question of Blendle employees. An Application Version is simply a specific version of that pipeline - for example, a certain prompt template fed to gpt-3.5-turbo.
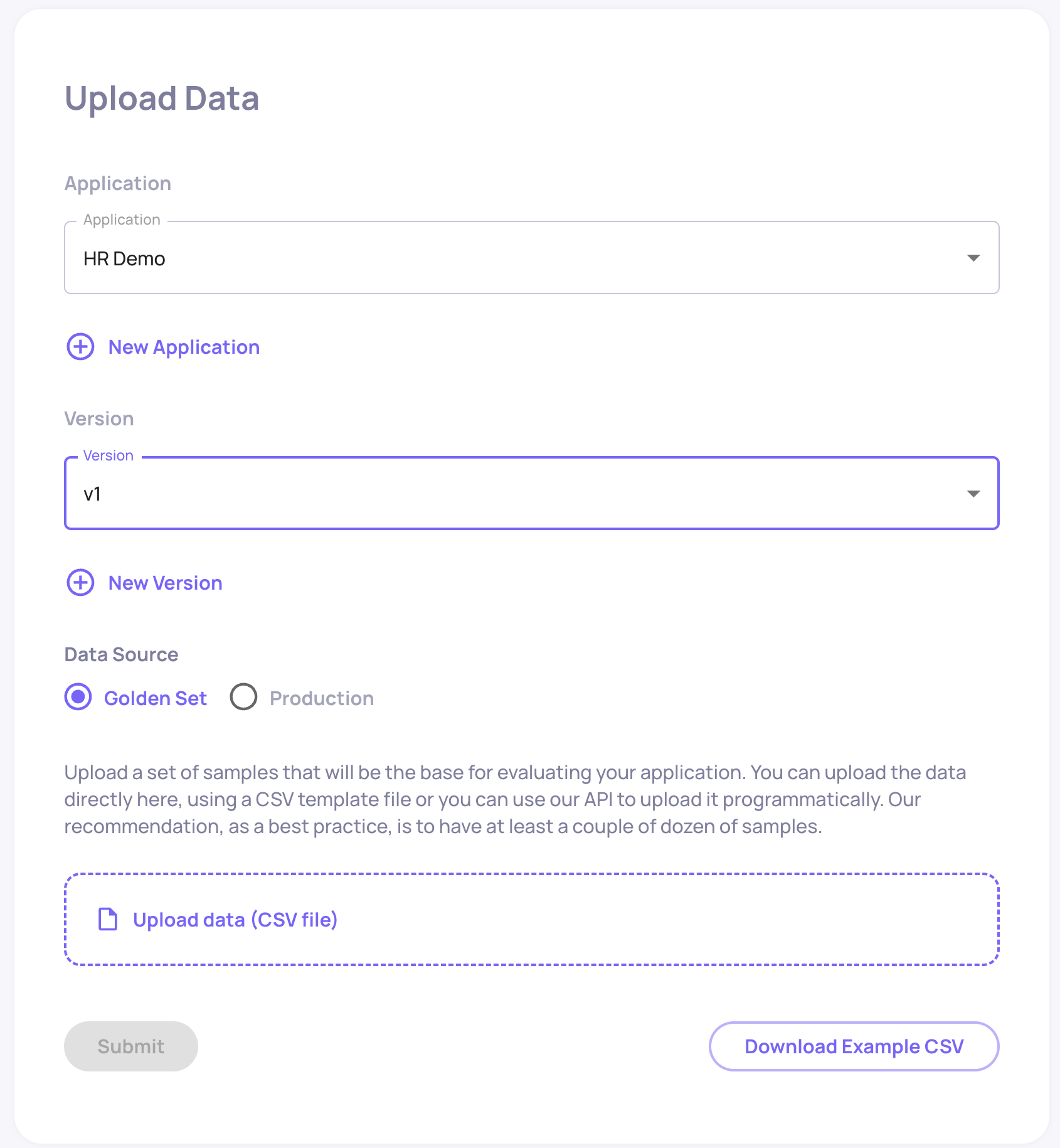
Names selected, you can now upload your data. The data you're uploading should be a csv file reflecting individual interactions with your LLM pipeline. The structure of this csv should be the following:
| user_interaction_id | input | information_retrieval | full_prompt | output | user_annotation |
|---|---|---|---|---|---|
| Must be unique within a single version. used for identifying interactions when updating annotations, and identifying the same interaction across different versions | (mandatory) The input to the LLM pipeline | Data retrieved as context for the LLM in this interaction | The full prompt to the LLM used in this interaction | (mandatory) The pipeline output returned to the user | Was the pipeline response good enough? (Good/Bad/Unknown/NaN = empty cell) |
You can download the example data for the Blendle HR Bot, GPT-3.5-prompt-1 version here. This dataset contains 97 interactions with the bot, alongside human annotations for some of the interactions.
Notes:
- Please note that the only columns that are mandatory are 'input' and 'output'. About the necessity of other columns:
- 'user_interaction_id' is highly recommended, but is generated by the system when not provided.
- 'information_retrieval' is needed for many of the properties and workflows in a RAG use case, but otherwise, it isn't necessary.
- 'full_prompt' is used primarily to assist users with visibility, manual tracing, and debugging within the system, but usually isn't used directly for any calculations.
- 'user_annotation' is typically sent when an annotation exists - can be 'Good', 'Bad', or 'Unknown'. For samples that don't have an annotation, the cell should be left empty (and they will be inferred by the system).
- There is also an option of adding other custom fields, but this is only supported via the SDK option.
- Once you upload the data, please allow a few minutes for all of the calculations to be completed (properties, topics, estimated annotations, etc.).
Updated 8 months ago