Generating an Initial Evaluation Set (RAG Use Cases Only)
Given RAG use cases where an initial evaluation set doesn't exist, Deepchecks offers an option of utilizing the underlying documents to be used for retrieval to assist with generating evaluation set inputs. For this workflow, follow the following steps:
-
Click on the "Generate Data" button at the bottom of the left bar:

-
Follow the instructions in the pop-up window, including writing general guidelines for the input generation, a description of the LLM-based app being evaluated and either links or files with the underlying documents to be used by the RAG system:
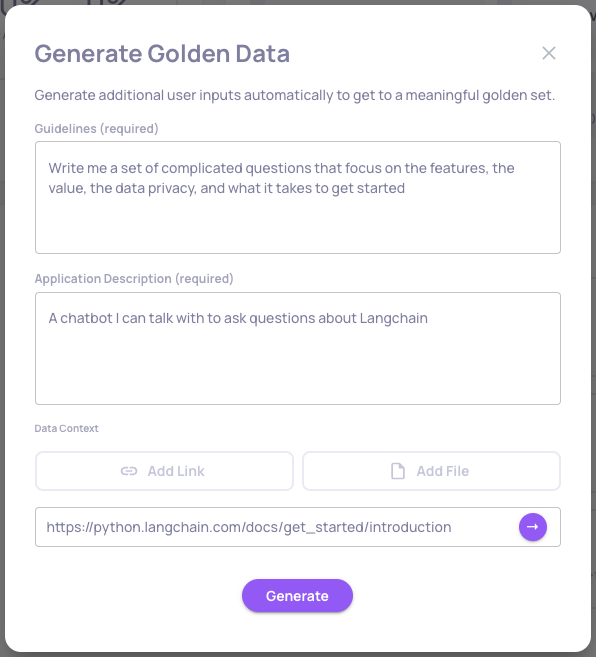
A pop-up window for generating an evaluation (=golden) set. In this example, we're simulating a "talk with my docs" example for Langchain's documentation.
-
Use the "Generate More" button to generate as many samples as needed, and omit the samples you don't desire by scrolling down and clicking on the "x" on the right-hand side of each undesired input.
-
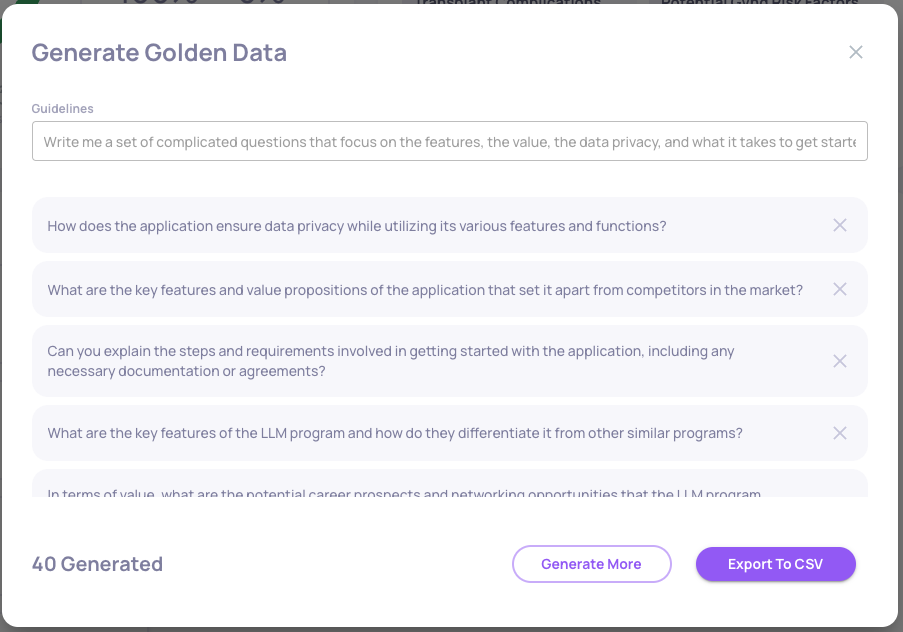
Click on "Export to CSV" to download the generated inputs.
-
Run these generated inputs within your RAG pipeline to gather the corresponding next phases that should be sent to Deepchecks (including "information_retrieval", "output", etc). Example code for this:
import openai import pandas as pd # Load the evaluation set df = pd.read_csv("evaluation_set_inputs.csv") # Initialize the OpenAI API openai.api_key = "your_openai_api_key" # Dummy function to simulate context retrieval from an external source def retrieve_context(question): # Replace this with actual context retrieval logic return "This is a simulated context based on the question." # Function to simulate the RAG pipeline using OpenAI's GPT-3 def rag_pipeline(user_interaction_id, input_question): context = retrieve_context(input_question) full_prompt = f"Context: {context}\nQuestion: {input_question}\nAnswer:" response = openai.Completion.create( engine="text-davinci-003", prompt=full_prompt, max_tokens=150, temperature=0.7, top_p=1.0, n=1, stop=["\n"] ) return { 'user_interaction_id': user_interaction_id, 'input': input_question, 'information_retrieval': context, 'full_prompt': full_prompt, 'output': response.choices[0].text.strip() } # Loop through the inputs and generate responses outputs = [rag_pipeline(row['user_interaction_id'], row['input']) for _, row in df.iterrows()] # Convert the outputs to a DataFrame and save as a CSV output_df = pd.DataFrame(outputs) output_df.to_csv("generated_outputs.csv", index=False) -
Now send "output_df" back to Deepchecks, either using the "Upload Data" option via the UI, or by sending it via SDK, as in the example below:
from deepchecks_llm_client.client import DeepchecksLLMClient
from deepchecks_llm_client.data_types import EnvType, LogInteraction
# Initialize the Deepchecks LLM Evaluation client
dc_client = DeepchecksLLMClient(
api_token="Fill API Key Here"
)
# Prepare the interactions for logging
interactions = []
for _, row in output_df.iterrows():
interaction = LogInteraction(
input=row['input'],
output=row['output'],
information_retrieval=row['information_retrieval'],
full_prompt=row['full_prompt']
)
interactions.append(interaction)
# Log the interactions to the system
dc_client.log_batch_interactions(
app_name="Langchain_Docs_QnA",
version_name="GPT3.5_PromptV1",
env_type=EnvType.EVAL,
interactions=interactions
)Updated 8 months ago