Main Features
The solution supports the full lifecycle of an LLM-powered application: experimentation, testing, staging and production
Evaluating your Application
Evaluating LLM-based applications is a new challenge: unlike classical AI, there is a lot more subjectivity in evaluating the result of text generation as very different responses can all be correct and in many cases evaluation requires domain expertise. The need to have a high quality bar is at least as important as traditional applications and even more so as LLM-based applications are expected to be "intelligent".
Manual annotations is not a scalable solution as a single interaction may take 3-5 minutes to review. Given that we may want to evaluate hundreds of interactions, that means it will take days of testing to perform standard software regression testing for every release. Today's businesses expect immediate response to user's feedback, so taking days of manual testing is not an option.
We have taken the task of creating an objective scoring system at scale to enable LLM-based application developers achieve an agile release cycle, which doesn't have a bottleneck of manual annotations. Deepchecks estimates the annotation using a combination of open-source, proprietary and LLM models with a customizable auto annotation system. Testing will take minutes instead of long days.
Lifecycle stages
The top menu of the application has two tabs: Evaluation and Production. The Evaluation is the place to manage experiments and pre-production/staging versions. The production tab will take you to your production data, where you can track the performance of your application, understanding quality, latency and cost.
A version might have just evaluation data, in cases where it is an experiment, or a testing version. A deployed version should usually have both production and evaluation data, where the evaluation data represents the result of the test that was done before updating the production version.
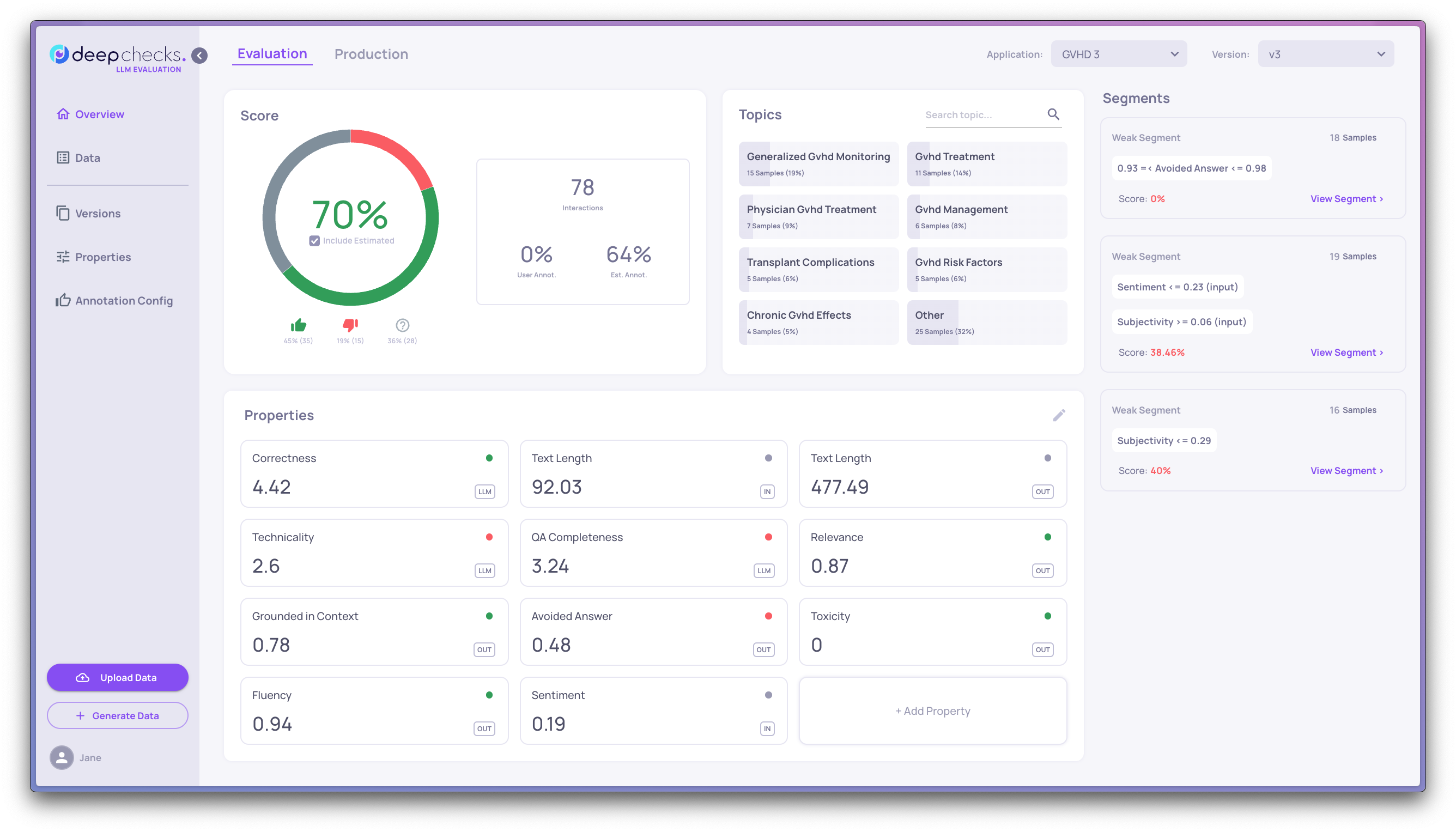
Creating a Dataset for Evaluation
The evaluation dataset, a curated collection of interactions, establishes your applications's quality criteria, ensuring consistent evaluation between experiments and application versions. The Evaluation interactions should represent the typical data distribution that your application will experience once launched to production. This will give you a way to get a trustworthy score, which will be used to compare experiments and check that you meet your release criteria before you deploy an application version to your testing, staging or production environment.
One needs to have two things in place in order to have a proper evaluation dataset: Interactions that represent your real world data and an annotation for these interactions.
Creating the dataset
The application offers two methods for creating an Evaluation dataset: Importing the interactions, which is relevant if you already have a table with input (questions) and outputs (answers) creating by your LLM-powered application. Refer to Uploading Data to see how this is done.
If you don't have an initial Evaluation Dataset, the application will help you with creating that initial set, by using your application description, the guidelines and a set of documents as a reference. This will produce a set of inputs/questions that you will need to run through your LLM-powered application and then import as a standard samples set. Refer to Generating Interactions for more details
Annotate your interactions
The recommended practice is to have a baseline that is annotated by a content expert. This can be done in two ways, by initially providing these annotations in the samples file or by letting the system the suggest an estimated annotation and have a human review of these samples.
You edit the annotations in the samples screen. A manual annotation is denoted by an opaque thumbs up/down sign, which you can change when clicking on the relevant sign. An estimated annotation will have only the outlines of the sign.
A great way to annotate you samples is by letting the system recommend annotations to you and review those estimated annotations. You can read more about estimated annotations here: Estimated Annotations
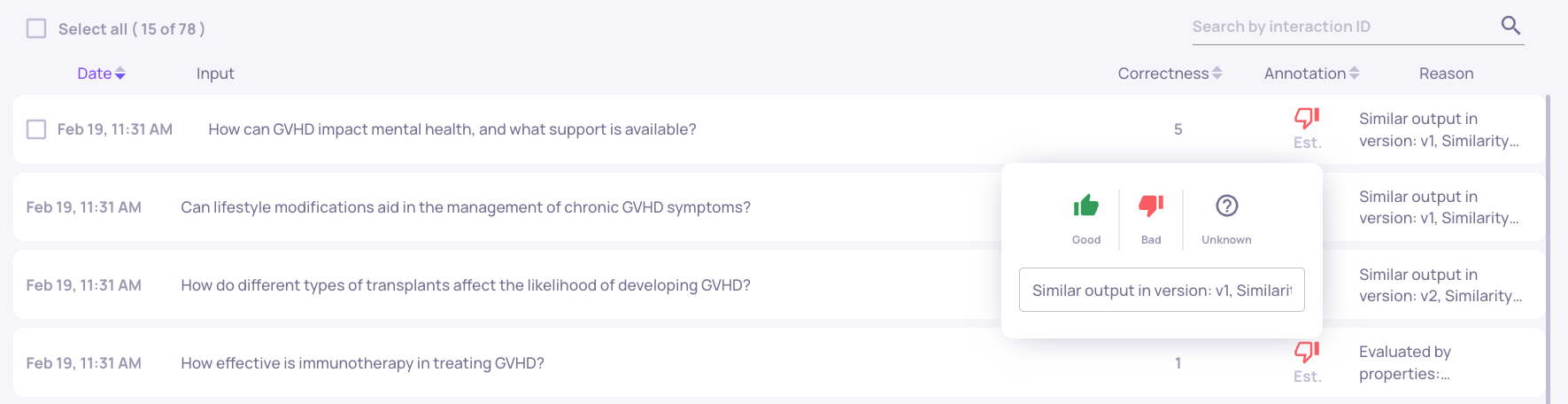
Production Data
Once you have an evaluation dataset in place you can add production interactions. Most likely one would like to use our SDK to add these samples either in real time or in a batch mode. According to your license, either a subset or the full set of production samples will have an estimated annotation and according a quality score. This allows you to monitor the performance of your application in production. Read about the SDK here: SDK Quickstart
Application Evaluation
Note: the next sections are applicable to all application lifecycle: experimentation, testing, staging and production.
Evaluating Application Data
Deepchecks provides three levels of data evaluation:
-
Version: The dashboard allows you to see the overall score and key quality properties for a single application version
-
Data: You can filter your data to look into a specific segments and using the data screen
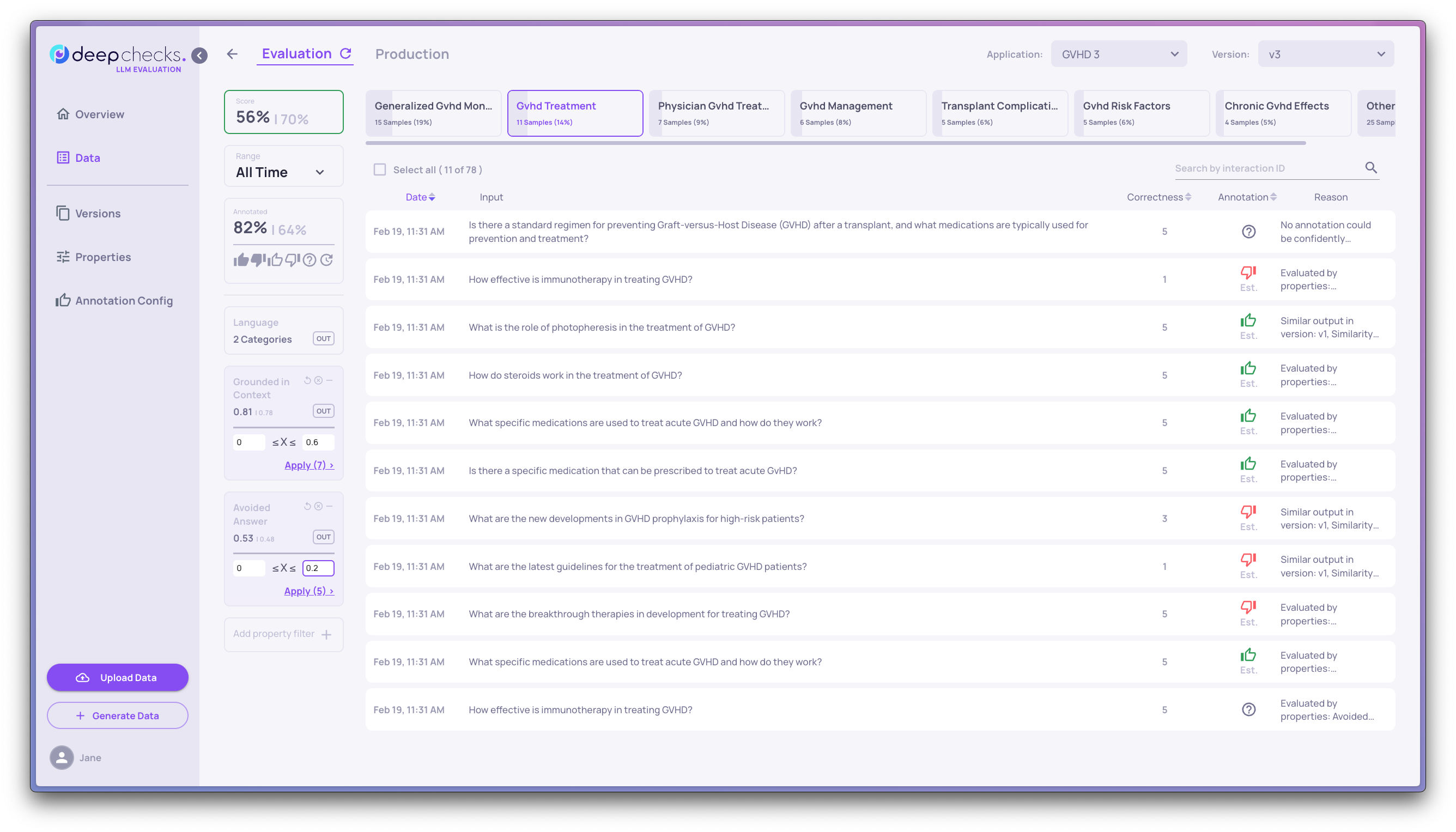
-
Individual interactions: When reviewing an annotation or when you want to perform root-case analysis, you need like to see all the detailed steps that produced the final answer. Just click on the interaction to open this view.
Overall Version Analysis
The dashboard is the key tool to analyze the high level characteristics of an application version. In the dashboard you have four key areas which covers a wide range of information about your application status and your users interests.
Key Quality Metrics
The score is the single most important aspect of this application, it combines all the quality knowledge into a single, reliable score that can be used to determine whether to release an application to production or that a production application has a significant quality issue.
Properties
The properties provide a rich set of metrics about your applications in the areas of: quality (e.g. relevance), safety (e.g. toxicity), hallucinations and technical (e.g. Sentences Count). They help with painting a high level picture of your application quality, for example knowing when your average input toxicity is high. In addition they can be used for Filtering Interactions
Topics
Your users input topics are interesting to understand "what's on your users mind?" and figure our whether there are topics where your results are less than optimal.
Segments
Deepchecks automatically identifies your weakest segments, it uses properties, both out of the box and custom properties. That allows you to quickly understand where your application underperforms

Deep-dive into a Version
When there is a question about a specific version, such as "Why do we see wrong answers for Employee Relations - related questions", Deepchecks helps you with getting to the reason of the issue with filtering your data and seeing the details for each individual sample.
Filtering Interactions
In order to understand why do we miss on some segments we will start with a topic, a weak segment or outstanding values in a property that might hint to a problematic segment. We will then apply additional filters to focus on problematic samples.
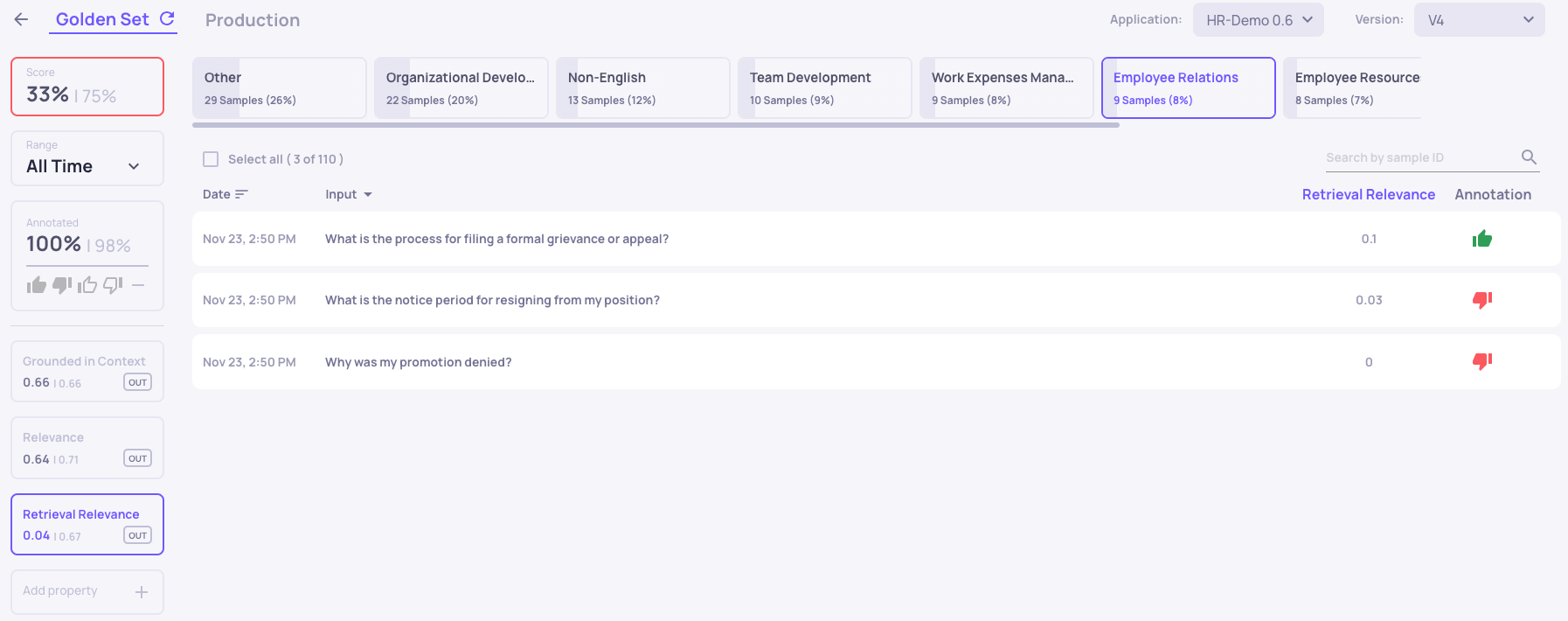
"Employee Relations" and low Retrieval Relevance
Analyze an individual interaction
Once you have a well defined segment with "bad" interactions, you can track what happened at each step of the interaction's lifecycle, in a RAG use-case it would mean that you can view the Information Retrieval results, the full prompt and all the parameters (such as temperature) used when calling the LLM
Updating your Evaluation Data
After one launched a new version to production or once users behavior changed, there might be segments in your production data that don't have proper representation in your evaluation dataset. In many cases, this might cause your application to have a higher failure rate in these segments.
Detecting the Change
When you see that there is a large decrease in your production score, there are several places where you should look for low scores: the best is the "Segments" section which leads you to the lowest scoring segments. Otherwise, you can use the samples screen to filter for "bad" samples.
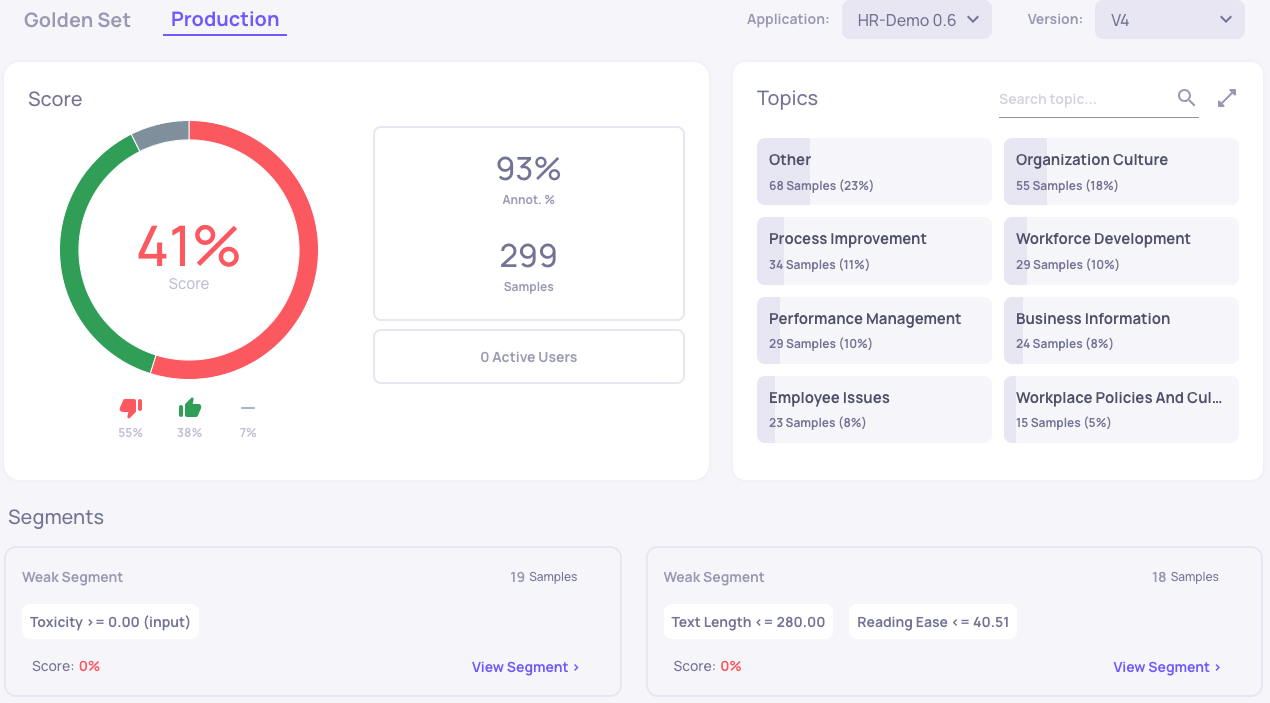
Copy Production Samples
Once you have identified a segment with low scored samples, you can copy them to your Evaluation dataset. This will ensure that your next rounds of testing will show a more realistic score. You can also download these examples into a CSV, for further analysis.
Generate New Samples
In cases where you know about an up and coming change to your application, that involves using a new segment of data (such as, you just added a new documentation section on "Employee Relations"), you can generate more samples, run them through your application and add them to your Evaluation data. You can read more about it here: Samples Generation
Version Comparison
Comparing between two versions of the application can be very useful for experimentation, regression testing and identifying the root cause of a version that did not pass the quality bar.
Comparing Scores
The high level comparison of your two versions should start with comparing the score, a significant difference should be further evaluated
Comparing Properties
The next level is to look into specific properties and see if you see a significant difference there. That would hint about the reason for the difference between the versions. Once you have identified such a difference, you can drill down into one of the versions using the methods described in:Evaluating Application Data
Version Comparison
You can compare two versions by opening two browser tabs and selecting a different version for each tab
Updated 4 months ago