Advanced Features
These features are an important component of the solution and should be used after an initial experience with Deepchecks.
Auto Annotation Customization
Estimated annotation accuracy is critical for proper quality scoring: the high level dashboard score is the % of "Good" scored samples in the relevant data set. The out-of-the-box scoring can be further improved by tuning how the score is calculated. The customization is done via editing a YAML file. You can download the current file and upload the updated one in the "Auto Annotation" option under "Configuration". The key elements that can be customized are:
- Which properties are used: you can add or remove properties and custom properties
- Refine the properties thresholds (those are used to define samples as "bad")
- Change the similarity algorithm threshold and it's location in the pipeline. Similarly looks for a similar output on an identical input, in all the previous versions of the application, both on Evaluation and Production environments. If it finds one, the annotation of the previous sample is copied to the evaluated sample.
- Modify the prompt that is used to as the LLM to evaluate a sample that has not been determined to be "bad" or does not
Once you have uploaded a new version of your YAML file, it would be best to upload a new version of your evaluation dataset and review the updated estimated annotation results.
Custom Properties
Custom properties is the main road to get additional data, which can help with better scoring and significantly improve the ability to slice and dice your data. Custom properties can be numeric (e.g. end-user answer score) or categorical (e.g. user meta data, such as Age). The two key types of data which are used here would be:
- User/Application meta-data, which can be about the user: demographics, user tier, user organization, etc
- Your custom quality metrics, that you have developed independently and would like to use as part of the scoring mechanism here: Auto Annotation Customization
Custom properties can be uploaded either via CSV or via the SDK
Generating Interactions
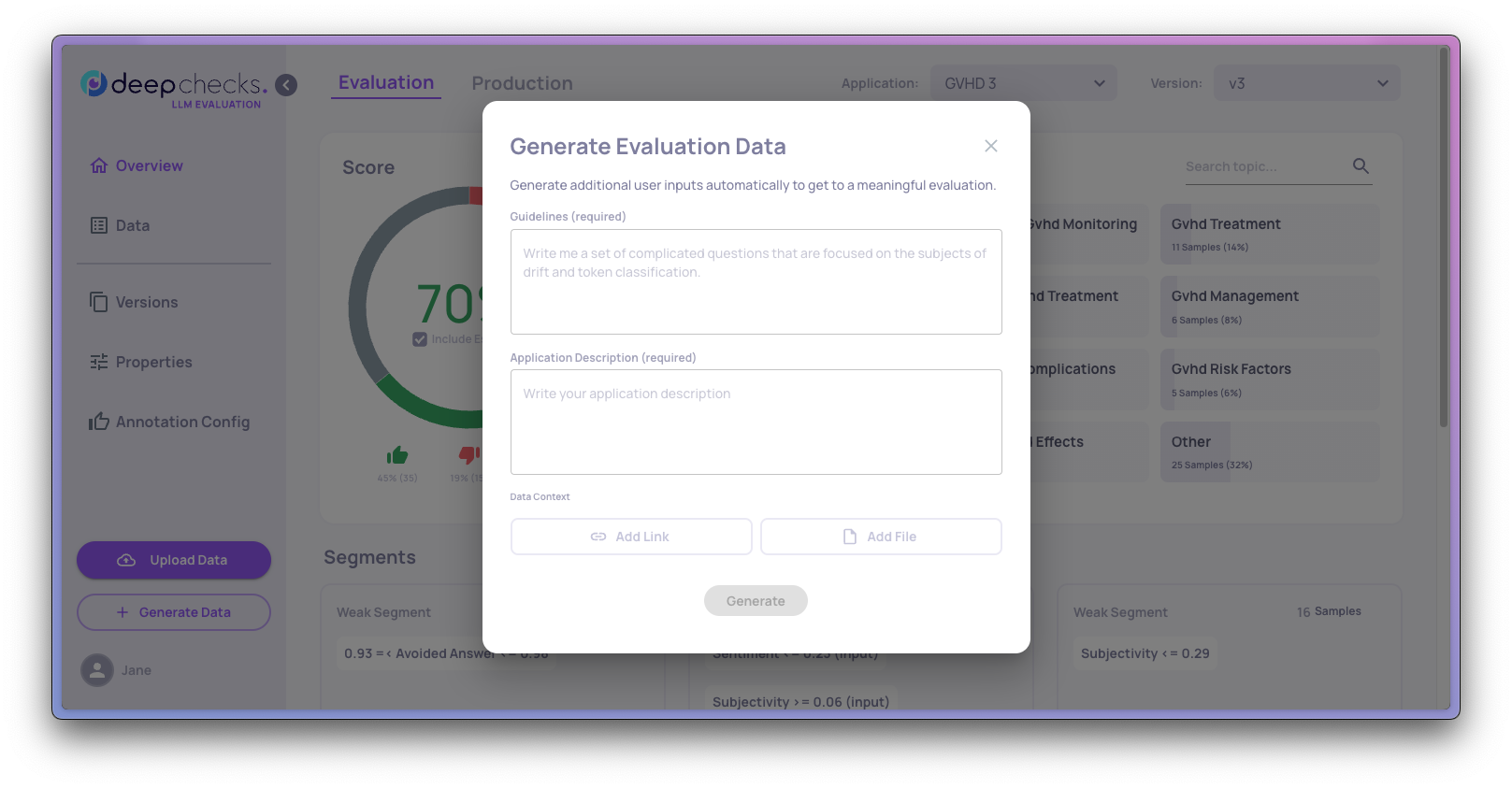
There are two cases where additional samples are needed: you start an Evaluation Dataset from scratch or you see a need to add additional type of questions in order to increase the coverage of the Evaluation data, relatively to the "real world". The process includes adding guidelines (a set of questions focused on relevant subjects) and an application description. As an optional step, data context can be enhanced by including a relevant link or file.
Updated 18 days ago