User-Value Properties and Prompt Properties
Using User-Value Properties
A powerful way to monitor the performance of your LLM-based application is to categorize it based on your chosen criteria. This approach helps identify which types of input questions your application excels at and which categories might be underperforming.
User-Value Properties in Deepchecks
User-value properties are user-defined. To display a User-Value Property in the Deepchecks system, users must upload interactions with the specified property value. Interactions lacking a value in the user-value property field will be automatically assigned an N/A value.
In our GVHD use case, we introduced a categorical property named “Question Type,” which classifies input questions into the following five categories:
- General GVHD Question
- Treatments & Medications
- Emergency / Urgent
- Appointments & Services
- Other
To filter by a specific category on the Interactions page:
-
Select the category within the property view on the Overview page and click the “See Interactions” button.
-
Alternatively, use the “Filter Categories” option in the property filters section on the Interactions page, and select the desired categories to be shown.
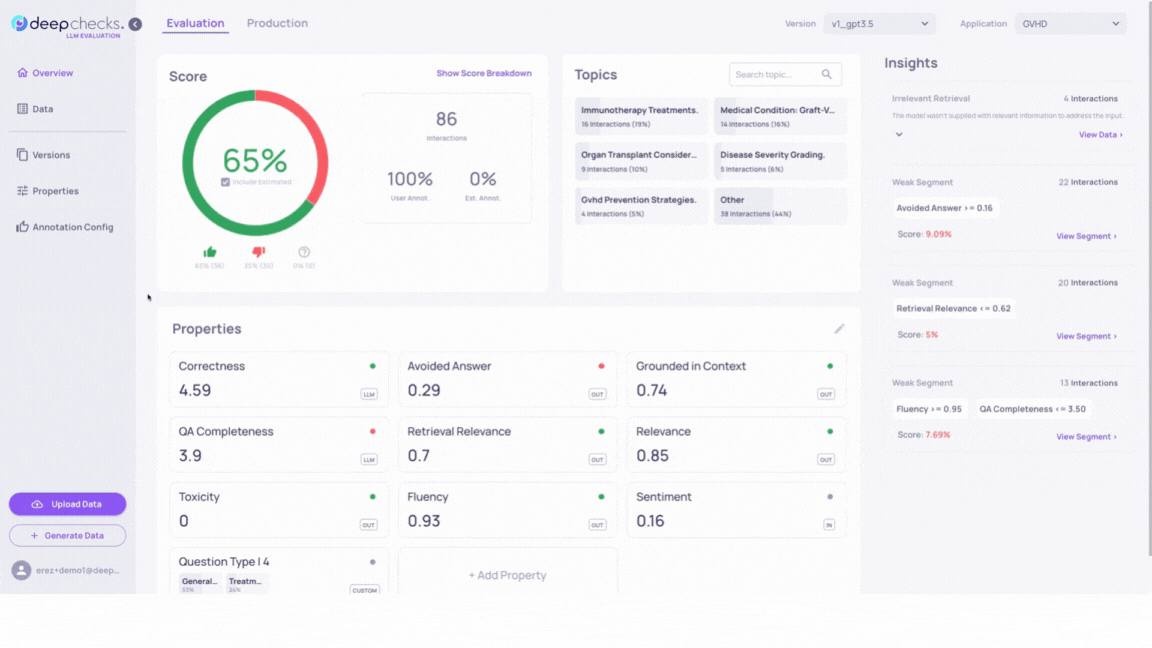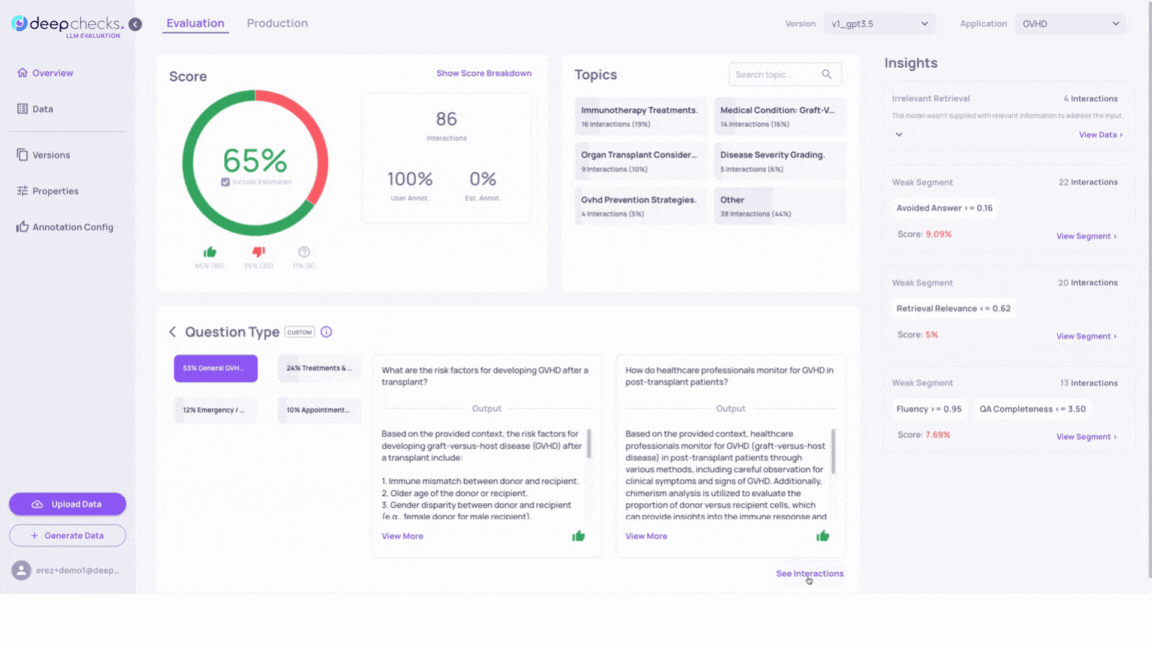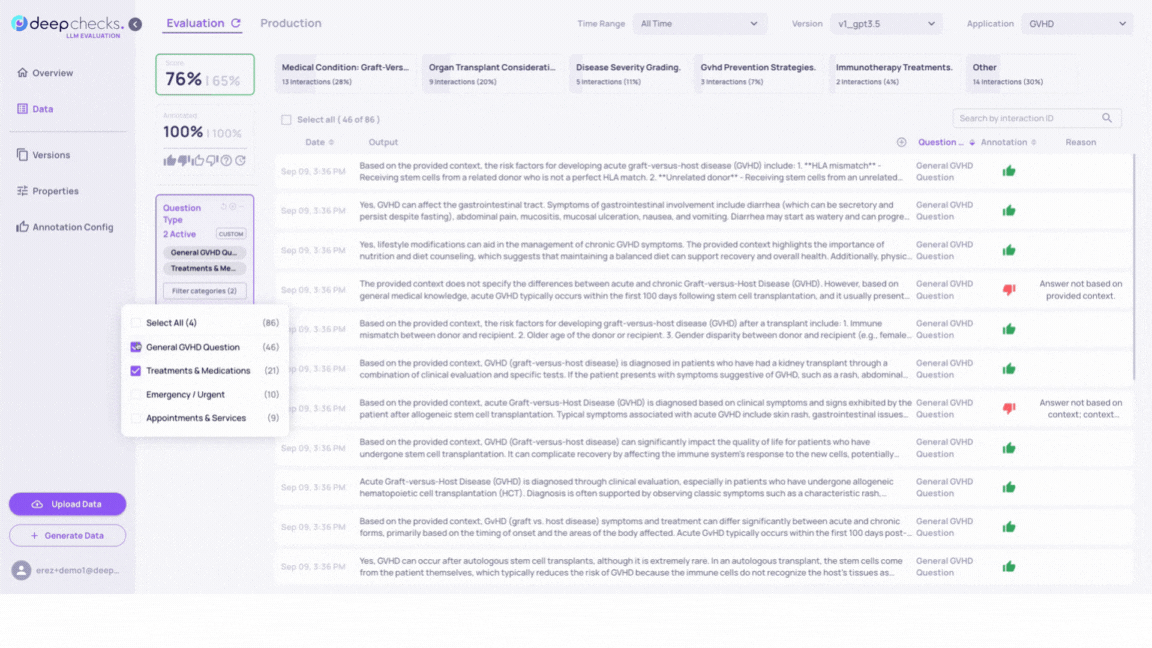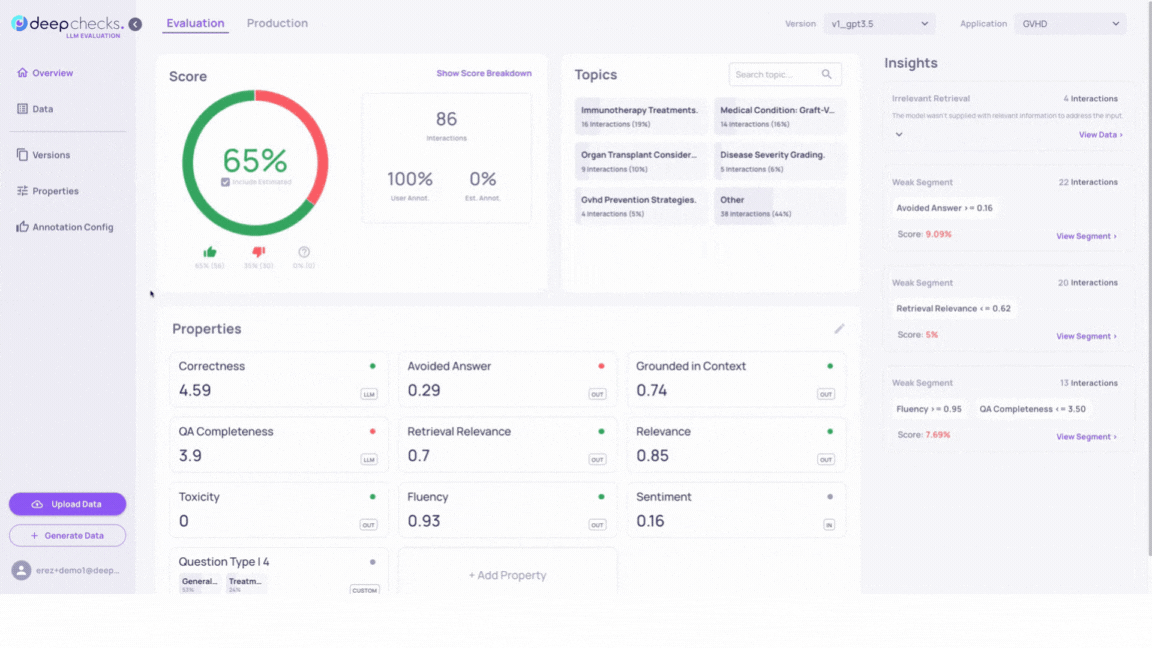
Results in version v2_improved_IR: Switching between versions with a categorical property filter on allows for effective comparison between versions. You’ll observe changes in relative annotation scores and property scores for these specific interaction subgroups. The larger information pool in version v2_improved_IR contributes to improved responses, particularly for questions in the “Emergency / Urgent” and “Appointments & Services” that version v1 struggled with.
Using Prompt Properties
Another valuable method for evaluating your version’s performance is by incorporating prompt properties in it. Refer to our prompt properties documentation page for more information.
For instance, In our GVHD use case, we observed a recurring output pattern where many answers begin with phrases like “Based on the provided context …”. Other interactions contain similar phrases that imply the output was generated by an LLM, using a given context to answer the input question.
This pattern may not be desirable in a Q&A type application.
To highlight this observation of ours, we can create a prompt property as follows:
New Prompt Property Content
Property Name: Based on context
Description: Highlight outputs mentioning it is "based on the context" it was provided with.
System Message:
- Read the entire output answer and analyze if it implies that it was based on a given context. If so, give it a high score. Otherwise, give it a low score.
- For example, outputs containing "Based on the provided context..", "Based solely on the context..", "The provided context.." or any similar phrase to these should get a high score.
Interaction Steps for Property: output
Recalculate Prompt Property
After saving the property's definition, recalculate it with the following definitions (by default prompt properties are calculated only for data that is uploaded after they're defined, so recalculation is needed to get their results for the data that is already in the system):
Versions: Select All (2)
Environment: Both
After a brief calculation period, the new property will appear on the Overview page. When sorting or filtering by this property, you’ll see that outputs implying they are using a given context in their answer indeed receive higher scores.
You can see another example of prompt property usage on the Monitor Production Interaction page.
Updated 3 months ago