GVHD Use Case : Q&A Example
Evaluating and debugging a Q&A application, step by step
Use Case Background
The data in this tutorial originates from a classic Retrieval Augmented Generation bot that answers questions about the GVHD medical condition.
We're evaluating a GPT-3.5 LLM-based app that uses FAISS for the retrieval embedding vectors, with differences in the retrieval strategies and temperatures between the two versions.
The knowledge base is built from a collection of online resources about the condition.
The two datasets used for this example can be downloaded from this link .
Structure of this Example
- Creating your first application, and uploading a baseline version and a new version to evaluate.
- Exploring a few flows for evaluating using system:
Note: if you already have the data for the two versions uploaded, and just want to see the value in the system, jump straight to the Exploring the flows sections.
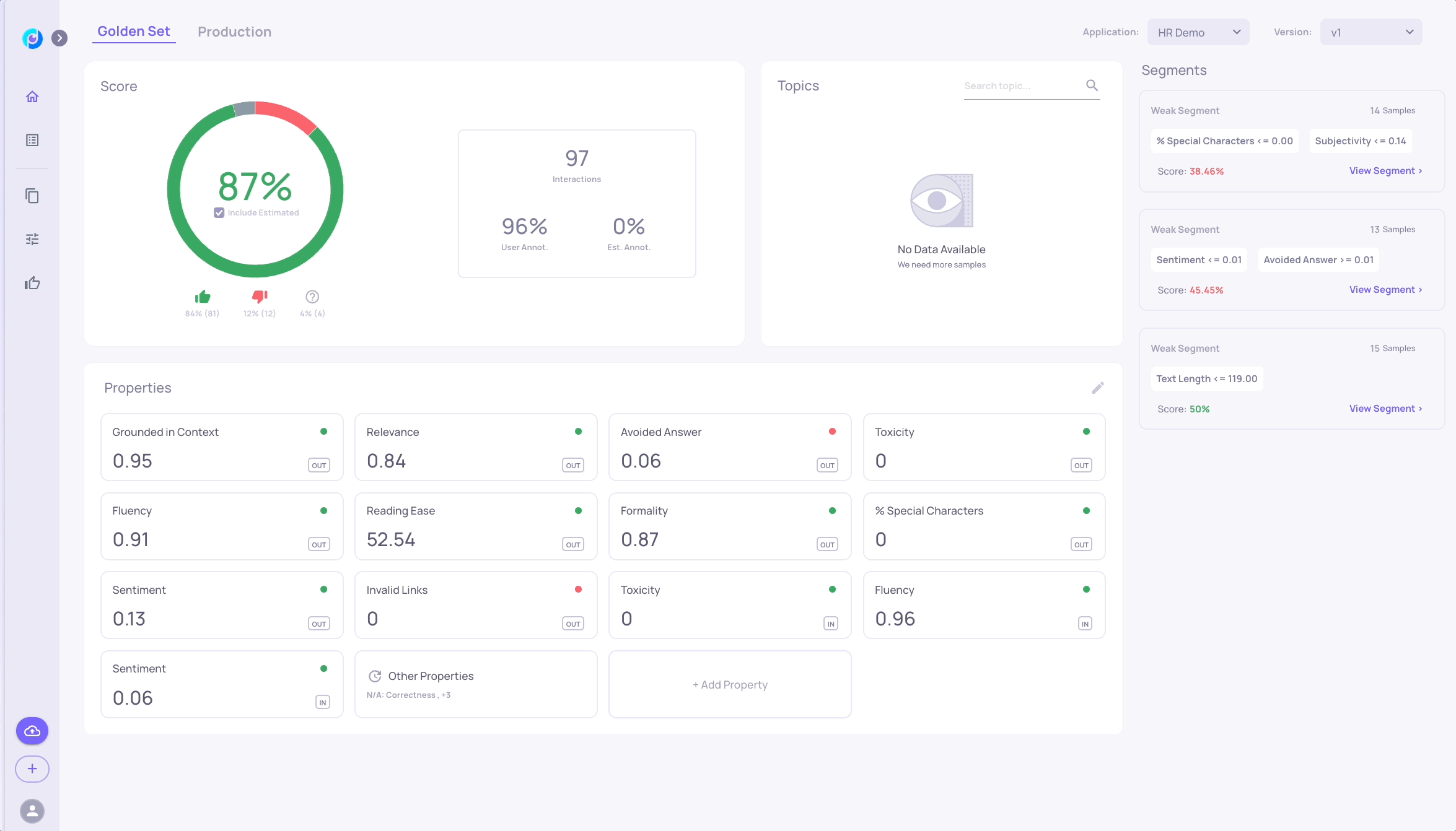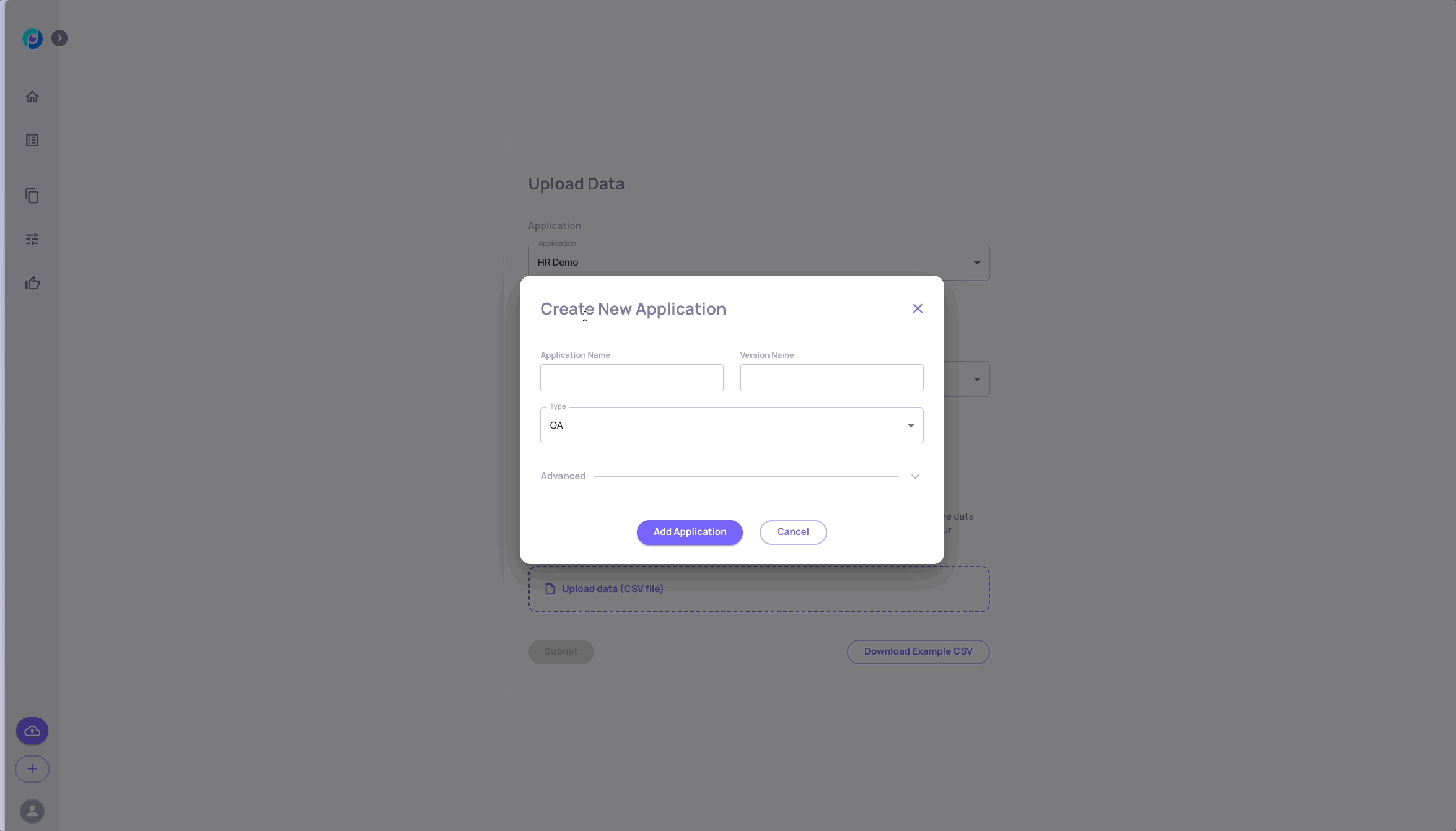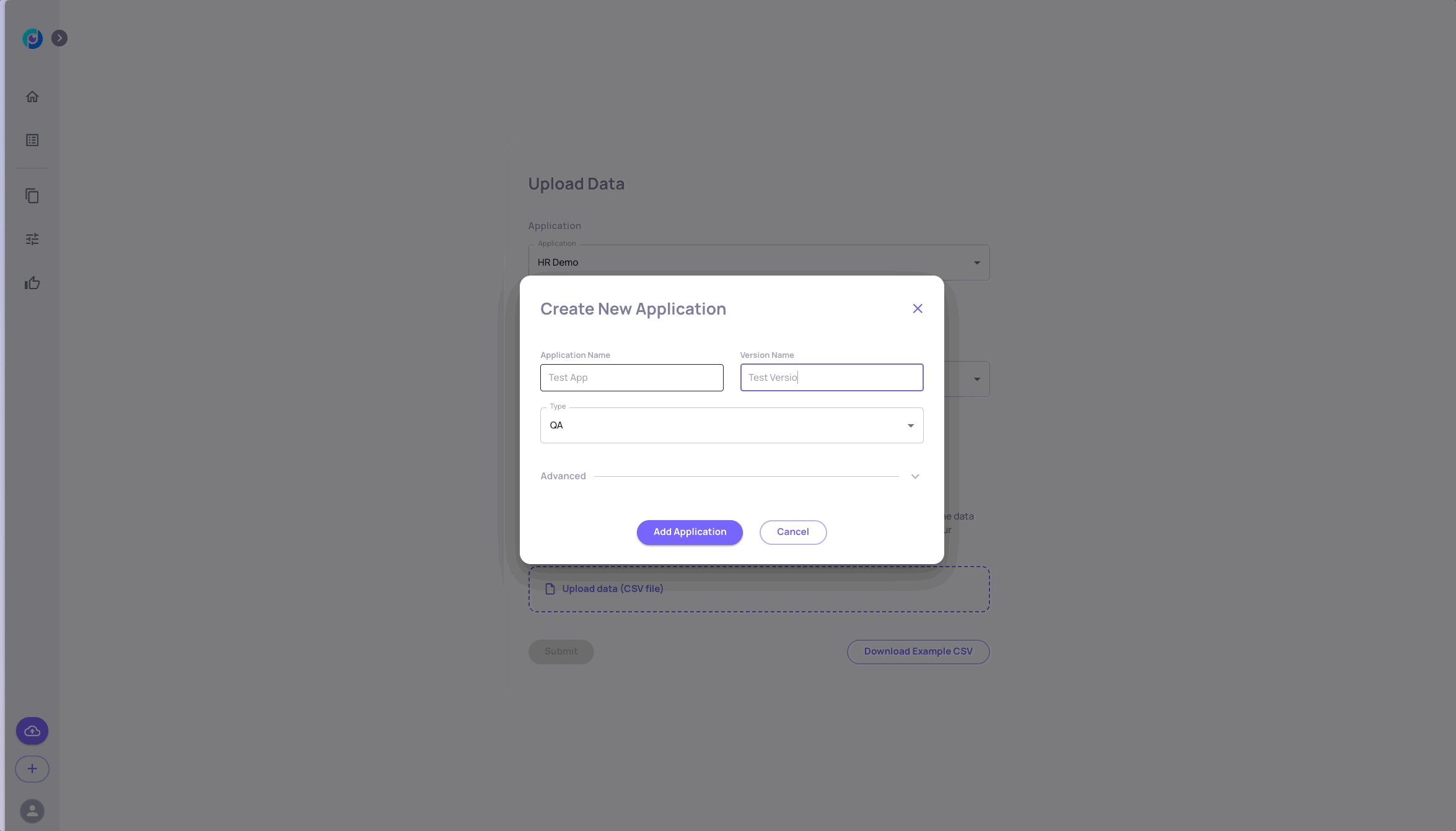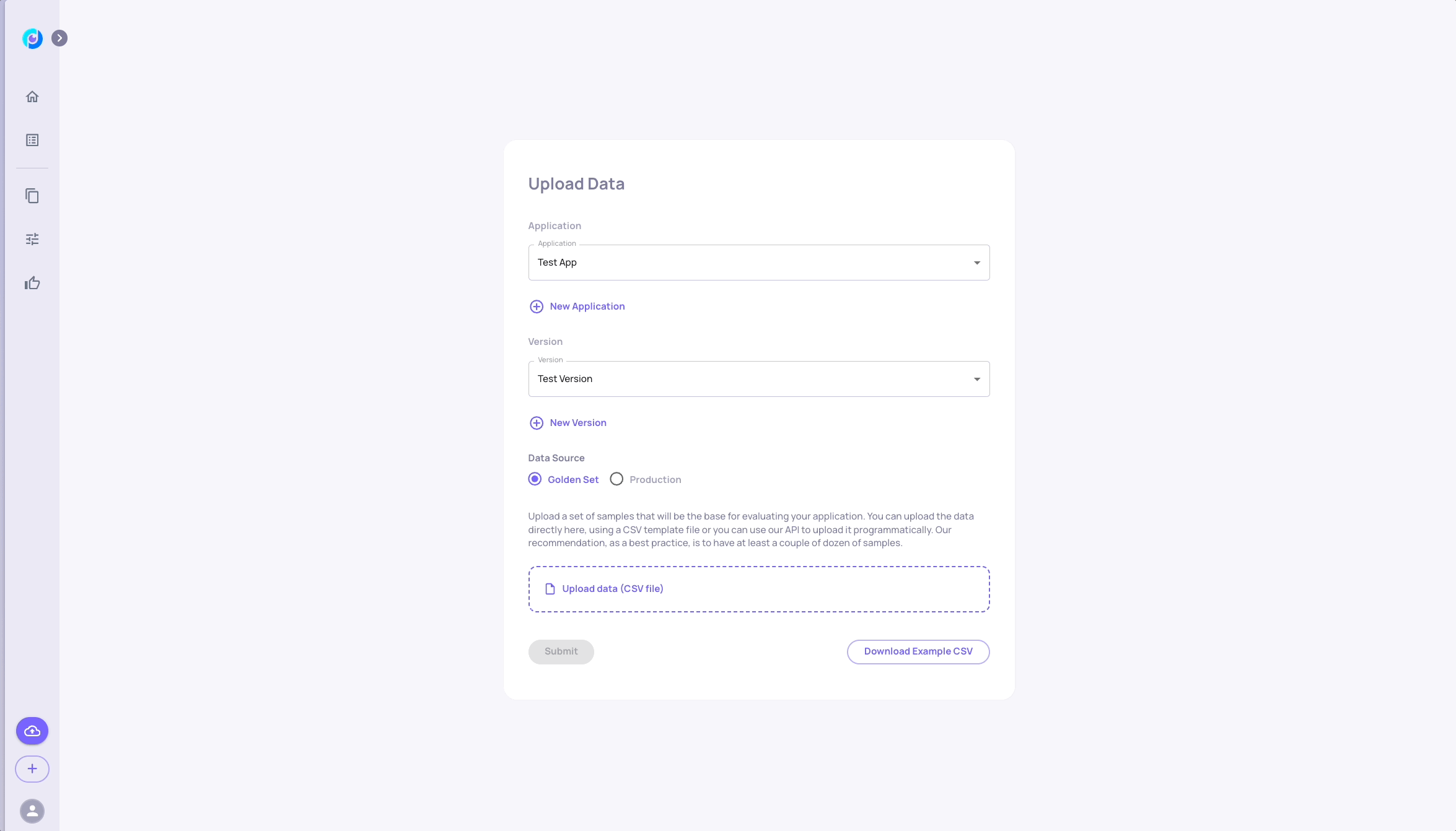
Create Your Application and Upload the Data to the System
Unlike other system elements, applications must be created through the UI before they can be used through the SDK. The application and version names you select will be used later on.
app_nameandversion_nameThe application (in this example gif
"DemoApp") has to be created in the system through the UI prior to using the SDK. Versions on the other hand are automatically created, if a version_name that was not previously defined is sent via the SDK.
For our scenario, let's fill in the Application Name field to be: "GVHD", and the Version Name to be "baseline"
Option 1: Upload the Data with Deepchecks' UI
- Upload the baseline_data version csv to the Evaluation environment.
- Add a new version, and upload the second csv (v2_new_ir_data) to the Evaluation environment of the new version.
- You are all set! You can now check out your data in theDeepchecks Application!
In the "Applications" page, you should now see the "GVHD" App.
Note: Data Processing statusSome properties take a few minutes to calculate, so some of the data - such as properties and estimated annotations will be updated over time. You'll see a "✅ Completed" Processing Status in the Applications page, when processing is finished. In addition, you can subscribe to notifications in the "Workspace Settings", to get notified by email upon processing completion.

Option 2: Upload the Data with Deepchecks' SDK
Set up the Deepchecks client to use the Python SDK (as a best practice it is recommended to so so in a dedicated python virtual environment):
pip install deepchecks-llm-clientIn your Python IDE / Jupyter environment, set up the relevant configurations:
# Choose an app name for the application (same as filled in UI):
APP_NAME = "GVHD-demo"
# Choose a name for the first version you'll create (same as in UI):
BASE_VERSION = "baseline"
# Retrieve your API KEY from the deepchecks UI, as seen in the following gif:
DC_API_KEY = "insert-your-token-here"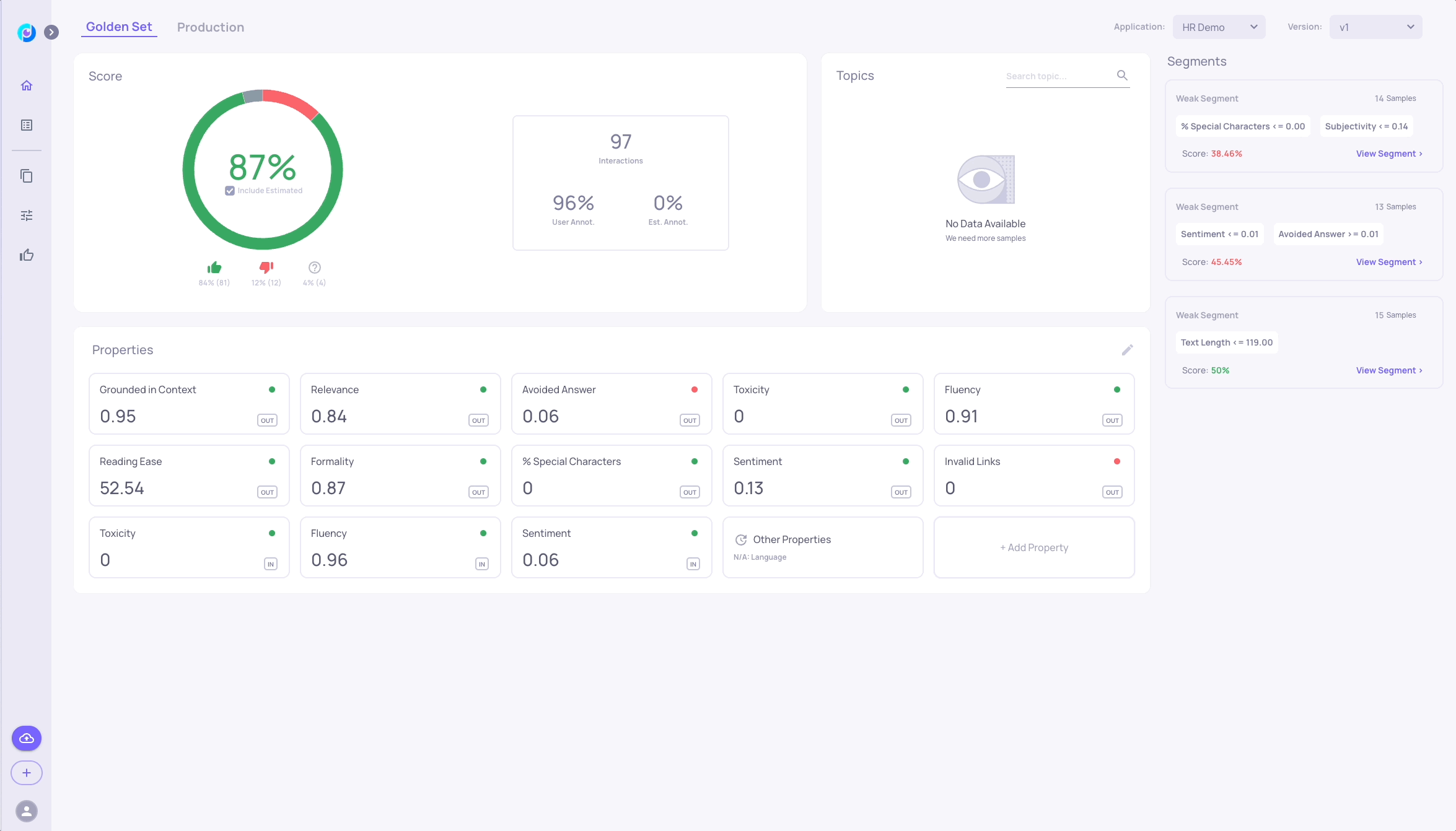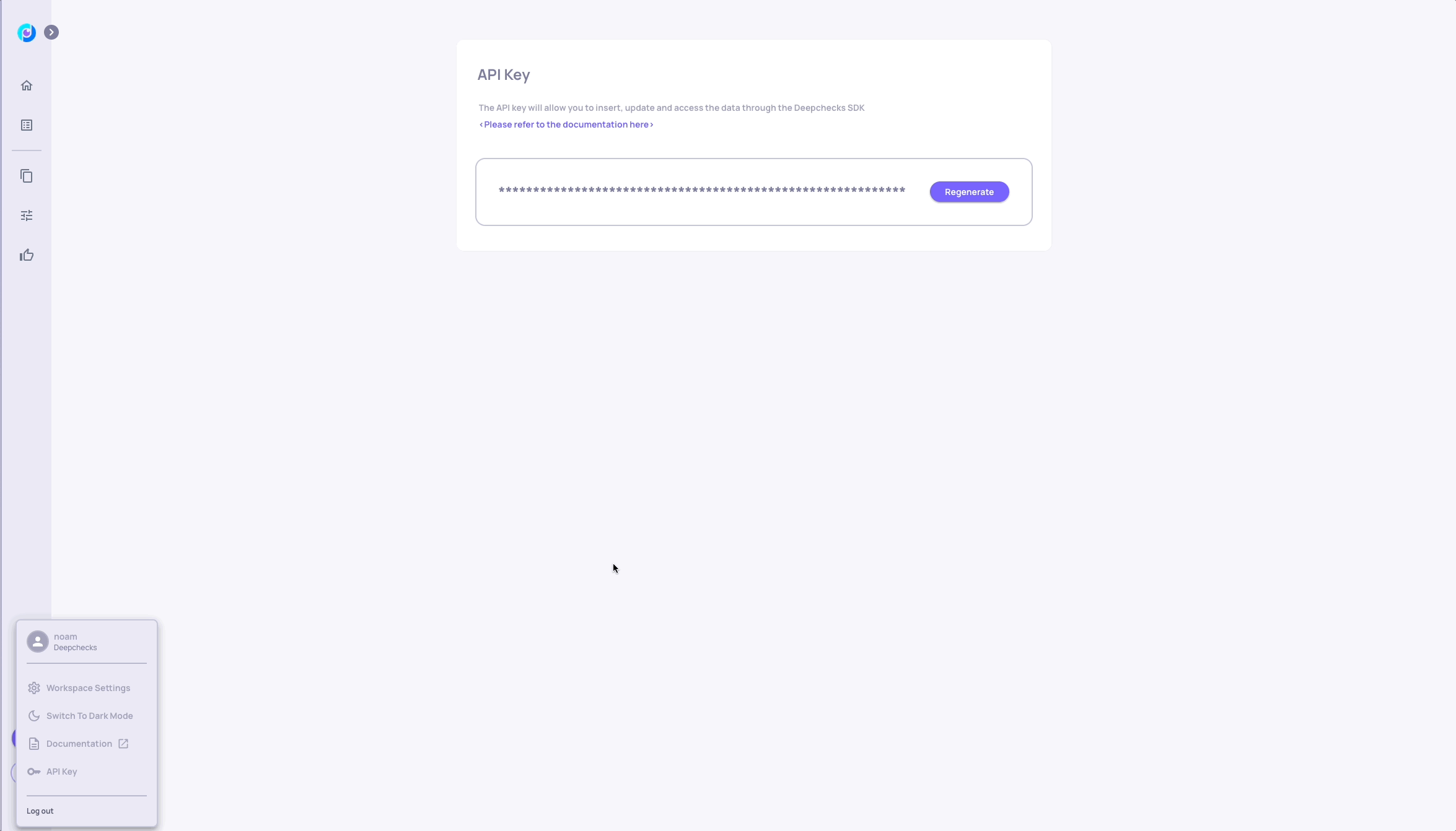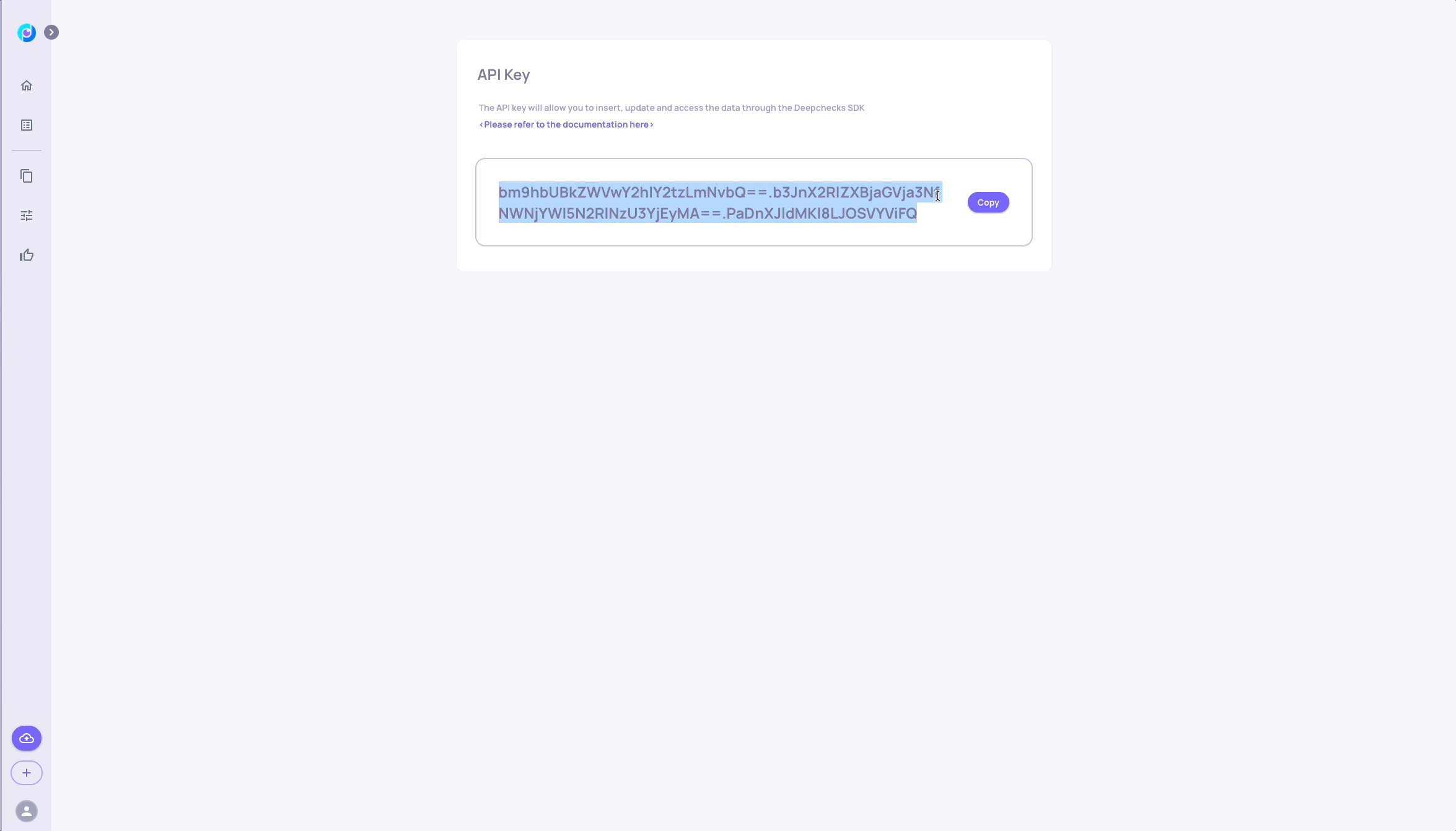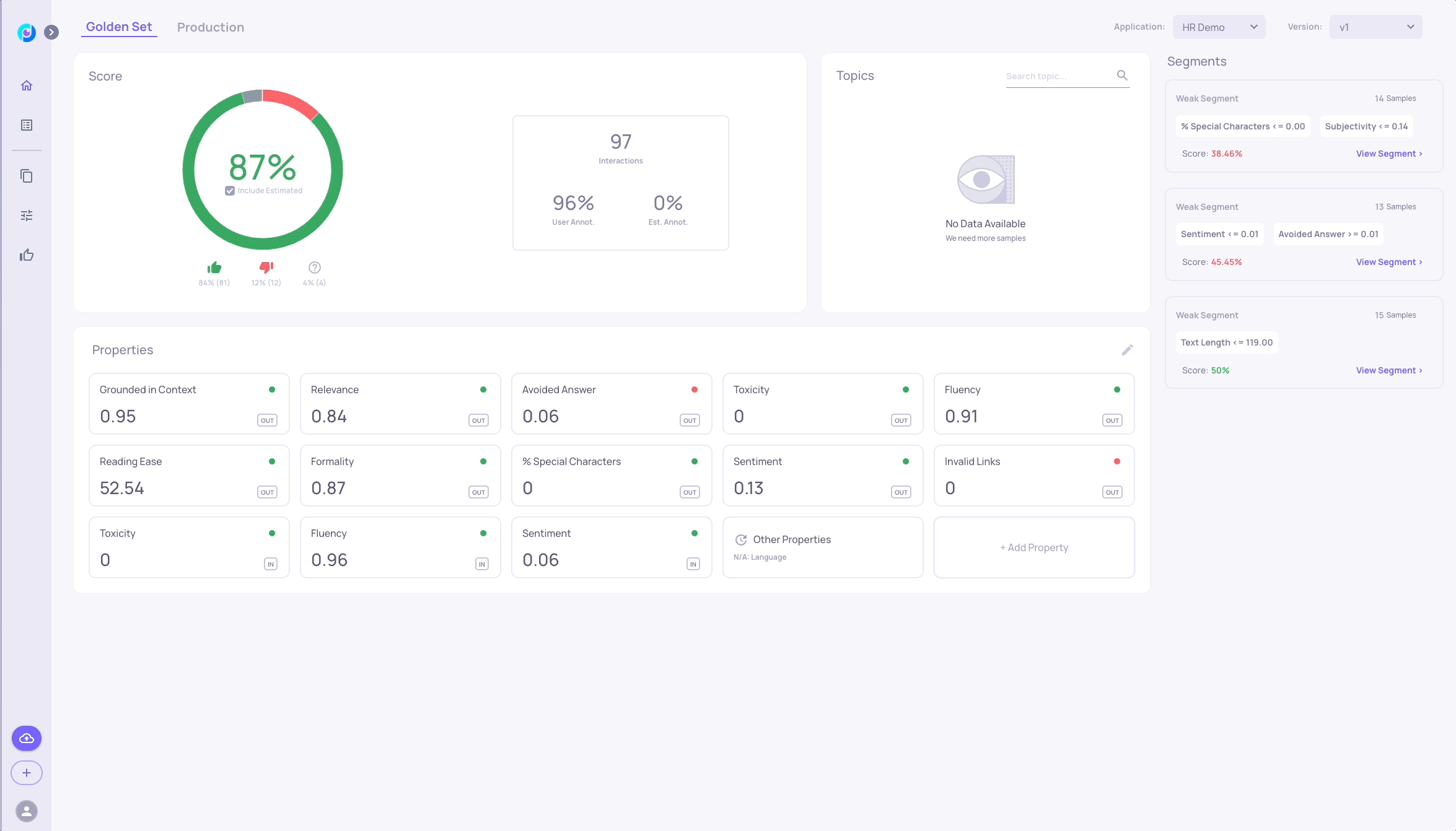
Initialize the Deepchecks Client and Upload the Data
from deepchecks_llm_client.client import dc_client
from deepchecks_llm_client.data_types import EnvType, AnnotationType, LogInteractionType
dc_client.init(host="https://app.llm.deepchecks.com", api_token=DC_API_KEY,
app_name=APP_NAME, version_name=BASE_VERSION,
env_type=EnvType.EVAL, auto_collect=False)Upload the baseline version
import pandas as pd
df = pd.read_csv("baseline_data.csv")
dc_client.log_batch_interactions(
interactions=[
LogInteractionType(
input=row["input"],
information_retrieval=row["information_retrieval"],
output=row["output"],
annotation=AnnotationType.BAD if row["annotation"] == 'bad' \
else (AnnotationType.GOOD if row["annotation"]=='good' else None),
user_interaction_id=row["user_interaction_id"]
) for _, row in df.iterrows()
]
)Once we have a new version we would want to test it on our golden set. In order to do that we can use the get_data function to retrieve the golden set inputs and then run them in our new version's pipeline.
Upload a new version to evaluate
After we have defined our baseline version we will want to upload a version for evaluation.
We've changed the parameters for the information retrieval in this pipeline, and thus we're naming the new version 'v2-IR'
dc_client.version_name('v2-IR') # Set dc_client to upload to a new version
df = pd.read_csv("v2_new_ir_data.csv")
dc_client.log_batch_interactions(
interactions=[
LogInteractionType(
input=row["input"],
information_retrieval=row["information_retrieval"],
output=row["output"],
user_interaction_id=row['user_interaction_id']
) for _, row in df.iterrows()
]
)You are all set! You can now check out your data in theDeepchecks Application!
In the "Applications" page, you should now see the "GVHD" App.
Note: Data Processing statusSome properties take a few minutes to calculate, so some of the data - such as properties and estimated annotations will be updated over time. You'll see a "✅ Completed" Processing Status in the Applications page, when processing is finished. In addition, you can subscribe to notifications in the "Workspace Settings", to get notified by email upon processing completion.
Updated 6 months ago