Cloning Interactions from Production into the Evaluation Set
In the process of evaluating LLMs with Deepchecks, it is important to ensure that the evaluation set represents the actual interactions we are expecting or receiving in production. Part of what's needed in order to do so is to add samples to the evaluation set either from a reliable external source or, as we will describe below, from the production data.
Cloning Interactions from Production to Evaluation for One Version
To copy interactions from production to the evaluation set, follow the steps below:
- Open the data screen:
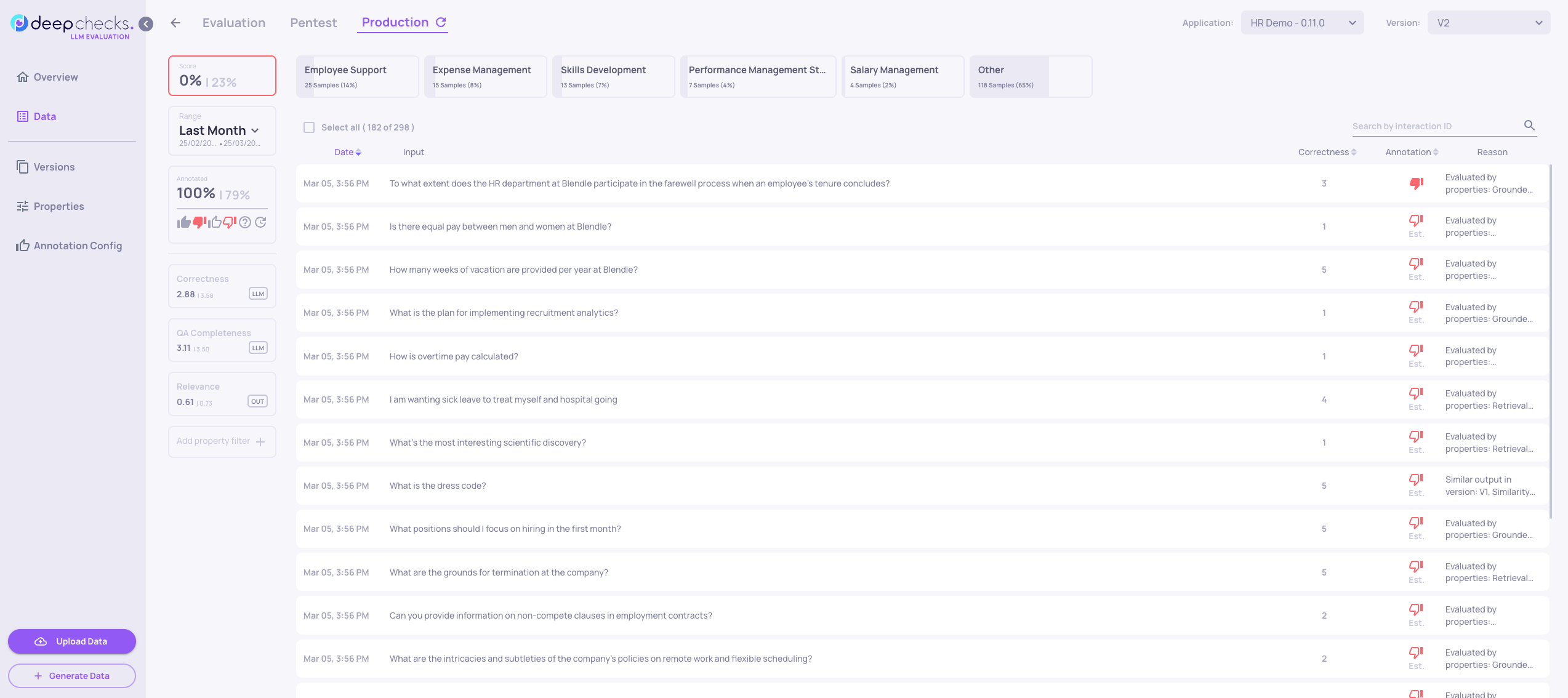
- Click on the "Production" tab near the top of the screen, and perform sorting or filtering to enable an easy selection of the interactions that should be added to the evaluation set. In this example, we've filtered to see only the interactions from the last month and only interactions that got "thumbs down" or "estimated thumbs down":
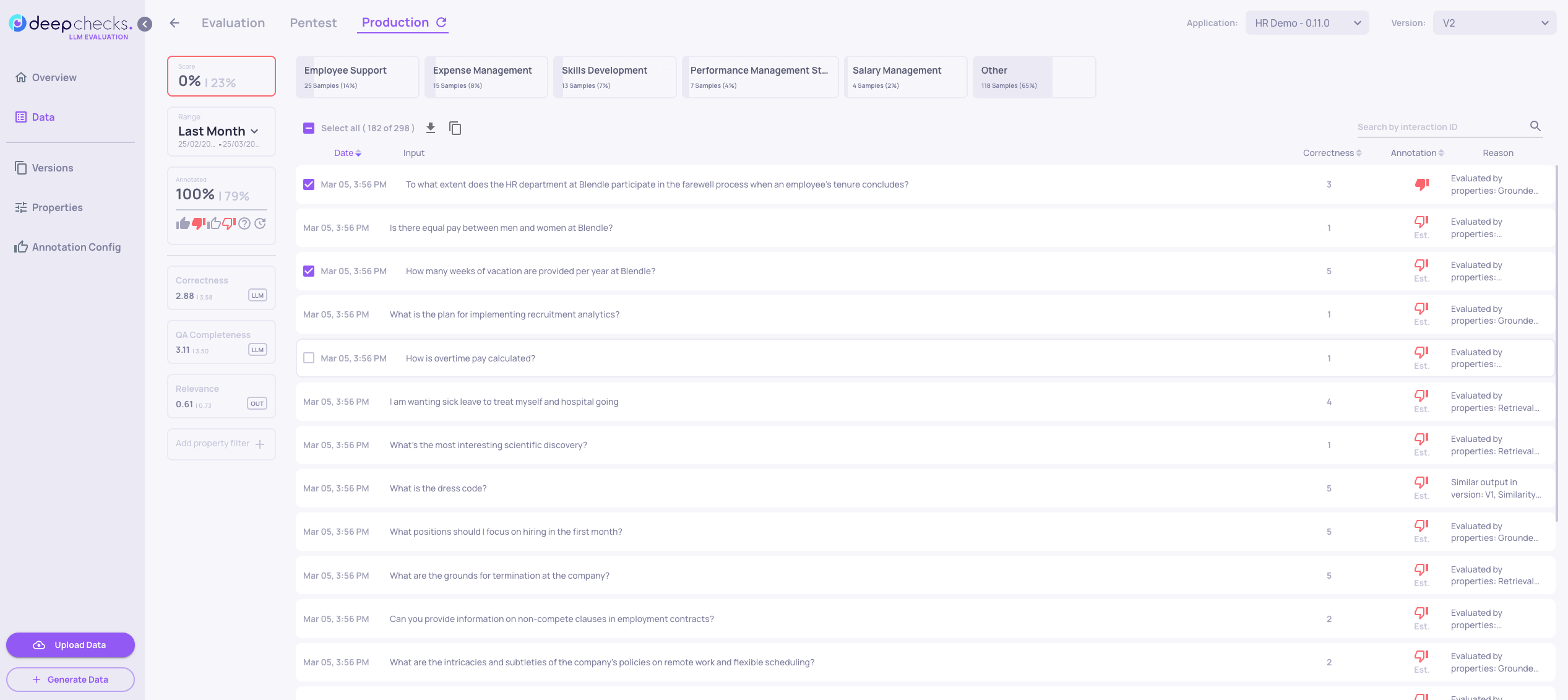
- Select the interactions to be added to the evaluation set, and note that a new clickable "Copy" icon appears on top, next to the "Select All" checkbox:
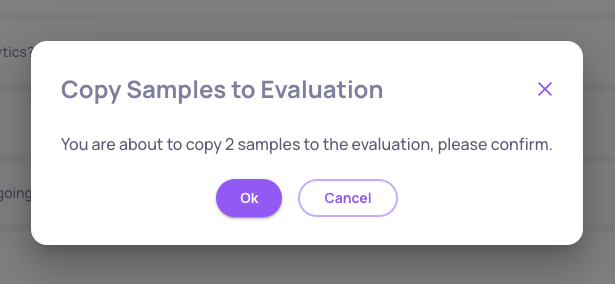
-
Click on the "Copy" icon that appeared on top, and then click "OK" within the pop-up window that appeared:
Cloning Interactions from Production to Evaluation for Multiple Versions
The guide above will only copy the interactions to the evaluation set of the version currently being edited. To copy interactions from production to multiple evaluation sets in parallel, follow these steps:
- Follow steps 1-3 from the section above, and then download the interactions using the icon to the left of the "Copy" icon (instead of copying). Read the interactions you've downloaded within your Python code:
import pandas as pd
interactions = pd.read_csv('baseline-PROD.csv')- Now note that the input is going to be uploaded to all versions, but for the rest of the versions, you will need to run your own pipeline to get the output, the information retrieval if relevant, and so forth. Let's assume this is a list of the versions you'd like to add the interactions to:
version_list = ['baseline', 'v2-IR']- Now run your pipeline on the versions of your app, for all versions in version_list except the version from which you downloaded the interactions, for you already have the results for. It will look something like this:
interactions_df_dict = {}
# Mandatory columns
mandatory_columns = ['user_interaction_id', 'input', 'output']
# Optional columns
optional_columns = ['information_retrieval', 'annotation', 'full_prompt']
# Custom properties
custom_properties_columns = ['My Custom Property']
for version in version_list:
'''
YOUR CUSTOM CODE HERE THAT RUNS YOUR LLM PIPELINE FOR EACH VERSION
This should create a Pandas dataframe containing the colomns in the 'columns' list created above.
We'll assume the datafram is named interactions_df
'''
interactions_df_dict[version] = interactions_df- Set up the Deepchecks Python client:
from deepchecks_llm_client.client import DeepchecksLLMClient
from deepchecks_llm_client.data_types import EnvType, LogInteraction
# Initialize the Deepchecks LLM Evaluation client
dc_client = DeepchecksLLMClient(
api_token="Your Deepchecks API Token Here (get it from within the app)"
)- Loop on the versions, and upload the interactions to each of them:
for version, interactions_df in interactions_df_dict.items():
interactions = []
for index, row in interactions_df.iterrows():
# Prepare arguments for LogInteraction object, only include optional columns if they exist
interaction_args = {
'user_interaction_id': row['user_interaction_id'],
'input': row['input'],
'output': row['output'],
'custom_props': {key: row[key] for key in custom_properties_columns if key in row and not pd.isnull(row[key])}
}
# Add optional arguments if the column is present and the value is not NaN
for column in optional_columns:
if column in row and not pd.isnull(row[column]):
interaction_args[column] = row[column]
# Create a LogInteraction object from the prepared arguments
interaction = LogInteraction(**interaction_args)
interactions.append(interaction)
# Log interactions
dc_client.log_batch_interactions(
app_name="GVHD-demo",
version_name="baseline",
env_type=EnvType.EVAL,
interactions=interactions
)Please note that this only works in cases where the 'user_interaction_id' doesn't exist yet in the evaluation set. If some of them may already exist in the evaluation set, it's recommended per evaluation version to fetch the evaluation data as a DataFrame via SDK (using the 'get_data' function, see here), and then add a check making sure each id is non-existent in the 'user_interaction_id' column.
Updated 8 months ago