Version Comparison
Use Deepchecks to compare versions of an LLM-based-app. The versions may differ in the prompts, models, routing mechanism or any
A common need in the lifecycle of LLM-based applications is to compare multiple versions across key factors, such as performance, cost, and safety, to choose the best option. This typically comes up during iterative development of a new app, or when an existing production system needs improvement due to poor performance, changing data, or shifts in user behavior.
Comparisons can be simple—between two or three versions, such as the current production version and a few new candidates—or more complex, involving dozens of alternatives. The latter is common when experimenting with different prompts or testing multiple base models to find the best trade-off between cost and performance.
Comparing Versions Via Identicaluser_interaction_ids
- To fairly compare different versions, you'd want to run them on similar input data and compare their properties and annotations. We recommend building an evolving evaluation dataset, enabling comparing 🍏 to 🍏 via the user_interaction_id field. For more info, see Evaluation Dataset Management
Deepchecks allows you to compare versions both at a high level and with fine-grained detail.
Deepchecks' High-Level Comparison
Deciding on the desired version by comparing the high-level metrics, such as overall score and selected property scores. Possibly taking into account additional considerations (such as latency, cost, etc. for each option). This is enabled thanks to the built-in, user-value, and prompt properties, along with the auto-annotation pipeline for calculating the overall scores.
All of this is available on Deepchecks' Versions page. A practical starting point is to sort the versions by "Score w. Est"—which reflects the average auto annotation score—and then examine the key property averages of the top candidates.
For example, one version might consistently produce responses with decent completeness and coherence—enough for a "good" annotation—while another version generates highly complete and coherent responses but ends up with a slightly lower overall score. Deepchecks makes it easy to spot and interpret these subtle differences.
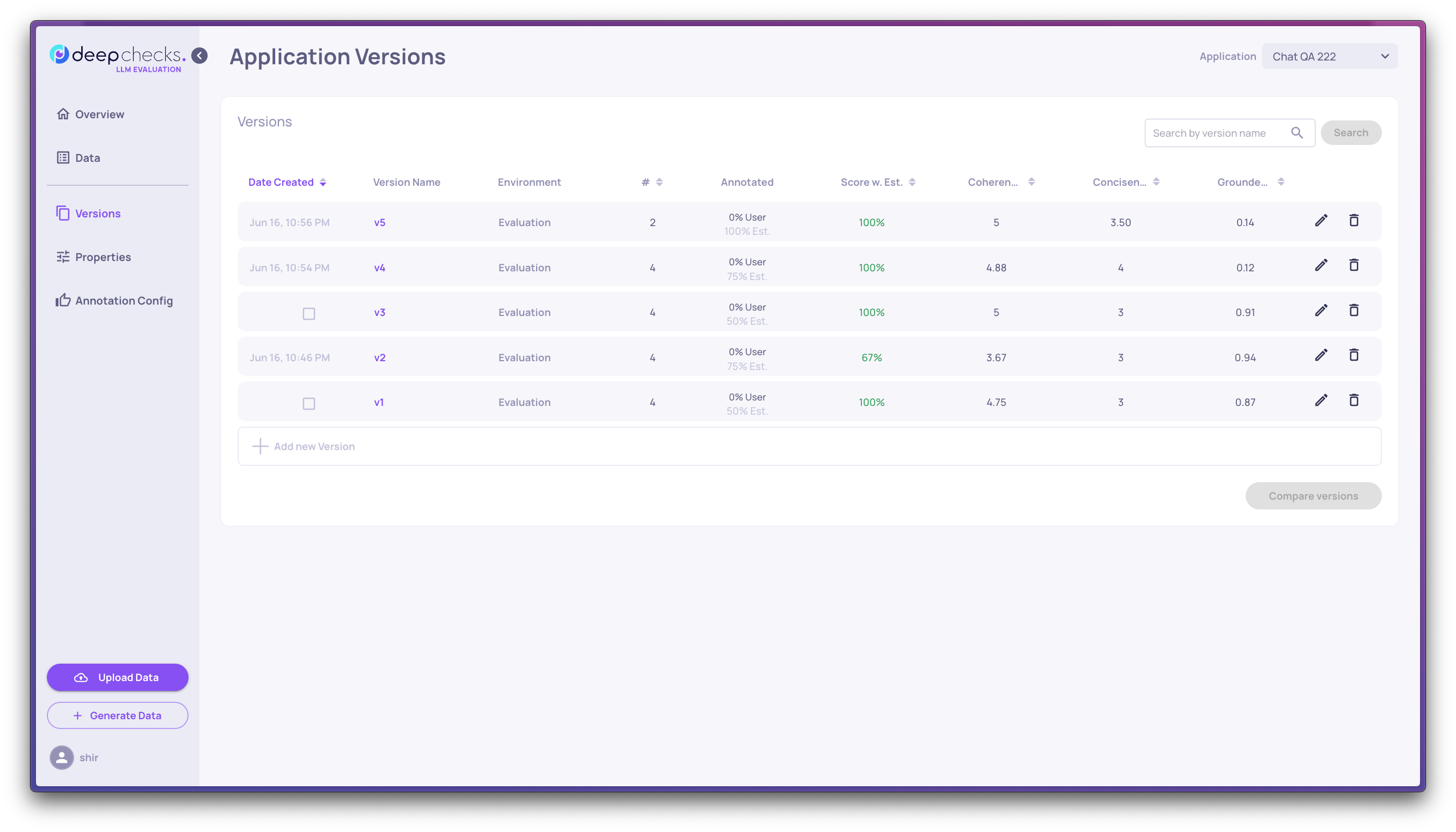
Deepchecks' Granular Comparison
Selecting two versions allows you to drill down to the specific differences between them. It can highlight specific interactions from the evaluation set whose outputs in the different versions are most dissimilar or interactions that received different annotations between the versions.
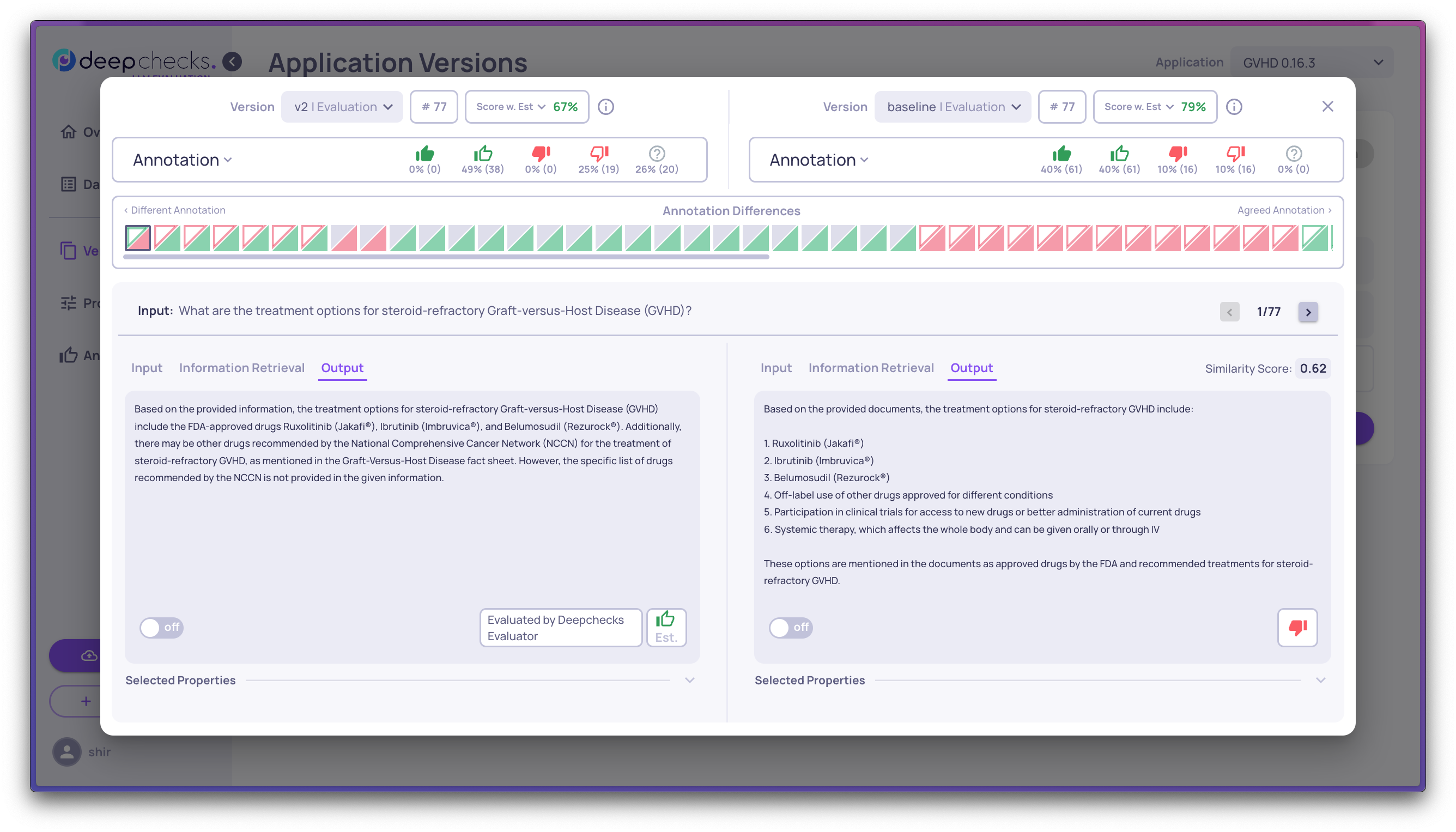
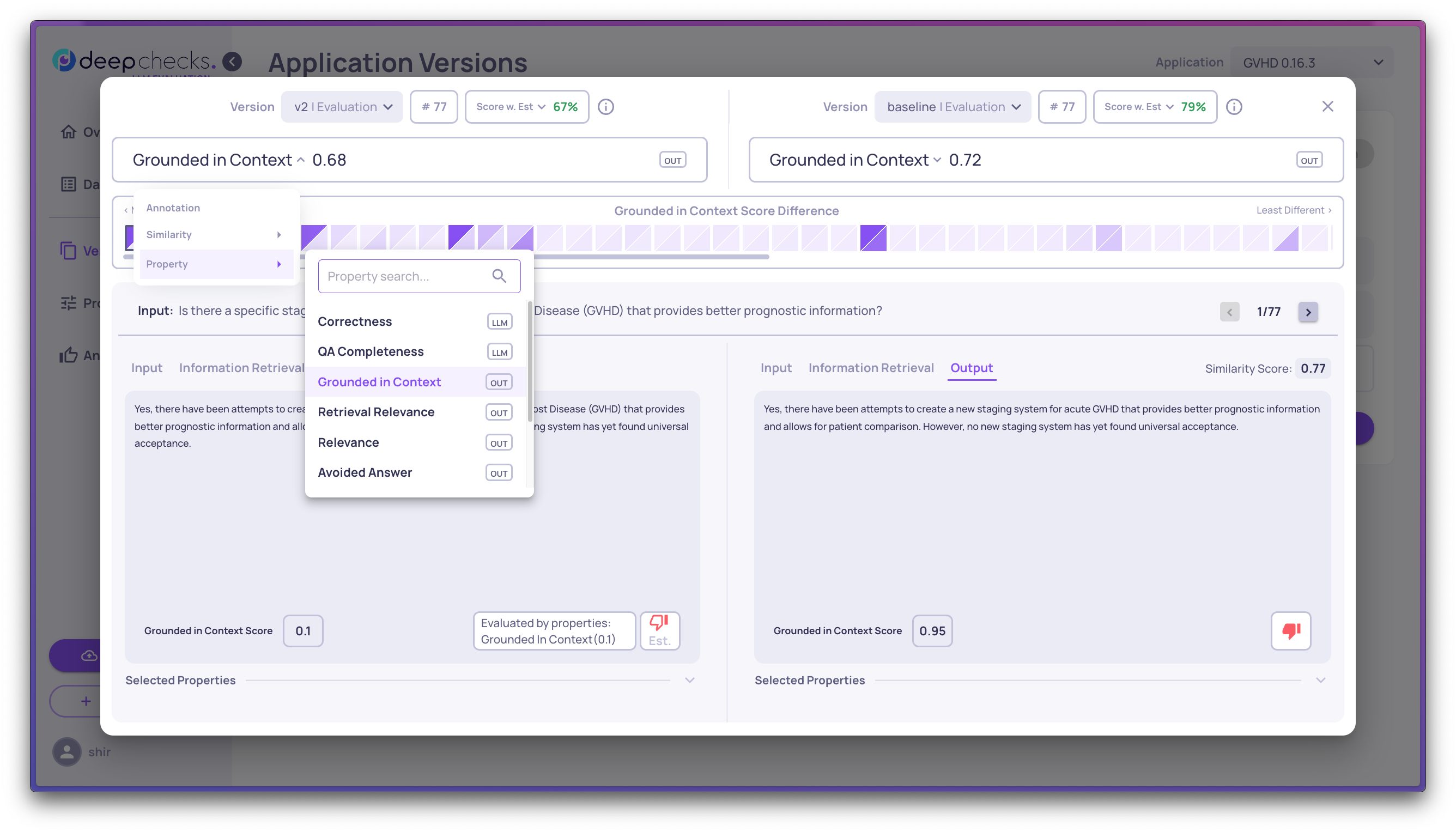
You can choose according to what you'd like to compare between the versions, e.g. see the interactions according to where they differ on a specific property.
Updated 9 months ago