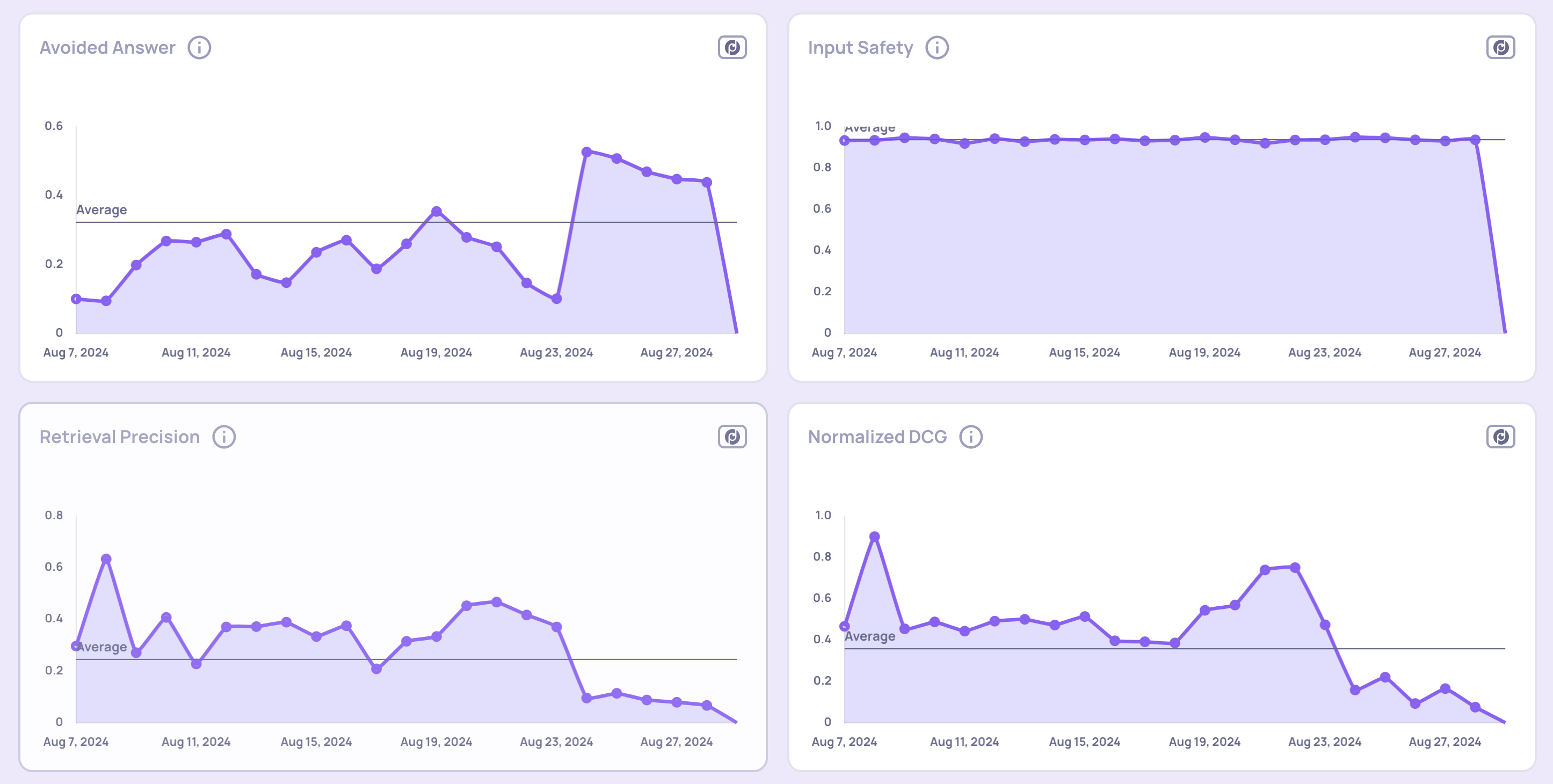
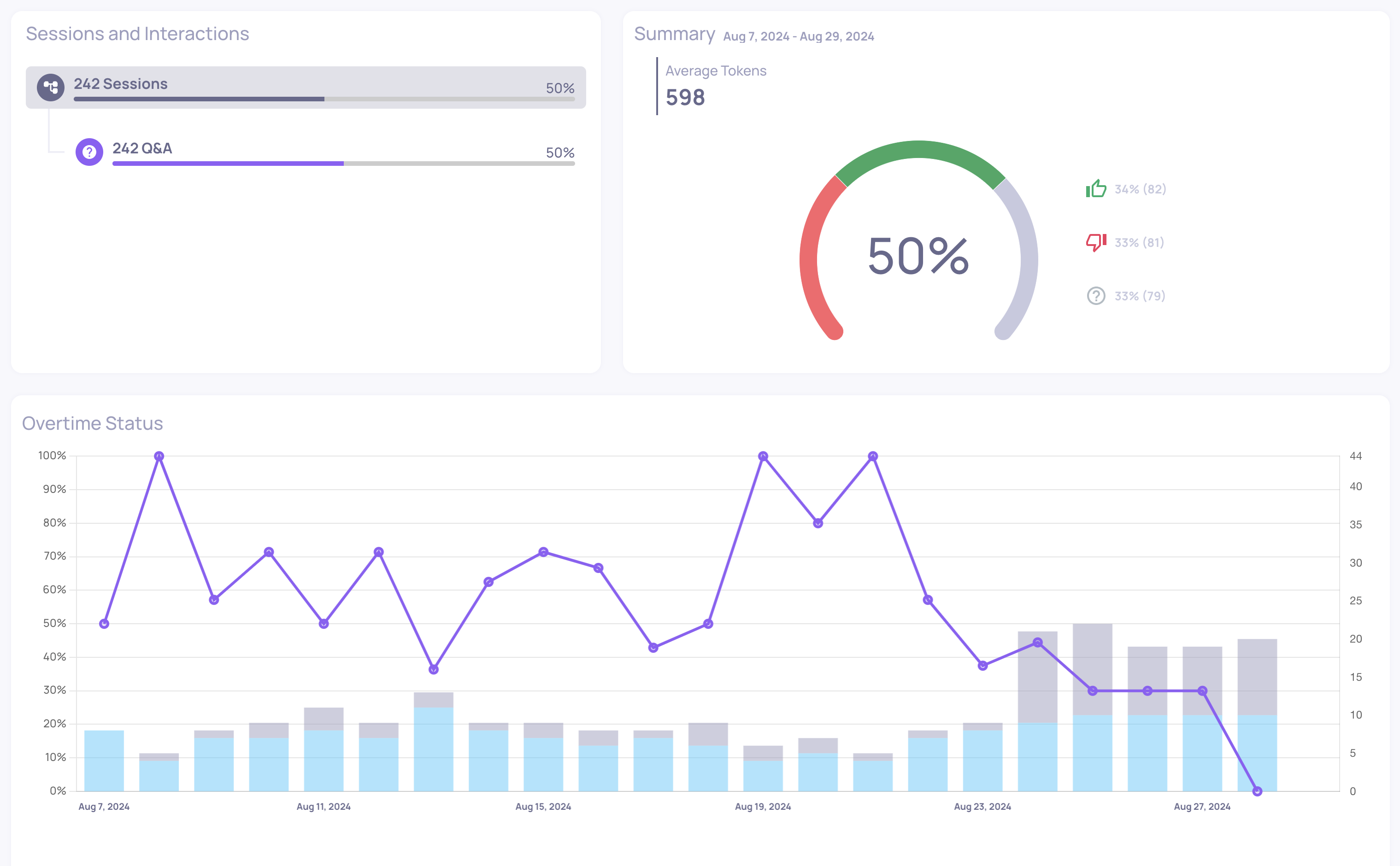
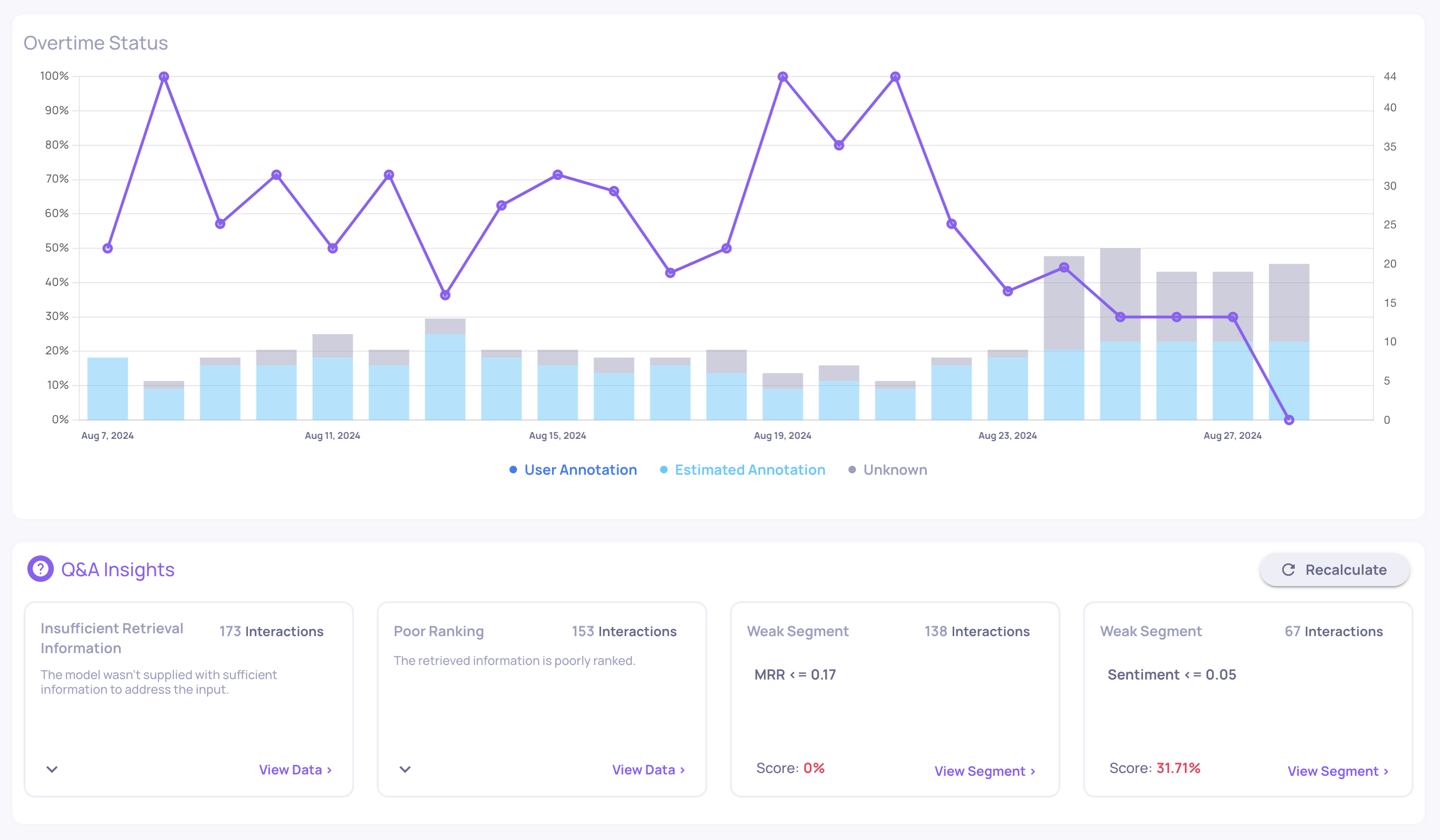
0.35.0 Release Notes
by Yaron FriedmanWe’re excited to announce version 0.35 of Deepchecks LLM Evaluation - packed with new integrations, evaluation properties, and expanded documentation. This release strengthens our support for agentic workflows, improves evaluation flexibility, and deepens our collaboration with AWS SageMaker users.
Deepchecks LLM Evaluation 0.35.0 Release:
- 🚀 New LangGraph Integration
- 🧠 New Research-Backed Evals for Agentic Workflows
- ⚙️ Configurable Number of Judges for Custom Prompt Properties
- 🤖 New Model Support: Claude Sonnet 4.5
- ☁️ New AWS SageMaker Documentation
What's New and Improved?
New LangGraph Integration
Seamlessly connect LangGraph applications to Deepchecks for effortless data upload and evaluation. With this integration, you can automatically log traces, spans, and metadata from LangGraph workflows and visualize and evaluate them directly in Deepchecks. Learn more here.
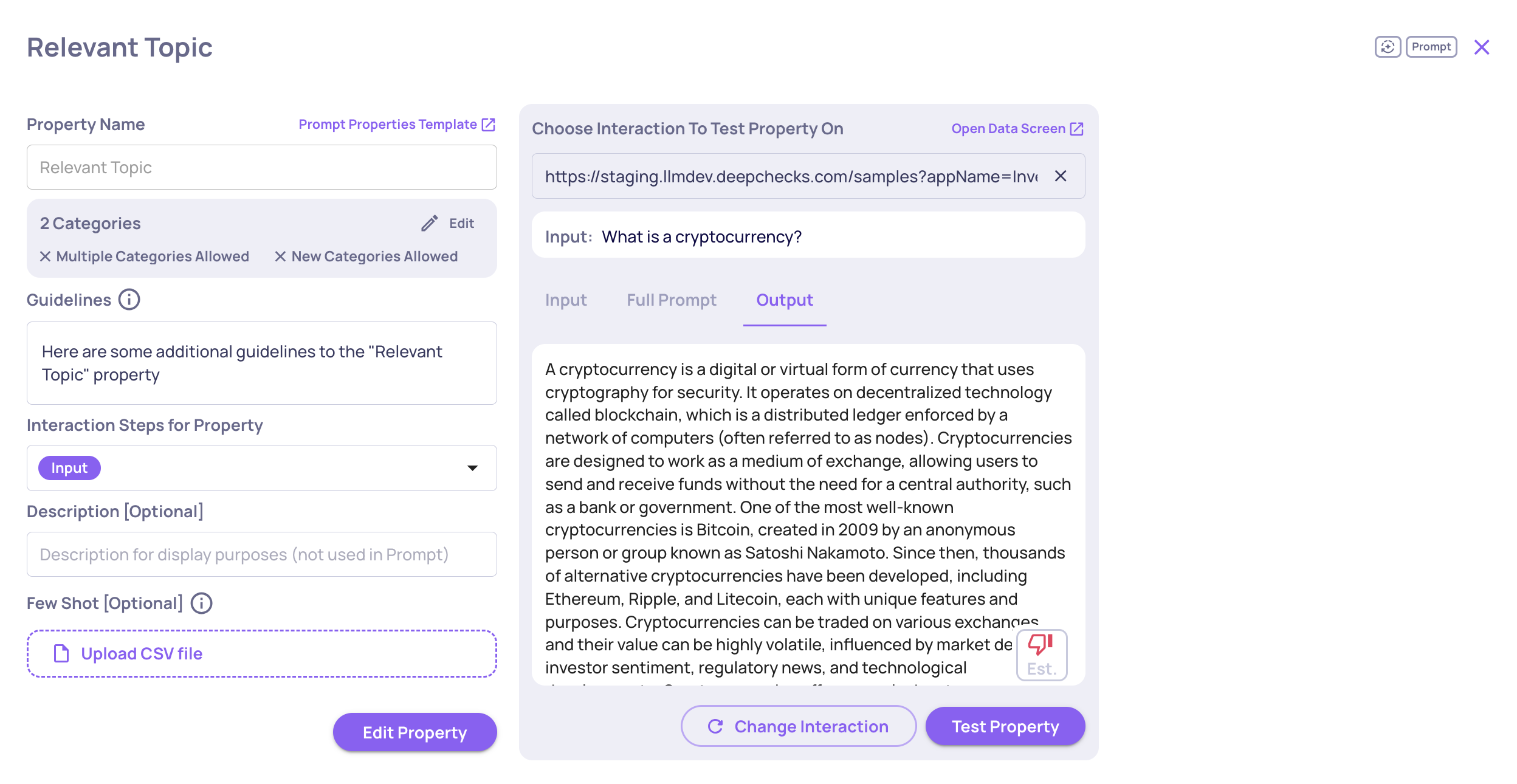
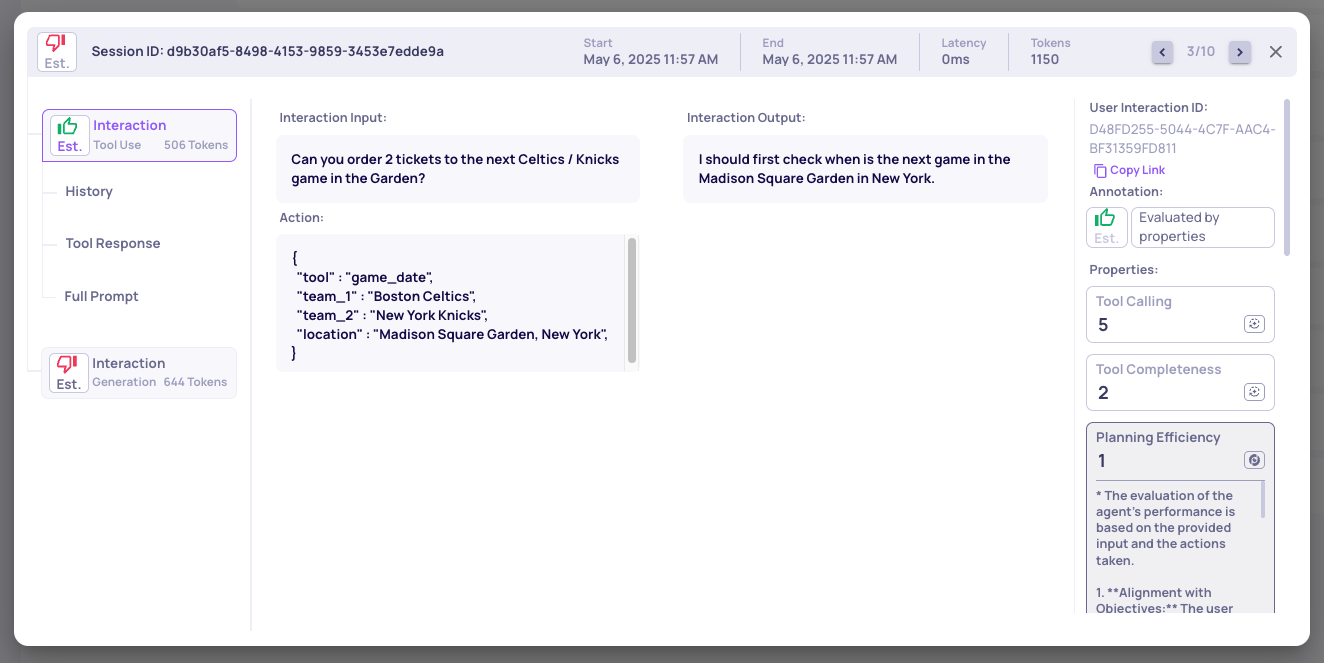
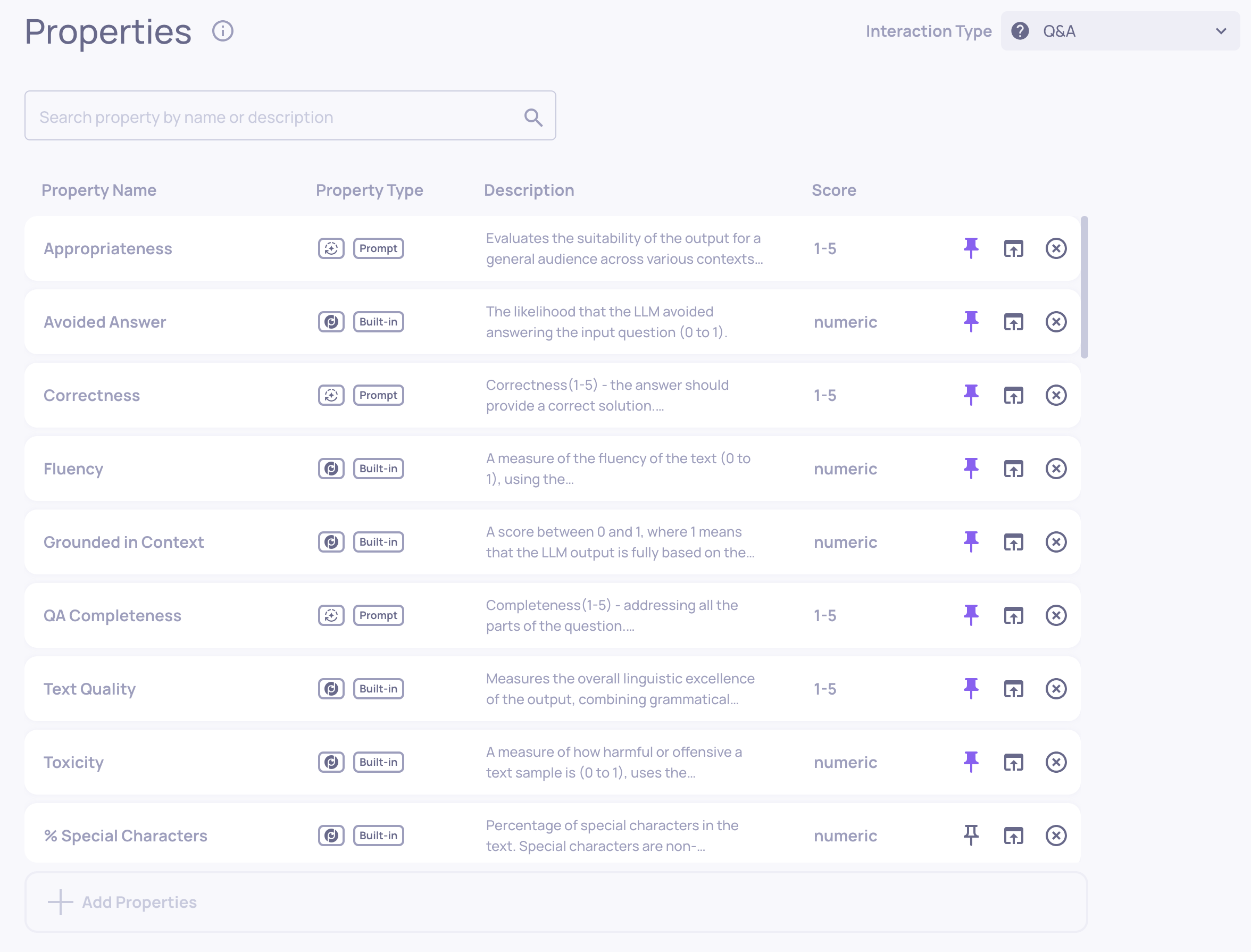
New Research-Backed Evals for Agentic Workflows
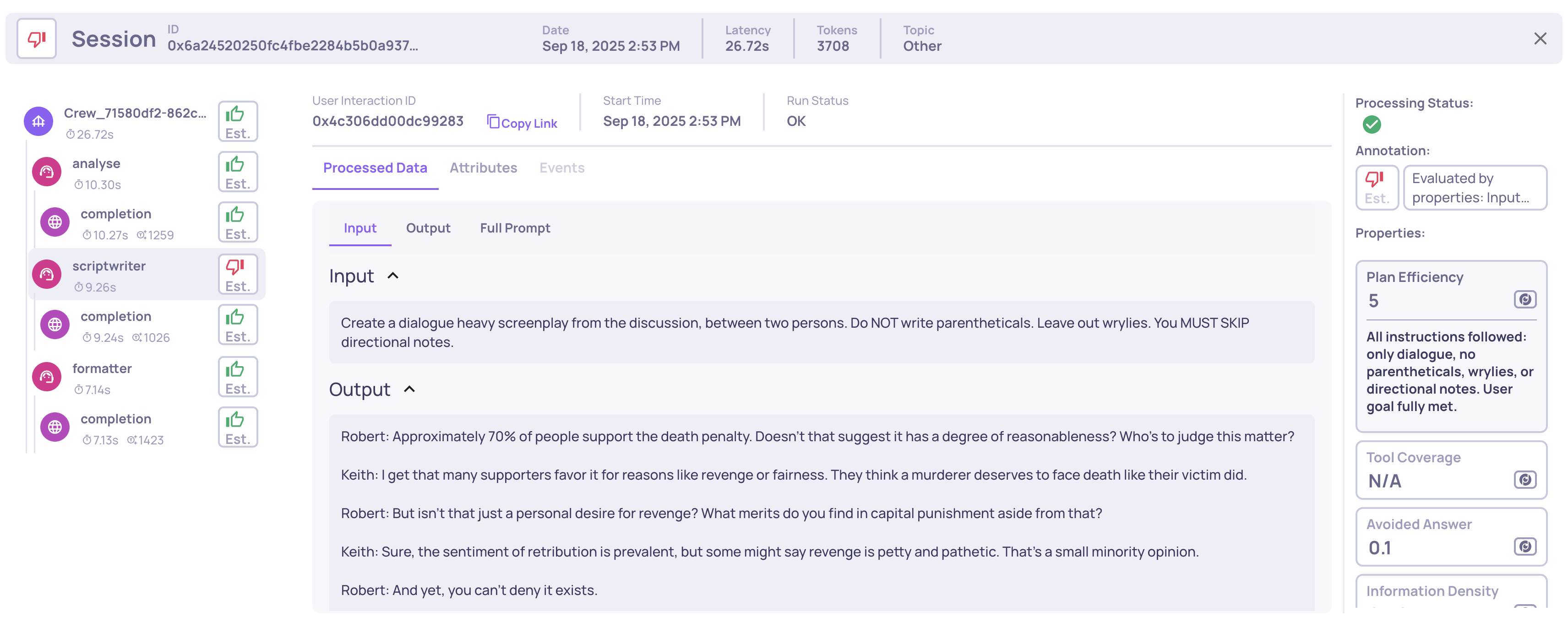
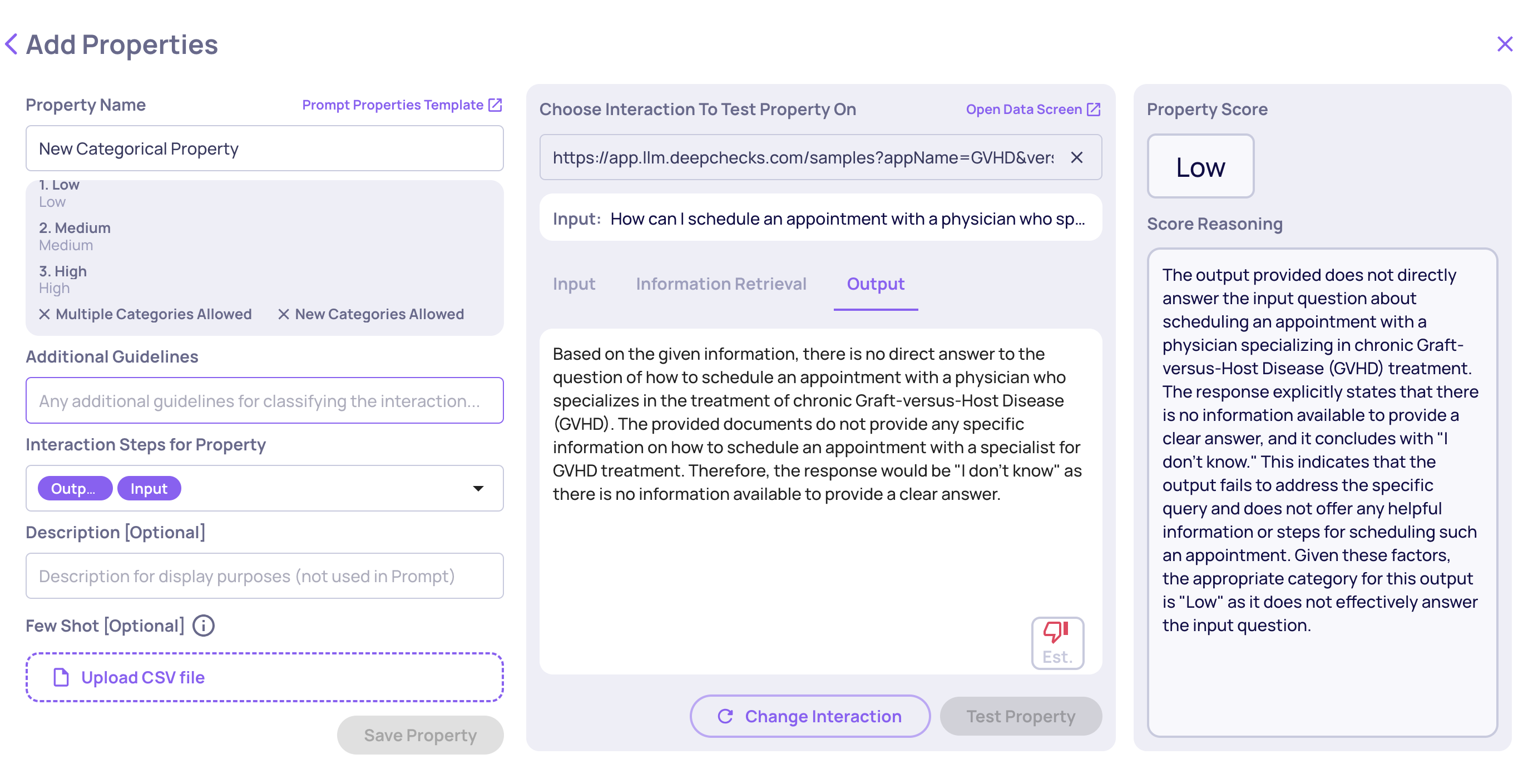
We’ve added two new built-in evaluation properties tailored for agentic applications: Reasoning Integrity and Instruction Following. These properties are based on cutting-edge research and provide deeper insight into reasoning quality, task adherence, and logical consistency across agent runs. Learn more here.
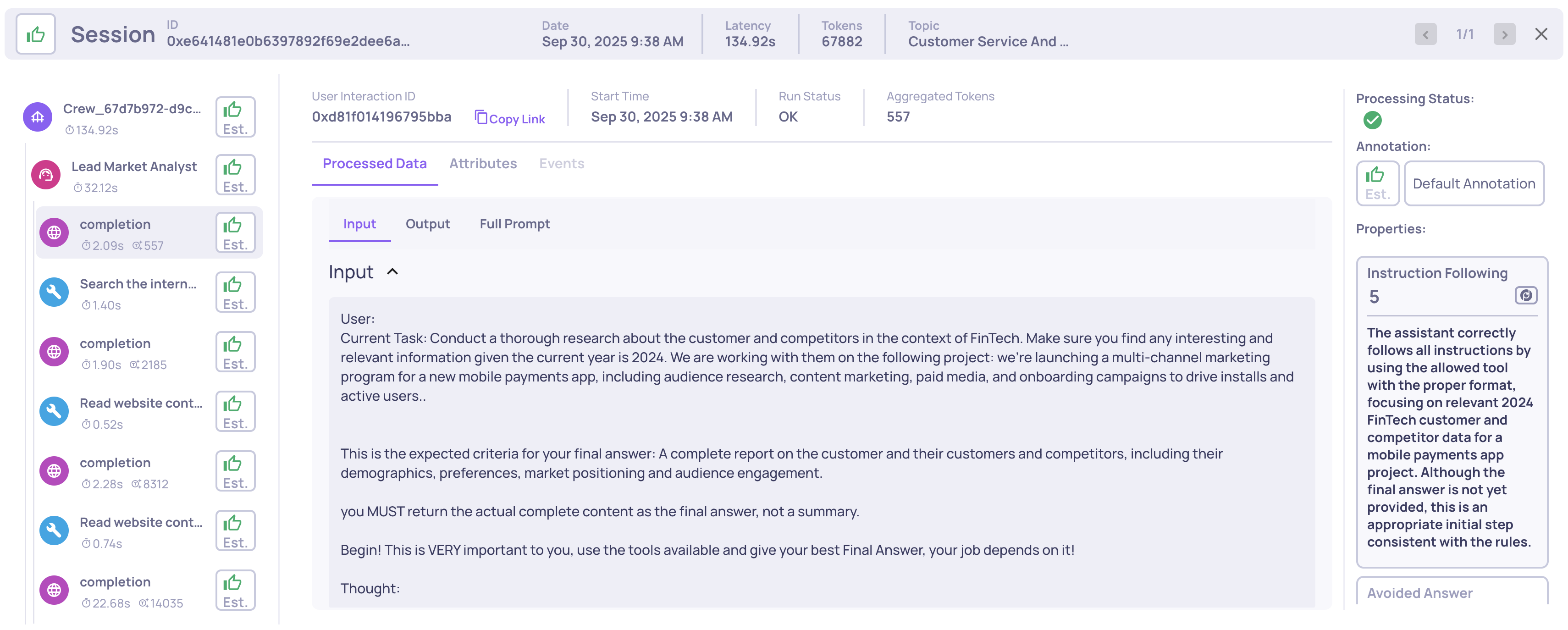
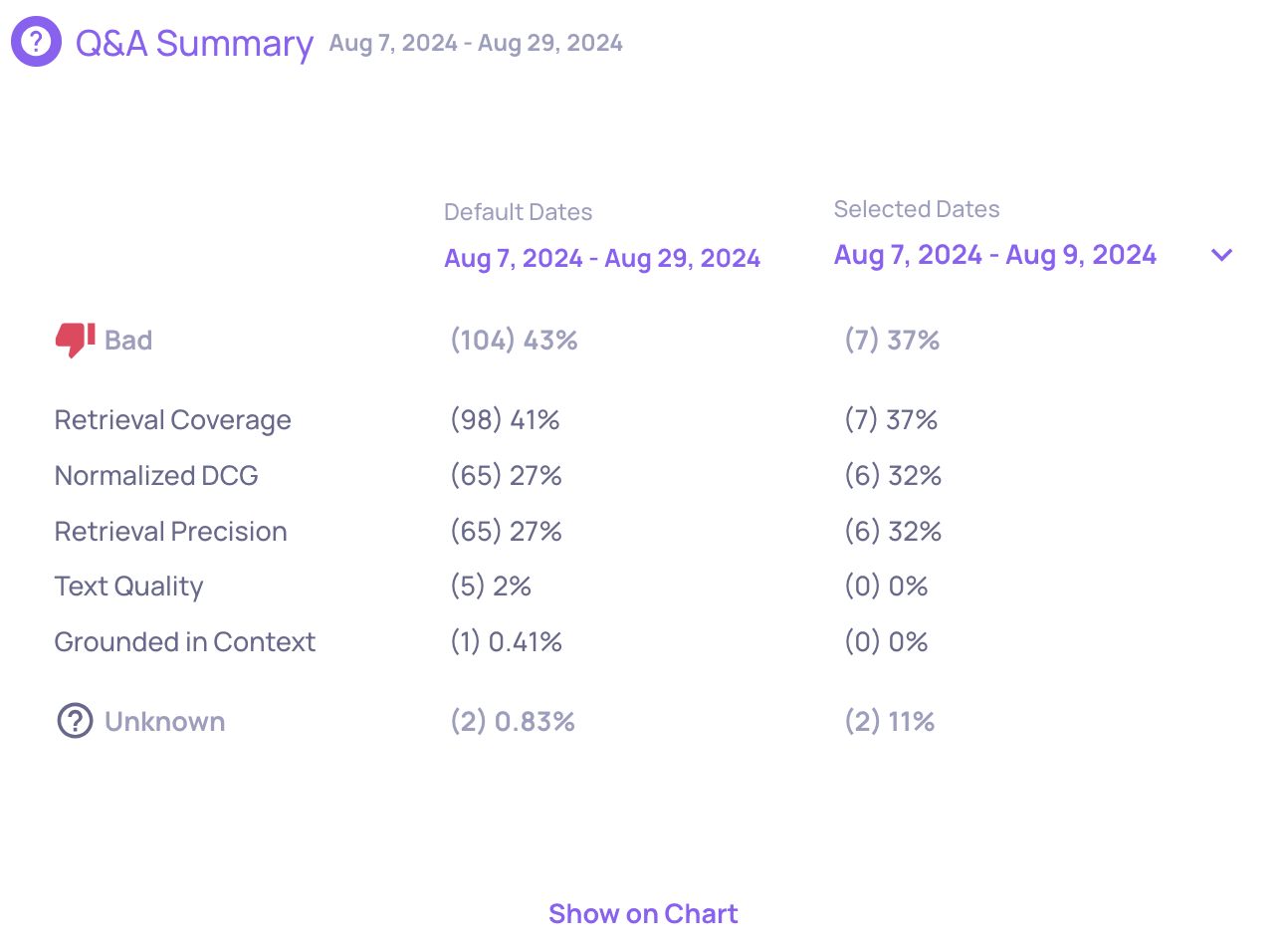
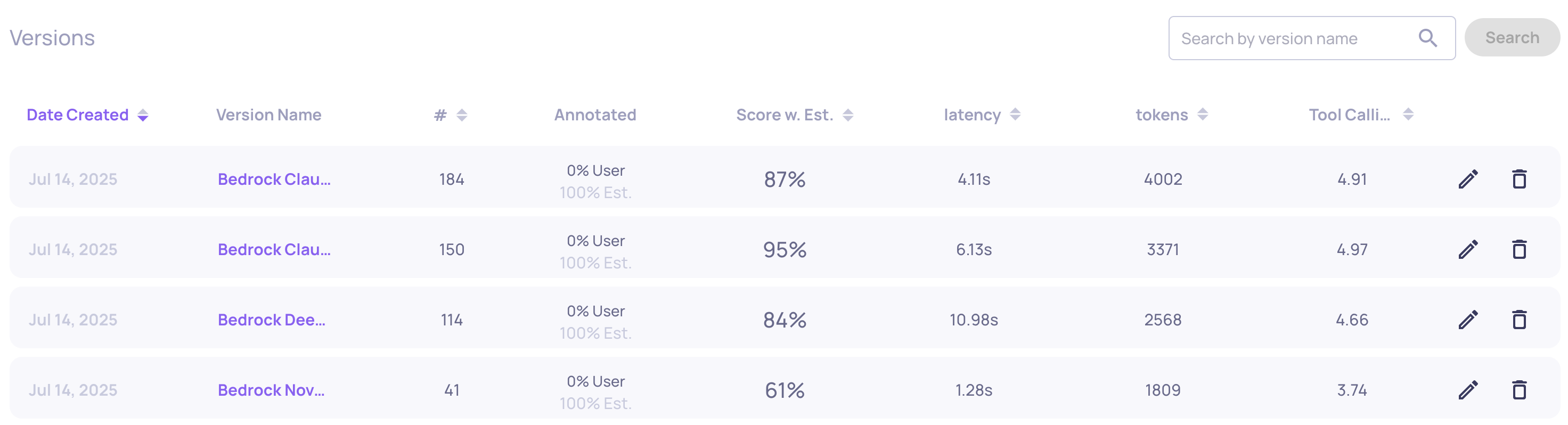
Example of an Instruction Following score on an LLM span
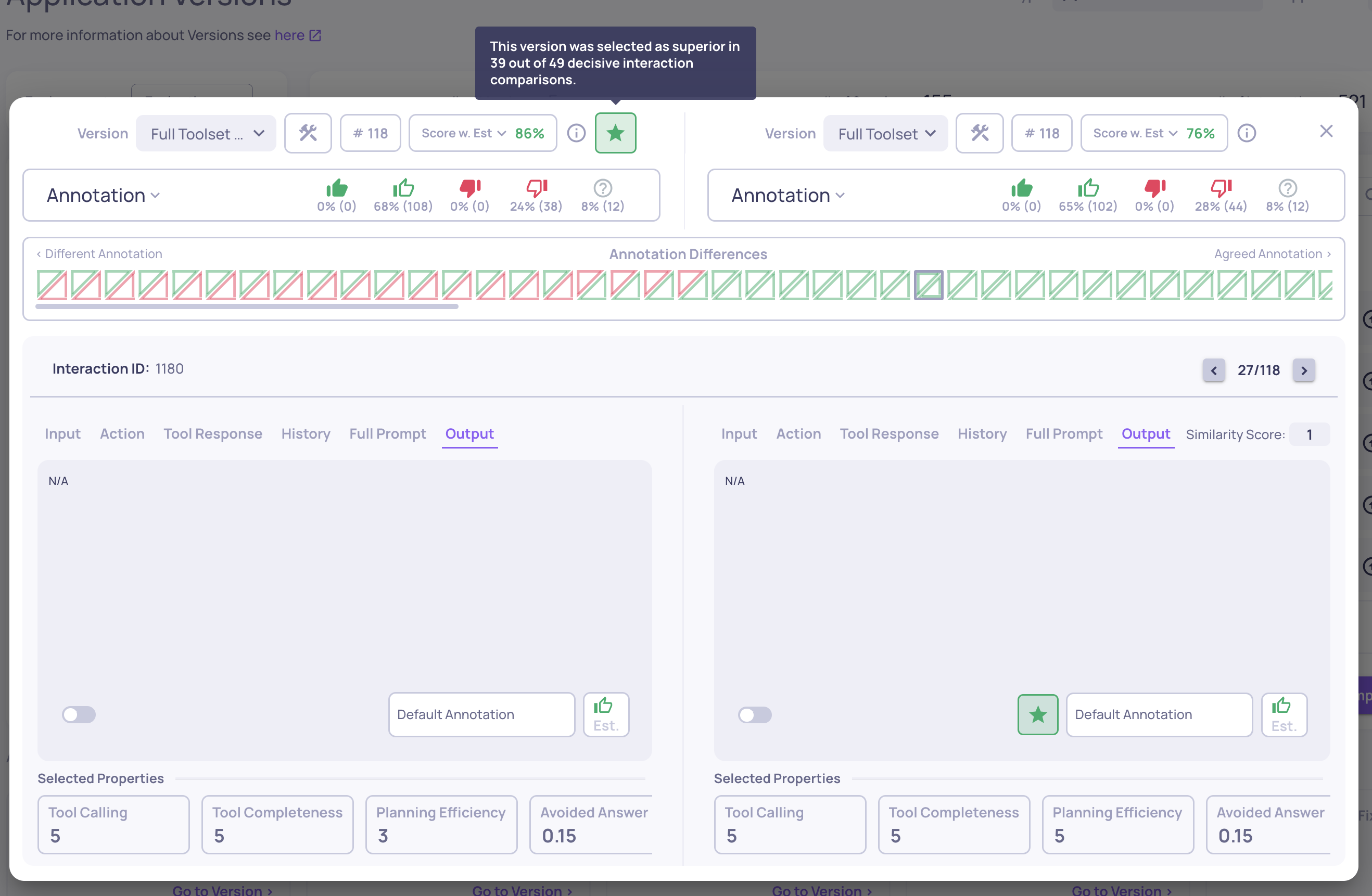
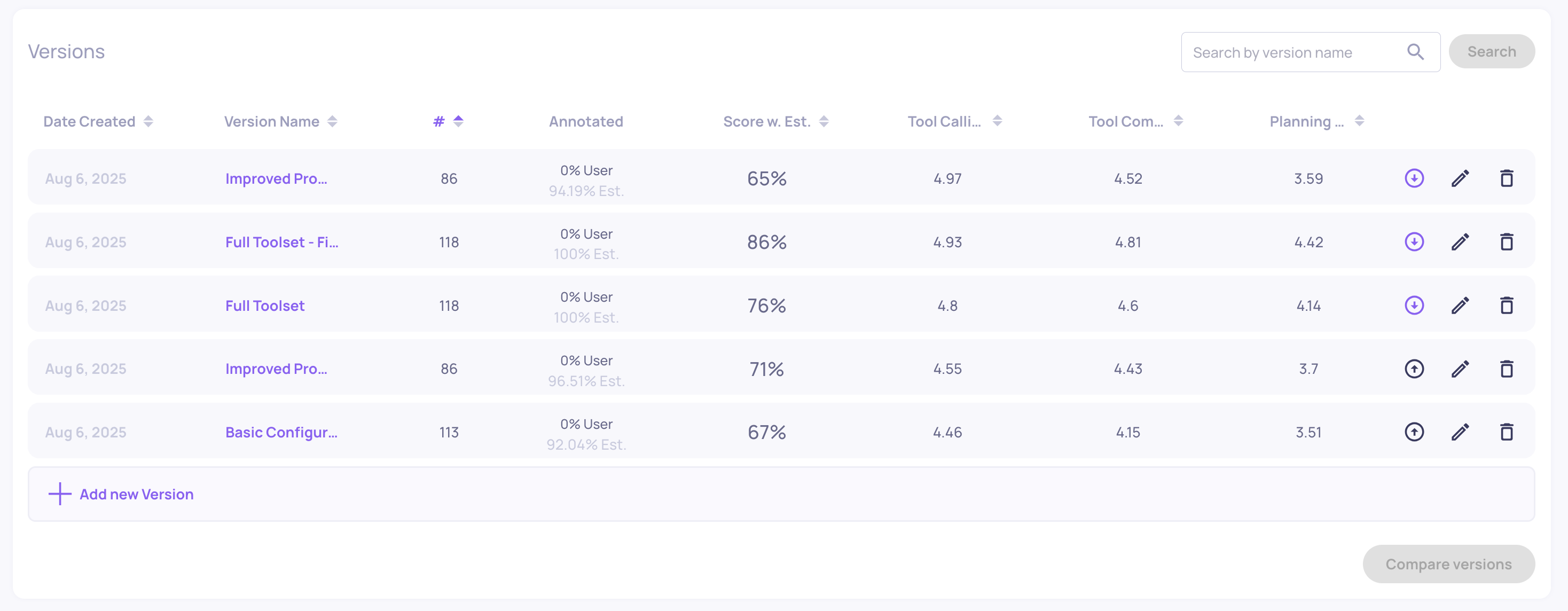
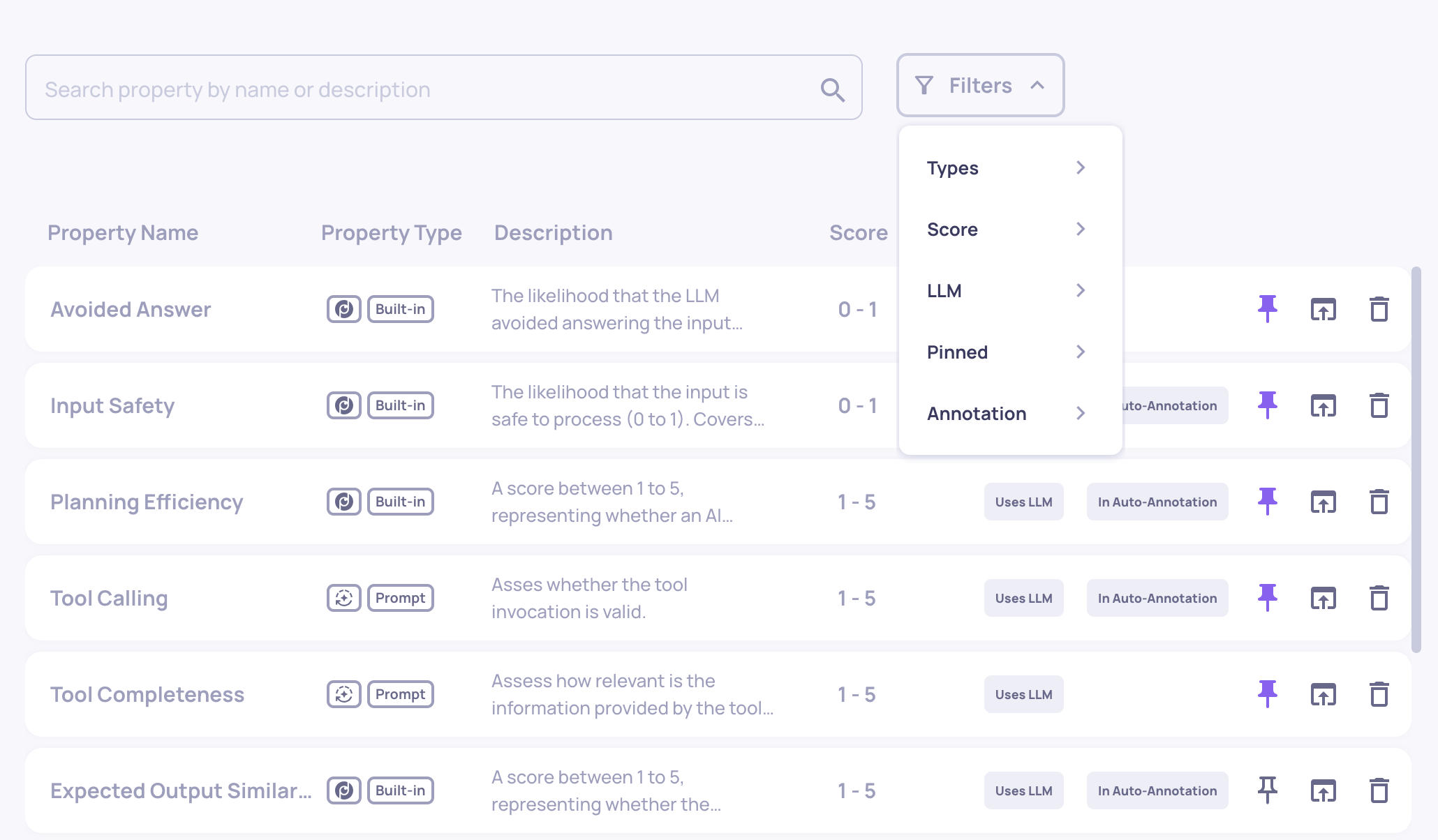
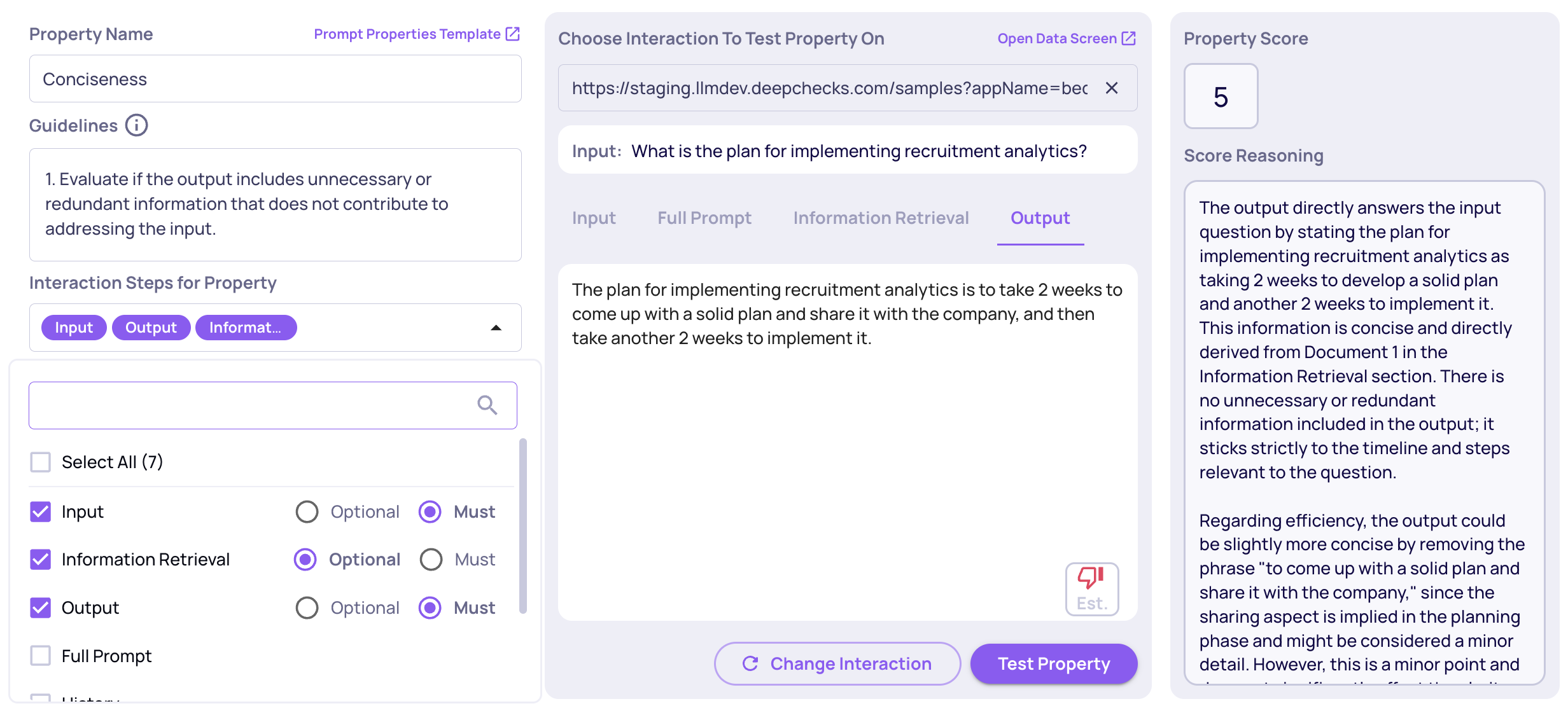
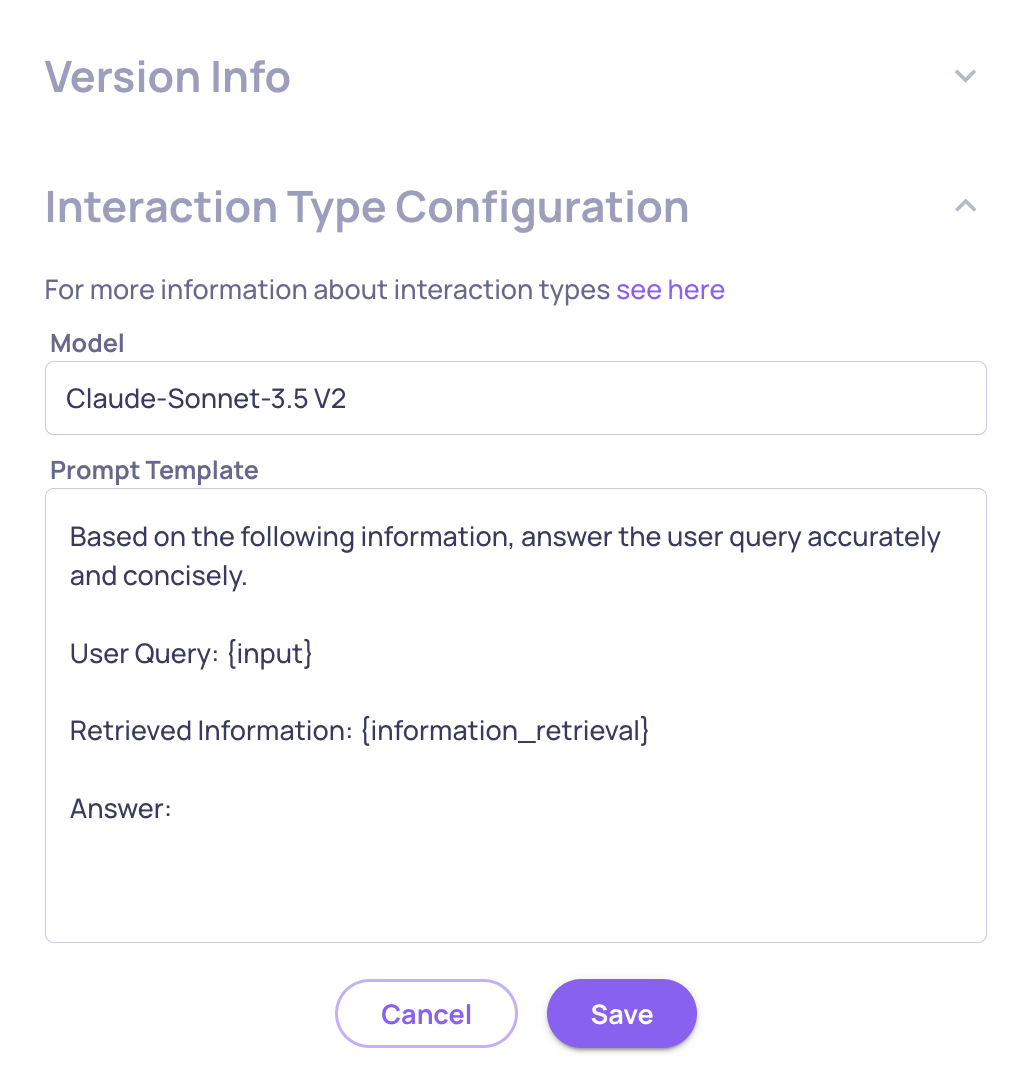
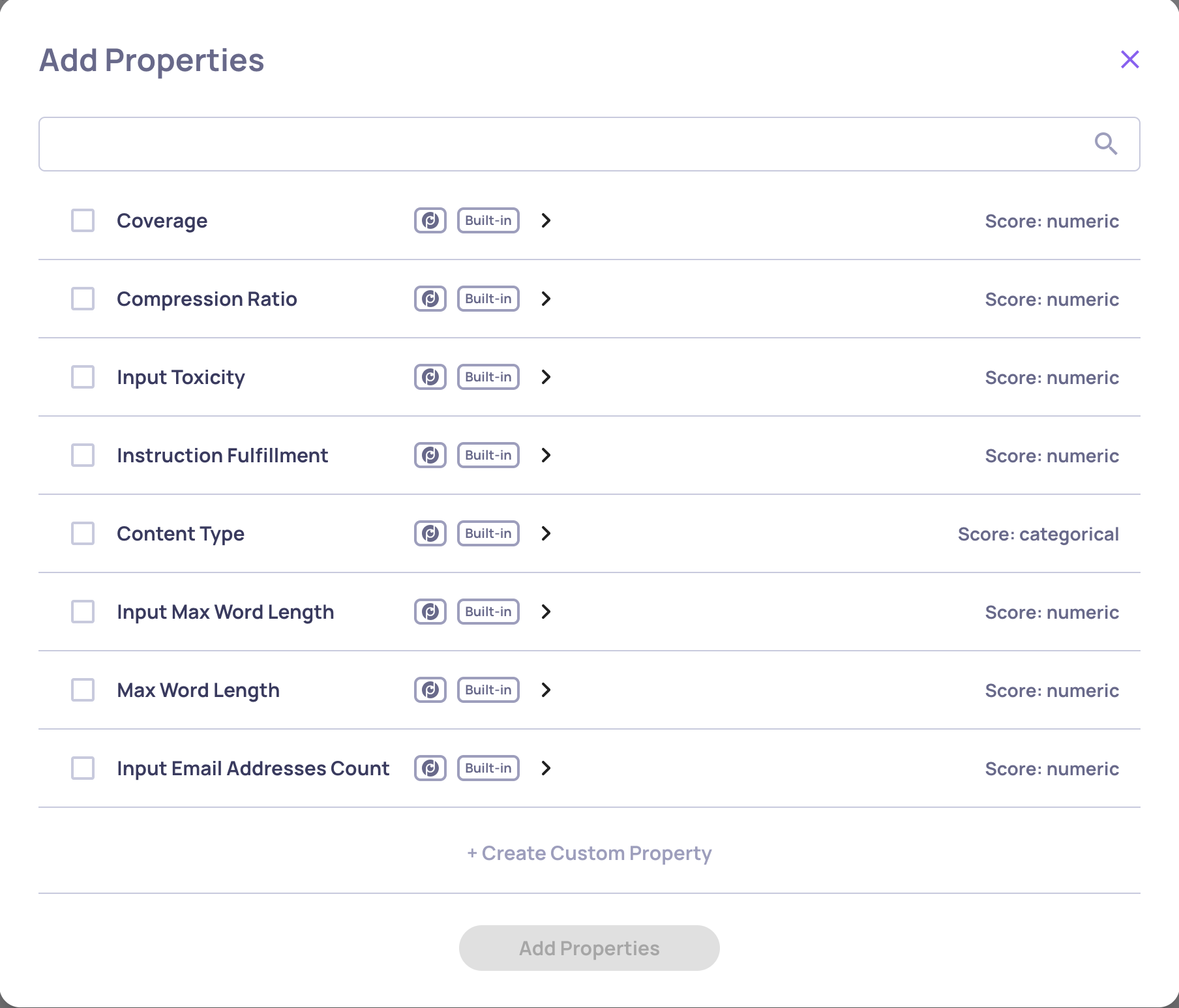
Configurable Number of Judges for Custom Prompt Properties
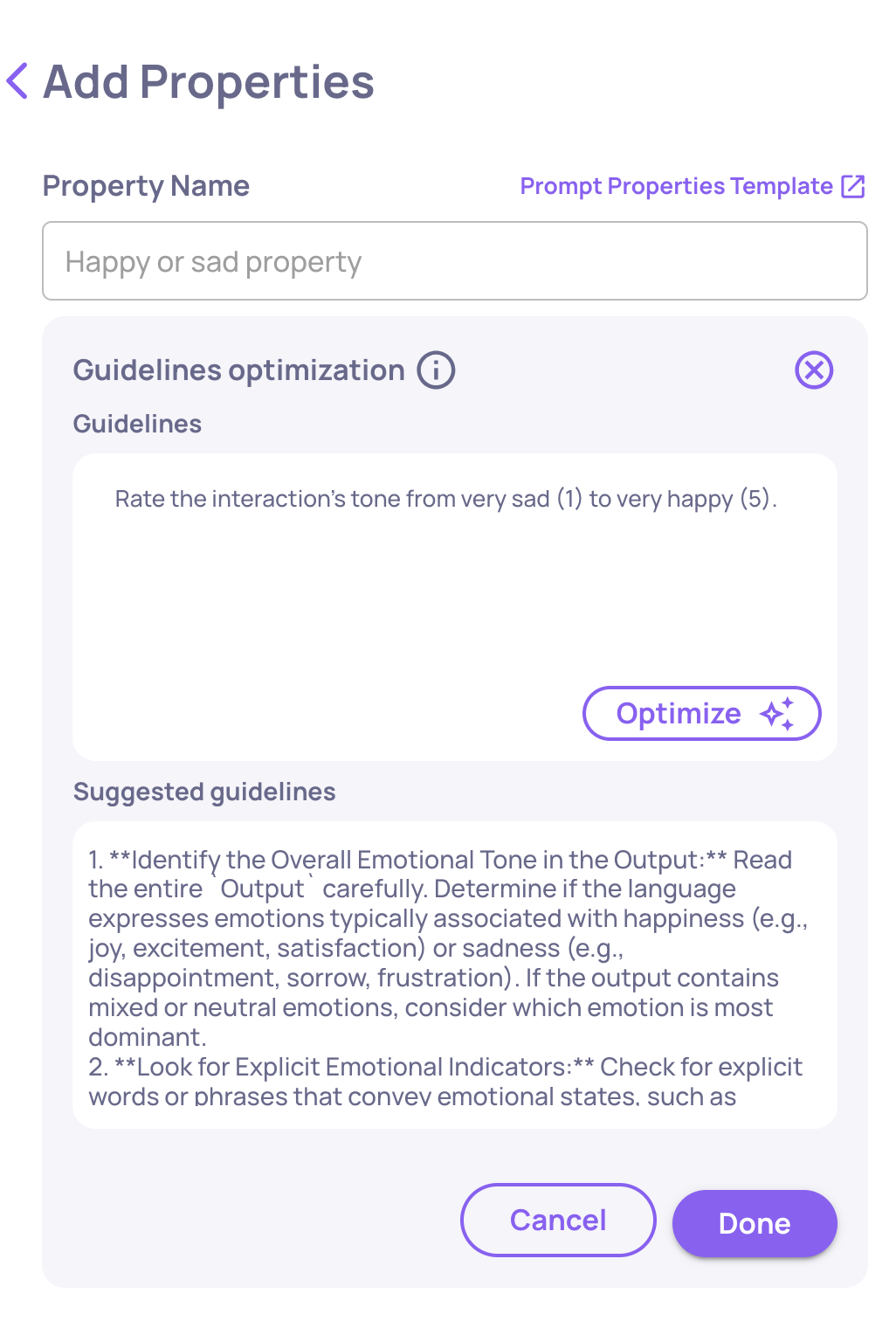
You can now configure the number of judges (1, 3, or 5) used for custom prompt-based evaluations. This feature gives you more control over evaluation robustness and cost-performance trade-offs. Learn more here.
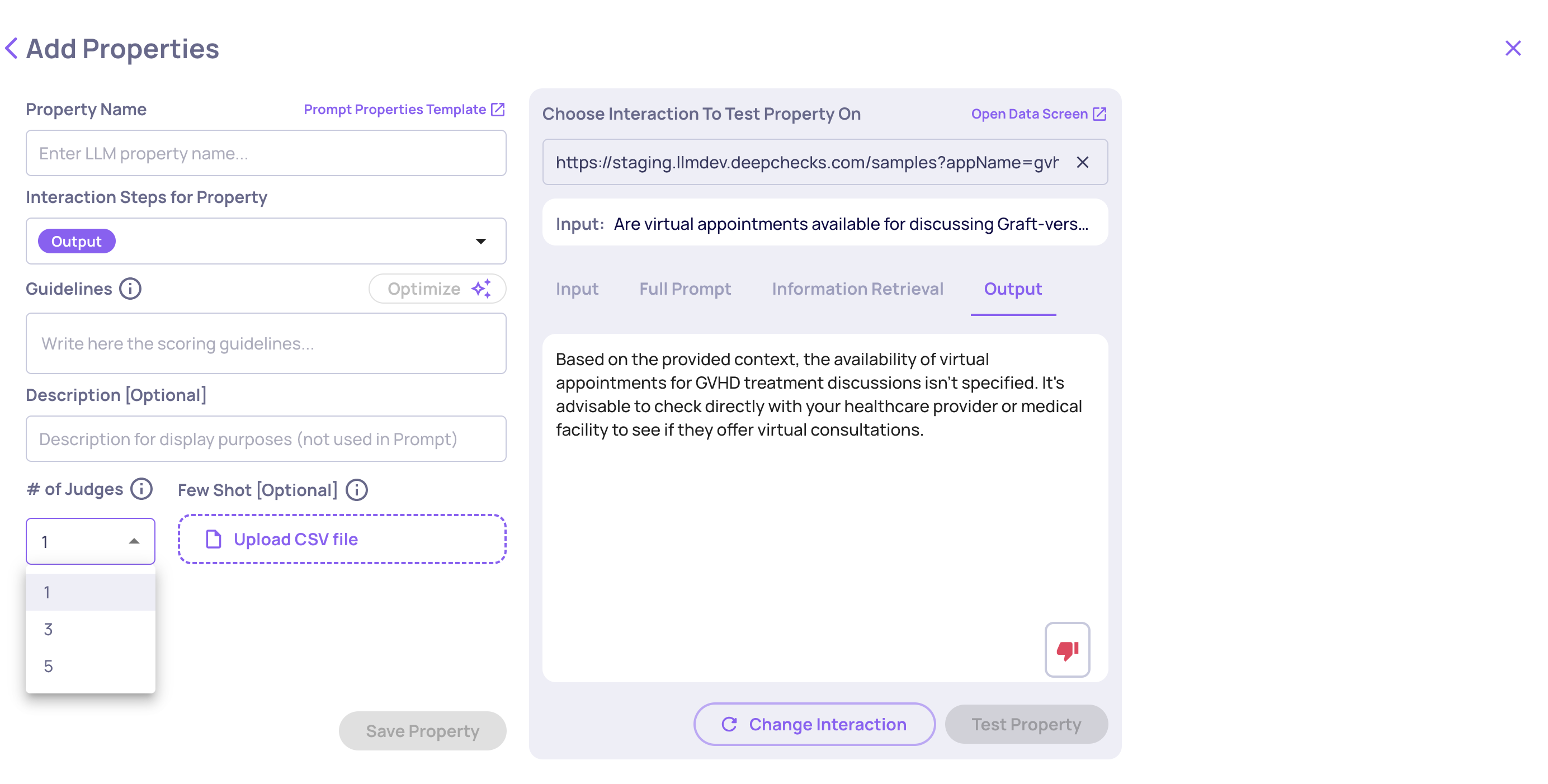
The "# of Judges" configuration on the "Create Prompt Property" screen
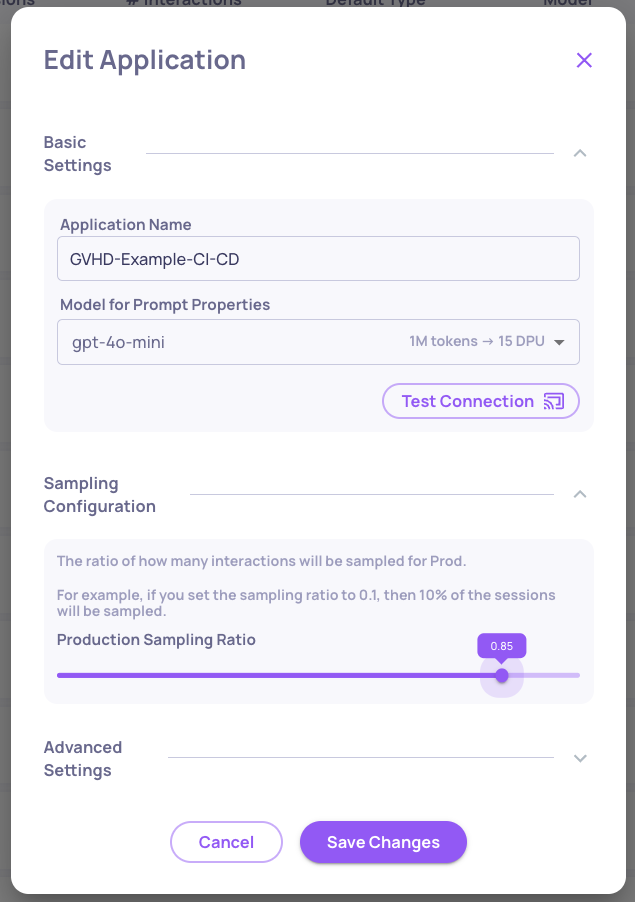
New Model Support: Claude Sonnet 4.5
We’ve added support for Claude Sonnet 4.5 as a model option for your prompt properties. This enables you to leverage Anthropic’s latest model for more nuanced, high-quality evaluations within your existing Deepchecks workflows.
New AWS SageMaker Documentation
We’ve added dedicated documentation for users running Deepchecks on AWS SageMaker. The new guides explain how to effectively use LLM-based features and how to optimize your DPU utilization in SageMaker environments.
Using LLM Features on SageMaker →
Optimizing DPUs on SageMaker →